
Маркетплейс во время распродажи обычно ломается не “из-за одного сервера”. Чаще узкое место появляется в архитектурном слое: база данных исчерпывает соединения, поиск не выдерживает фильтры, платёжный API отвечает медленно, кэш не прогрет, очередь копит задачи, а лимиты облачного аккаунта нельзя поднять за несколько минут.
Автомасштабирование backend-сервисов полезно, но оно не гарантирует устойчивость. Если приложение масштабируется быстрее, чем база, поиск, внешние API и очереди, пик просто переносится ниже по цепочке.
Перед распродажей нужно проверить не только количество серверов, а всю инфраструктурную связку:
- Что отдаёт CDN и где начинается динамика корзины, заказа и оплаты;
- Какие данные можно кэшировать без риска для цены, остатков и персонализации;
- Какие операции остаются синхронными, а какие уходят в очередь;
- Выдерживают ли база данных, поиск и внешние API рост чтения, записи и задержек;
- Готовы ли лимиты, индексы, реплики, алерты, обработчики очередей и сценарии деградации.
Главная мысль: готовность к пику — это не “добавим серверов перед стартом”, а заранее проверенная цепочка. CDN снижает входящий поток, кэш разгружает чтение, очередь сглаживает фоновые операции, а база данных, поиск, внешние API и мониторинг задают реальные пределы платформы.
Пик нагрузки — это проверка всей инфраструктуры

На старте распродажи маркетплейс редко выходит из строя из-за одного конкретного сервера. Чаще система упирается в слой, который заранее не считали критичным: база данных исчерпала соединения, поиск не выдержал фильтры, платёжный API начал отвечать с задержкой, кэш не прогрелся, очередь накопила задачи, а лимиты облачного аккаунта нельзя поднять за несколько минут.
Маркетплейс сложнее обычного интернет-магазина. Здесь больше продавцов, карточек, остатков, ценовых правил, интеграций со складами, ERP/WMS-системами, доставкой, платёжными сервисами и уведомлениями. Каждый пользовательский сценарий проходит через несколько слоёв, и слабое звено может обнулить запас мощности в соседних компонентах.
Поэтому перед распродажей нужно обсуждать не только “сколько серверов добавим”. Важнее понять, как ведёт себя вся цепочка: входной слой, CDN, WAF, backend, кэш, база данных, поиск, очереди, внешние интеграции и мониторинг.
Дальше разберём инфраструктуру маркетплейса по маршрутам: что происходит в синхронном пути пользователя, что уходит в асинхронный контур, как оценивать пик и какие слои нельзя масштабировать в последний момент.
Базовая схема инфраструктуры маркетплейса
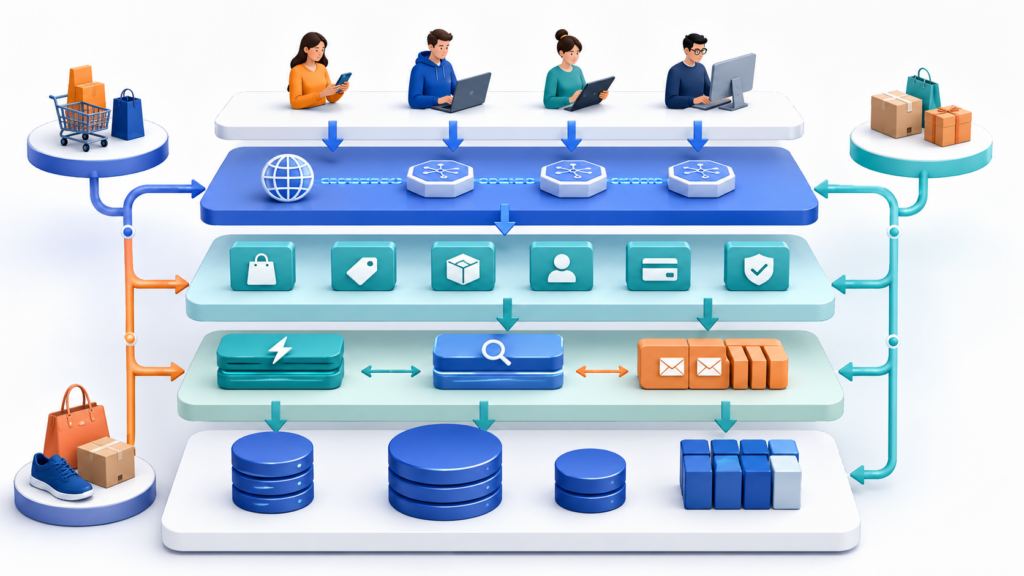
Оценку готовности к пику удобнее рассматривать не через список сервисов, а как два маршрута: что пользователь ждёт сразу и что можно выполнить фоном. Это помогает отделить критический путь заказа от служебных операций, которые не должны блокировать экран покупателя.
