
Managed Kubernetes и Managed VM нельзя сравнивать только по цене инстанса или рабочего узла. Реальная разница в том, кто эксплуатирует платформу, кто отвечает за обновления, как устроены релизы, сколько стоит инцидент и насколько приложение завязано на API конкретного облака.
Managed VM обычно проще для стабильных приложений, монолитов, унаследованных систем и команд, которым привычна модель “сервер → ОС → приложение”. В этой модели провайдер может брать на себя администрирование гостевой ОС, базовые обновления, настройку middleware, мониторинг и часть типовых эксплуатационных задач. Но объём ответственности провайдера зависит от SLA и состава managed-услуги: приложение, бизнес-логика, релизы, архитектурные решения и часть контроля безопасности всё равно остаются на стороне команды.
Managed Kubernetes оправдан, когда сервисов много, релизы частые, команда уже работает с контейнерами, CI/CD и декларативной инфраструктурой. Он помогает стандартизировать деплой, масштабирование и окружения, но добавляет сложность в сетях, хранилищах, RBAC, ingress, observability, обновлениях и troubleshooting.
Управляемый сервис экономит время только тогда, когда снимает с команды операции, которые она понимает и может контролировать. Но тот же слой удобства может создать lock-in: через IAM, балансировщики, диски, storage classes, managed ingress, мониторинг, бэкапы, тарифы на трафик и API провайдера.
Практический выбор держится на пяти вопросах:
- Что дешевле в эксплуатации с учётом времени DevOps/SRE, а не только счётов облака;
- Какие компетенции уже есть у команды;
- Что реально переносимо между облаками;
- Как устроены мониторинг, обновления и безопасность;
- Где приложение начинает зависеть от API провайдера.
Главный вывод: выбирать нужно не “современную” или “старую” платформу, а операционную модель. Managed VM и Managed Kubernetes экономят время в разных сценариях и создают lock-in в разных местах.
Почему сравнение начинается не с цены инстанса

Сравнение Managed Kubernetes и Managed VM часто начинают с цены инстанса или рабочего узла. Это удобно, но неполно. В счёте облака видны вычислительные ресурсы, но не всегда видны обновления, диагностика, инциденты, дежурства, сложность релизов и стоимость будущей миграции.
Управляемый сервис экономит время, когда снимает с команды повторяемые операции. В Managed Kubernetes это может быть обслуживание control plane, стандартизация деплоя, интеграции с сетью и хранилищем, часть обновлений и масштабирование. В Managed VM — администрирование гостевой ОС, базовые патчи, настройка middleware, мониторинг, бэкапы и типовые эксплуатационные задачи в пределах SLA. Но тот же слой удобства может стать источником зависимости от особенностей провайдера: IAM-модели, балансировщиков, дисков, managed-дополнений, мониторинга, тарифов на трафик, форматов резервного копирования и регламентов поддержки.
Поэтому сначала нужно зафиксировать границы ответственности: что берёт на себя провайдер, а что остаётся команде. Без этого расчёт стоимости, оценка рисков и финальный выбор быстро превращаются в спор “Kubernetes или VM”, хотя на самом деле вопрос шире: какая операционная модель подходит продукту и команде.
Что означает managed в Kubernetes и VM
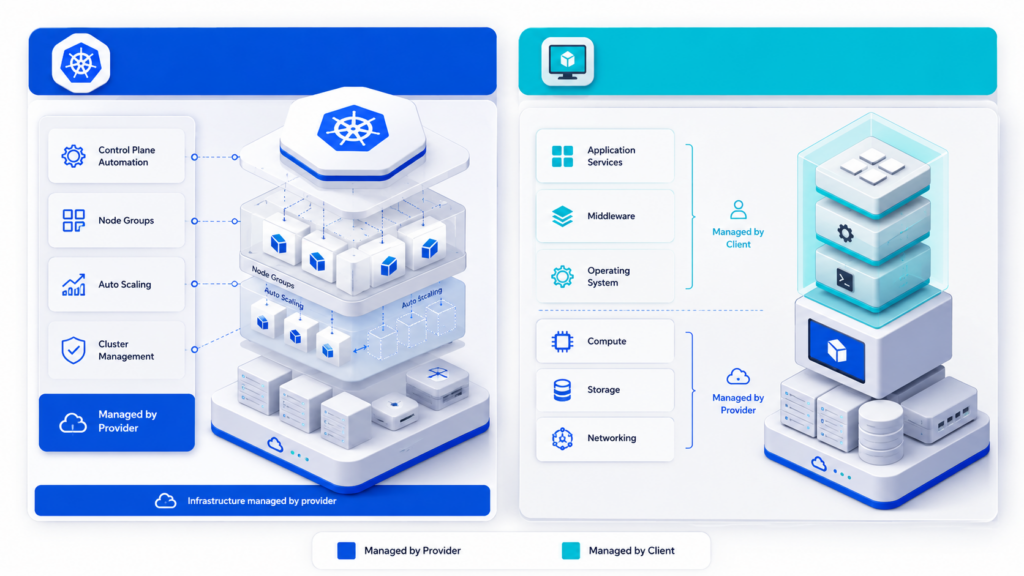
В Managed VM и Managed Kubernetes слово managed не означает, что провайдер управляет всем. Оно означает другое распределение ответственности между облачным провайдером и командой клиента. Главное — заранее понять, какие уровни входят в managed-услугу, а какие остаются на стороне команды.