Синхронный путь: что пользователь ждёт сразу
Пользователь → CDN/WAF → балансировщик или API-шлюз → backend-сервисы → кэш → БД / поиск / объектное хранилище → ответ пользователю
В этом пути находятся операции, от которых зависит ощущение “сайт работает”: открылась карточка, применился фильтр, обновилась корзина, создан заказ, пришёл ответ по оплате. Например, при просмотре карточки товара изображения можно отдать через CDN, часть данных взять из кэша, а актуальные параметры — из поиска или БД.
Создание заказа тоже частично остаётся в синхронном пути. Проверка состава корзины, цены, доступности товара и старт платежа должны пройти до ответа пользователю. Иначе покупатель увидит подтверждение, которое система ещё не может гарантировать.
Асинхронный контур: что можно выполнить фоном
Событие backend-сервиса → очередь или шина событий → обработчики фоновых задач → ERP/WMS / доставка / уведомления / аналитика / документы
Сюда лучше выносить то, что не обязано завершиться до ответа пользователю: отправку email, SMS и push, формирование документов, обмен с ERP/WMS, часть обновлений доставки, аналитику и вторичные статусы.
Такой контур снижает давление на критический путь. Пользователь получает понятный результат быстрее, а служебные операции выполняются с контролируемой скоростью. Но очередь не должна становиться “чёрной дырой”: нужно отслеживать возраст сообщений, ошибки, повторы и скорость обработки.
Отдельно нужен эксплуатационный слой: метрики, логи, трассировка, алерты и панели мониторинга. Без него команда может увидеть проблему слишком поздно — когда очередь уже накопилась, БД исчерпала соединения, а платёжный API начал массово тормозить.
Для заказчика такая схема — инструмент проверки. Вопросы должны касаться не только группы backend-серверов, но и входного слоя, кэша, БД, поиска, очередей, внешних интеграций и наблюдаемости. Одна масштабируемая группа приложений не спасёт платформу, если дальше запрос упирается в медленный поиск, перегруженную БД или зависшую очередь.
Что происходит с инфраструктурой во время распродажи

В момент старта распродажи маркетплейс получает не один “большой трафик”, а несколько разных потоков операций.
Витрина создаёт в основном чтение: главная, категории, карточки, изображения, цены, остатки, рекомендации. Поиск и фильтры добавляют тяжёлые выборки, сортировки и фасеты. Корзина и заказ дают запись, проверки и транзакции: нужно зафиксировать состав заказа, цену, доступность товара и старт оплаты. После этого появляются фоновые события: уведомления, документы, обновление статусов, синхронизация со складом, продавцами и доставкой.
Поэтому пик нельзя считать только по числу пользователей. Десять тысяч посетителей, которые смотрят баннер, и десять тысяч покупателей, одновременно применяющих фильтры, добавляющих товары в корзину и оплачивающих заказ, создают разные профили нагрузки.
Сжатая карта пика выглядит так:
| Слой | Что происходит во время распродажи | Что проверить заранее |
| CDN/WAF и входной слой | Растёт поток запросов, статики, медиа и подозрительной активности | TTL, правила кэша, защиту от ботов, rate limits, тайм-ауты |
| Backend и кэш | Динамические сценарии давят на сервисы, кэш снижает чтение из БД | Пулы соединений, прогрев кэша, инвалидацию, режимы деградации |
| База данных и поиск | Растут чтение, запись, фильтры, сортировки, блокировки и соединения | Индексы, планы запросов, реплики, лимиты соединений, задержки поиска |
| Очереди | Фоновые задачи накапливаются быстрее обычного | Скорость потребления, возраст сообщений, повторы, DLQ |
| Внешние API | Платежи, доставка, ERP/WMS и уведомления начинают отвечать медленнее | Тайм-ауты, лимиты, резервные сценарии, отдельные метрики |
| Наблюдаемость | Команда должна быстро понять, где началась деградация | Метрики по слоям, трассировку, алерты и бизнес-показатели |
Во время распродажи перегружается не один слой, а несколько связанных контуров. CDN снижает входящий поток, кэш разгружает чтение, очередь сглаживает фоновые операции, но БД, поиск, внешние API и мониторинг задают реальные границы устойчивости.
После такой карты можно переходить к расчёту пропускной способности: считать нужно не абстрактных “пользователей на сайте”, а конкретные бизнес-сценарии — просмотр, поиск, корзину, заказ, оплату и фоновые события.
Как оценивать пропускную способность перед пиком

Оценка пропускной способности не сводится к вопросу “сколько пользователей выдержит сайт”. Для маркетплейса полезнее считать не пользователей вообще, а конкретные бизнес-сценарии: просмотр витрины, поиск, открытие карточки, добавление в корзину, оформление заказа, оплату и фоновые события после заказа.
Минимальная методика такая:
- Разделить трафик на сценарии. Например: 60% пользователей смотрят каталог, 25% используют поиск, 10% добавляют товары в корзину, 5% доходят до оплаты. Доли лучше брать из аналитики, а не придумывать перед тестом.
- Перевести сценарии в запросы в секунду. Открытие карточки — это не один запрос, а цепочка обращений к приложению, кэшу, поиску, БД и объектному хранилищу.
- Учесть кэш-попадания и промахи. Если 90% карточек отдаются из кэша, БД получает один профиль нагрузки. Если кэш не прогрет, нагрузка резко меняется.
- Разделить чтение и запись. Витрина в основном читает, а корзина, заказ и оплата пишут и требуют транзакций.
- Проверить внешние ограничения. Платёжный сервис, ERP/WMS, доставка и уведомления могут иметь собственные лимиты.
- Сравнить поступление и обработку в очередях. Если задачи поступают быстрее, чем их забирают обработчики, очередь будет расти даже при нормальном интерфейсе.
Пример с условными числами: на пике ожидается 20 000 активных пользователей за минуту. Если 10% из них добавляют товар в корзину, это около 2 000 операций корзины в минуту, или примерно 33 операции в секунду. Если каждая операция создаёт 3 обращения к БД и 2 обращения к кэшу, слой данных получает около 100 обращений к БД в секунду только по корзине.
При падении доли попаданий в кэш нагрузка на БД может вырасти скачком, хотя число пользователей формально не изменилось. Поэтому нагрузочное тестирование должно моделировать реальные сценарии распродажи, а не абстрактный поток запросов. Иначе тест покажет, что backend выдержал, но не подсветит блокировки в БД, тяжёлые запросы от фильтров, растущий возраст сообщений в очереди или задержки платёжного API.
После расчёта сценариев стоит идти к первому участку маршрута: какие запросы можно остановить или обслужить ещё до того, как они попадут в бэкенд приложения.
CDN, WAF и входной слой: что можно остановить до приложения

Ошибка — сразу считать, сколько backend-серверов нужно добавить. Сначала нужно понять, какие запросы вообще не должны доходить до приложения, БД, поиска и сервисов заказов.
CDN полезна там, где контент публичный и предсказуемый: изображения товаров, CSS/JS, медиа, инструкции, документы, часть статичных блоков и публичных страниц. Для международной аудитории это снижает задержку и разгружает исходную инфраструктуру: пользователь получает файл с ближайшего узла, а backend не отвечает на каждый одинаковый запрос.
Граница CDN проходит там, где начинается персонализация и транзакционность. Корзина, оформление заказа, оплата, персональные цены, актуальные остатки и чувствительные данные не должны кэшироваться без строгих правил. Иначе пользователь может увидеть неверную цену, устаревший остаток или вообще чужие данные.
До приложения обычно можно остановить или обслужить:
- Статические ресурсы и медиа;
- Часть публичных страниц;
- Вредоносные запросы;
- Чрезмерно частые запросы;
- Некорректных клиентов и ботов.
WAF фильтрует типовые атаки, подозрительные параметры и часть бот-трафика. Rate limits защищают от парсинга, перебора, агрессивных интеграций и ошибочных клиентов, которые могут создать нагрузку не хуже реальных покупателей.
Поэтому перед распродажей важно проверять не только “мощность серверов”, а правила кэширования, лимиты, защиту от ботов, тайм-ауты и поведение API-шлюза. Но даже хороший входной слой не остановит всю динамику: карточки с актуальной ценой, корзина и заказ всё равно попадут внутрь платформы. Следующий слой — backend и кэш.
Backend и кэш: как разгрузить чтение

После CDN и WAF внутрь проходит динамика: карточка с актуальной ценой, корзина, проверка остатка, оформление заказа и платёжный сценарий. Backend-сервисы должны быть без локального состояния: сессии, токены, корзины и промежуточные данные нельзя держать в памяти одного экземпляра. Тогда экземпляры можно добавлять и убирать без привязки покупателя к конкретному серверу.
Но простое увеличение числа экземпляров не всегда помогает. Если каждый новый экземпляр открывает дополнительные соединения к БД, пик опять же можно лишь перенести ниже по цепочке. Поэтому состояние выносят во внешнее хранилище, кэш или БД, а доступ к данным ограничивают пулами соединений, тайм-аутами и правилами деградации.
Кэш снижает нагрузку на чтение, когда данные часто запрашиваются и допускают контролируемую актуальность:
| Можно кэшировать спокойнее | Нужны строгие правила |
| Карточки товаров без финальной персональной цены | Персональные цены и скидки |
| Категории, справочники, настройки витрины | Остатки перед заказом |
| Часто читаемые агрегаты и публичные блоки | Корзина и данные пользователя |
| Часть неперсонализированных результатов выдачи | Платёжные и транзакционные состояния |
Для рискованных данных важны короткий срок жизни записи, инвалидация устаревших значений, защита от лавины запросов к БД при массовом промахе и резервное поведение при отказе кэша.
Кэш снижает количество чтений, но не отменяет транзакционную нагрузку, соединения, блокировки и медленные запросы. Неправильный кэш способен ускорить ошибку: показать устаревшую цену, продать отсутствующий товар или подмешать персональные данные не тому пользователю. Поэтому оценивать нужно не только скорость ответа, но и правила корректности данных.
После backend и кэша следующий критичный слой — база данных. Именно там сходятся заказы, корзины, цены, остатки, статусы и транзакции, которые нельзя просто “размазать” по кэшу или очереди.
База данных: транзакции, соединения и блокировки

База данных остаётся центральным слоем маркетплейса. В ней фиксируются заказы, платёжные состояния, остатки, цены, корзины, статусы и связи между продавцами, товарами и покупателями. Витрину можно частично ускорить кэшем и CDN, но создание заказа всё равно требует согласованности: нельзя подтвердить покупку по неверной цене или продать товар, которого уже нет.
Во время распродажи БД получает давление сразу с нескольких сторон:
- Растёт чтение по карточкам, остаткам, ценам и корзинам;
- Растёт запись при добавлении в корзину, создании заказа и смене статусов;
- Увеличивается число соединений от масштабируемых backend-сервисов;
- Появляются блокировки при обновлении остатков и фиксации заказа;
- Медленные запросы становятся заметнее из-за частого повторения;
- Реплики чтения могут начать отставать от основной базы.
Реплики помогают только там, где допустима задержка репликации. Каталог, справочники и часть аналитических данных можно читать с реплик. Но проверку остатка перед заказом, фиксацию цены и запись транзакции нельзя бездумно уводить на источник, который может отставать.
Индексы тоже нельзя считать мелкой оптимизацией. Во время пика плохой индекс превращает частый запрос в массовое сканирование таблицы. Особенно опасны запросы по корзинам, заказам, остаткам, продавцам, статусам и временным диапазонам. Проверять нужно не только наличие индексов, но и планы выполнения запросов на объёме данных, близком к реальному.
Отдельный риск — соединения. Если число экземпляров приложения выросло в три раза, а каждый экземпляр держит большой пул соединений, БД может исчерпать лимит раньше, чем закончится процессор или память. Поэтому нужны ограниченные пулы, прокси для соединений там, где он уместен, тайм-ауты и отказ от бесконечных повторов.
Связь БД с кэшем и очередями должна быть явной. Кэш разгружает чтение, но не должен скрывать проблему с корректностью данных. Очереди выносят фоновые действия, но не должны превращать критичную транзакцию заказа в неуправляемую отложенную запись. Минимальная фиксация заказа и платёжного состояния проходит синхронно, а уведомления, документы, интеграции и вторичные обновления уходят в асинхронный контур.
Поиск: отдельный потолок витрины

Поиск в маркетплейсе — это не просто чтение карточек. Он обслуживает фильтры, сортировки, полнотекстовые запросы, фасеты, цены, бренды, категории, доступность и региональные условия.
Если выполнять такие запросы в основной транзакционной БД, витрина начинает конкурировать с заказами и платежами. Поэтому поиск обычно выносят в отдельный сервис или кластер, а данные для него обновляют из основного контура через события, выгрузки или процессы индексации.
Перед распродажей нужно проверить:
- Готовы ли индексы под популярные фильтры;
- Не становятся ли сортировки дорогими на больших выборках;
- Как быстро в поиск попадают новые цены и остатки;
- Как ведут себя фасеты и фильтры при одновременном пике запросов;
- Нет ли конфликта между скоростью выдачи и актуальностью коммерческих данных.
Кэш может помочь с популярными категориями и частыми запросами, но он не заменяет настройку поиска. Тестировать нужно именно сценарии распродажи: страницы акций, фильтры по скидкам, сортировку по цене, наличие в регионе и быстрые переходы из рассылок.
Если поиск держит витрину, следующий слой защищает уже не чтение, а фоновые операции после действия пользователя. Здесь появляются очереди.
Очереди: как сглаживать пики и защищать зависимые сервисы

Очередь нужна там, где операцию можно выполнить не в момент ответа пользователю. Она принимает задачи и события, сохраняет их до обработки и позволяет обработчикам работать в своём темпе. Для маркетплейса это критично: не каждое действие после заказа должно блокировать экран подтверждения покупки.
Что можно отправлять в очередь
В очередь обычно выносят:
- Отправку email, SMS и push-уведомлений;
- Формирование документов;
- Синхронизацию с ERP/WMS и продавцами;
- Обновление статусов доставки;
- Отправку событий в аналитику;
- Повторную обработку платёжных и логистических статусов;
- Вторичные обновления витрины и индексов, если они допускают задержку.
Главная роль очереди — сгладить пик. Если за минуту создано много заказов, платформа не обязана одновременно отправить все уведомления, документы и внешние запросы. Она может зафиксировать критичное состояние, положить фоновые задачи в очередь и обработать их с контролируемой скоростью. Так очередь защищает БД, внешние API и сервисы уведомлений от резкого всплеска.
Что контролировать во время пика

Очередь не должна становиться способом спрятать проблему. Если задачи поступают быстрее, чем обрабатываются, растёт не только размер очереди, но и возраст сообщений. Пользователь уже может получить подтверждение заказа, а складская система, доставка или уведомления будут отставать на десятки минут.
Во время пика стоит смотреть не только на размер очереди:
| Метрика | Что показывает |
| Скорость поступления задач | Насколько быстро сервисы создают новые события |
| Скорость обработки | Успевают ли обработчики разбирать поток задач |
| Возраст самого старого сообщения | Как сильно фоновые процессы отстают от реального времени |
| Число повторов | Есть ли проблемы с внешними API, обработчиками или данными |
| Доля ошибок | Сколько задач не обрабатывается штатно |
| Размер DLQ | Сколько сообщений ушло в очередь ошибок и требует разбора |
Если размер очереди растёт, но возраст сообщений остаётся низким, система может просто переживать краткий всплеск. А вот рост возраста старых сообщений означает, что обработка уже не успевает за нагрузкой, и фоновые процессы начинают отставать от бизнеса.
Когда очередь отстаёт, следующая проблема почти всегда появляется на повторах. Обработчики заново отправляют запросы во внешние API, пересоздают документы, обновляют статусы или синхронизируют данные. Без ограничений и идемпотентности такие повторы могут не восстановить систему, а усилить сбой.
Почему важны повторы и идемпотентность
Повторы должны быть ограничены. Если внешний API временно недоступен, бесконечные повторные запросы могут усилить аварию. Нужны паузы между попытками, лимит повторов и отдельная очередь ошибок.
Ещё одно обязательное требование — идемпотентность. Повторная обработка одного сообщения не должна создавать два заказа, два списания, два документа или два противоречивых статуса доставки. Для этого используют уникальные идентификаторы операций, проверку уже выполненных действий и безопасные повторные вызовы.
Для заказчика главный вопрос такой: асинхронный контур должен быть управляемой частью системы, а не складом задач “на потом”. Должно быть понятно, что можно отправлять в очередь, что остаётся синхронным, как масштабируются обработчики, как работает DLQ и кто разбирает накопившиеся сообщения после сбоя.
Внешние API и наблюдаемость

Маркетплейс зависит от внешних систем: платежей, доставки, ERP/WMS, продавцов, сервисов уведомлений, антифрода и аналитики. Даже если собственная облачная инфраструктура масштабируется корректно, чужой API может иметь лимит, задержку, окно обслуживания или нестабильный ответ во время распродажи.
Как ограничивать внешние зависимости
Для интеграций нужны не только рабочие ключи доступа, но и правила поведения при задержках и ошибках:
- Тайм-ауты на каждый внешний вызов;
- Ограничение числа параллельных запросов;
- Повторные попытки с паузой, а не непрерывным циклом;
- Очередь для операций, которые можно отложить;
- Резервные сценарии для некритичных функций;
- Отдельные метрики по задержкам и ошибкам каждого поставщика.
Критичные платёжные операции нужно проектировать особенно осторожно. Пользователь должен получить понятный статус: оплата принята, отклонена, ожидает подтверждения или требует повторной проверки. Если платёжный сервис отвечает медленно, система не должна бесконечно удерживать соединение и блокировать ресурсы. Часть статусов может приходить асинхронно, но это должно быть учтено в модели заказа.
Что должно быть видно во время распродажи
Наблюдаемость связывает все слои в управляемую систему. Во время распродажи мало знать, что “ошибок стало больше”. Нужно видеть, где началась деградация: CDN, API-шлюз, приложение, кэш, БД, поиск, очередь, обработчики или внешний поставщик.
Для этого нужны метрики, логи, трассировка запросов, алерты и панели, которые показывают не только инфраструктуру, но и бизнес-показатели:
- Созданные заказы;
- Ошибки оплаты;
- Задержки поиска;
- Процент промахов кэша;
- Число соединений к БД;
- Возраст сообщений в очереди;
- Ошибки и задержки внешних API.
Это зона проверки операционной зрелости. Если команда не может заранее показать, какие метрики будет смотреть в первые минуты распродажи и кто принимает решение о деградации функций, инфраструктурная мощность сама по себе не гарантирует сохранение заказов.
После этого остаётся финальный практический вопрос: какие слои можно усилить перед стартом быстро, а какие должны быть подготовлены заранее.
Что нельзя масштабировать в последний момент

К пику можно добавить часть вычислительных ресурсов, но не все ограничения поддаются срочному расширению. Некоторые компоненты требуют проектирования, тестирования, согласования лимитов и прогрева заранее.
| Слой | Почему нельзя оставить на последний момент |
| Лимиты облачного аккаунта и региона | Их нужно согласовывать заранее; во время распродажи лимит может не подняться быстро |
| База данных, индексы и реплики | Требуют тестов, настройки запросов, прогрева и проверки схемы соединений |
| Поиск и фильтры каталога | Тяжёлые фильтры и сортировки нужно проверять на реальном объёме данных |
| Кэш | Нужны правила TTL, прогрев, инвалидация и защита от массовых промахов |
| Очереди и обработчики | Важны скорость обработки, повторы, DLQ и сценарии разбора накопленных задач |
| Платежи, ERP/WMS, доставка | У внешних поставщиков есть свои лимиты, окна поддержки и задержки |
| Object storage и CDN | Массовая отдача медиа требует правил кэша, лимитов и проверки связки с CDN |
| Мониторинг и алерты | Их нельзя “включить по ходу”, если заранее не понятно, какие метрики важны |
| Нагрузочные сценарии | Тест должен повторять поведение покупателей, а не абстрактный поток запросов |
Эта таблица полезна как критерий закупки или выбора архитектурного решения. Если поставщик обещает “добавить мощности перед стартом”, нужно уточнять, какие именно слои он сможет масштабировать быстро, а какие уже должны быть подготовлены.
Заключение

Устойчивость маркетплейса во время распродажи определяется не количеством backend-серверов, а пропускной способностью всей цепочки. CDN снижает входящий поток, кэш разгружает чтение, очередь выносит фоновые операции из пользовательского пути, а база данных, поиск и внешние API задают реальные пределы системы.
Главный вопрос к подрядчику или облачной команде должен звучать не “сколько серверов добавим”, а “какие слои уже проверены под пиковый сценарий”. До распродажи должны быть понятны лимиты, индексы, пулы соединений, правила кэширования, скорость обработки очередей, поведение при отказах и метрики деградации.
Готовность к пику — это не разовое увеличение мощности, а заранее проверенная архитектура, где каждый слой имеет свою роль, пределы и план деградации.
FAQ
Почему автоскейлинг backend не гарантирует устойчивость маркетплейса?
Потому что приложение масштабируется быстрее, чем база данных, поиск, внешние API и очереди. Если добавить больше экземпляров сервиса заказов, они могут открыть больше соединений к БД или чаще обращаться к платёжному API. В результате узкое место сместится ниже по цепочке, а не исчезнет.
Какие данные можно кэшировать в маркетплейсе?
Обычно кэшируют публичные и часто читаемые данные: карточки товаров без финальной персональной цены, категории, справочники, статичные блоки, часть популярных выдач и агрегатов. Осторожность нужна с ценами, остатками, корзиной, персональными скидками и пользовательскими данными. Для них требуются короткие сроки жизни, инвалидация и проверка корректности перед заказом.
Что должно оставаться синхронным при оформлении заказа?
Синхронно должны выполняться операции, без которых нельзя дать покупателю корректный результат: проверка состава корзины, цены, доступности товара, создание заказа и старт или подтверждение платежа. Уведомления, документы, аналитика, часть обновлений доставки и интеграций могут уходить в очередь, если бизнес допускает задержку.
Какие метрики важны во время распродажи?
Нужно смотреть не только загрузку процессора и памяти. Критичны задержки API, доля ошибок, процент кэш-попаданий, число соединений к БД, блокировки, задержка реплик, время ответа поиска, длина и возраст очередей, ошибки внешних API, успешные заказы и ошибки оплаты. Эти метрики должны быть видны по слоям, иначе причину деградации сложно найти вовремя.
Список источников
1. Microsoft Azure Architecture Center — Queue-Based Load Leveling pattern
2. Microsoft Azure Architecture Center — Caching guidance
3. Cloudflare Docs — Rate limiting rules
4. Google Cloud Architecture Center — Patterns for scalable and resilient apps