В Managed VM провайдер обычно отвечает не только за физические серверы, гипервизор, базовую сеть и доступность платформы виртуализации, как при классической IaaS-модели (VDS/VPS) но и за часть администрирования гостевой ОС и middleware. В зависимости от SLA и состава услуги это может включать установку обновлений безопасности, базовую настройку ОС, веб-сервера, runtime-среды, агентов мониторинга, резервного копирования и типовых эксплуатационных процедур.
Но Managed VM не превращает провайдера во владельца приложения. Клиент по-прежнему отвечает за бизнес-логику, релизы, архитектурные решения, данные, прикладные зависимости, требования к безопасности и корректность работы сервиса. Если приложение падает из-за ошибки в коде, неверной миграции базы или неправильной бизнес-логики, это как правило не решается одной только managed-услугой и требует дополнительного привлечения специалистов - команды, или провайдера.
В Managed Kubernetes граница проходит иначе. Провайдер берёт на себя плоскость управления Kubernetes: её доступность, часть обновлений и базовую интеграцию с облачной сетью. Но прикладная нагрузка остаётся зоной клиента: рабочие узлы, контейнерные образы, requests/limits, RBAC, сетевые политики, ingress, диски, дополнения, мониторинг и безопасность приложений требуют отдельной эксплуатации.
Практически это выглядит так: в Managed VM провайдер может поставить патчи ОС, помочь с базовой настройкой middleware, следить за частью системных метрик и выполнять типовые операции по регламенту. Но он не перепишет приложение, не исправит ошибочный релиз и не примет архитектурное решение за продуктовую команду. В Managed Kubernetes провайдер обеспечит работу control plane, но не исправит уязвимый контейнерный образ, ошибочную роль доступа или сетевую политику, которая отрезала сервис от зависимостей.
Границы ответственности удобно разделить так:
| Уровень | Managed Kubernetes | Managed VM |
| Физическая инфраструктура | Провайдер | Провайдер |
| Платформа управления | Провайдер ведёт control plane Kubernetes | Провайдер ведёт платформу виртуализации |
| Узлы / серверы | Клиент управляет пулами рабочих узлов и их параметрами, если иное не покрыто сервисом | Провайдер может администрировать VM на уровне ОС в пределах SLA |
| ОС и системные пакеты | Зависит от типа узлов и политики обновлений | Провайдер может устанавливать патчи ОС и системных пакетов по регламенту |
| Middleware | Клиент отвечает за ingress-контроллеры, runtime, sidecar-компоненты и зависимости | Провайдер может настраивать и обновлять nginx, runtime, агенты и базовые службы, если это входит в услугу |
| Приложения | Клиент отвечает за контейнеры, манифесты, зависимости и релизы | Клиент отвечает за код, бизнес-логику, релизы, данные и прикладные зависимости |
| Доступы и политики | Клиент: RBAC, IAM-интеграции, сетевые политики, секреты | Совместная зона: провайдер может вести системные доступы, клиент отвечает за прикладные роли и требования безопасности |
| Мониторинг и обновления | Провайдер покрывает часть платформы, клиент — приложения, узлы и дополнения | Провайдер может покрывать системный мониторинг, патчи и типовые реакции; клиент отвечает за прикладные метрики и бизнес-сценарии |
Managed Kubernetes переносит часть сложности в платформенный слой, но требует компетенций в оркестрации, политиках и контейнерной эксплуатации. Managed VM проще концептуально и ближе к модели “сервер → ОС → приложение”, но экономия времени зависит от того, что именно провайдер берёт на себя по SLA: только базовое администрирование ОС или также middleware, мониторинг, бэкапы и реакцию на инциденты.
После границ ответственности можно переходить к стоимости. Сравнивать только цену VM или рабочего узла недостаточно: в реальную стоимость входят сеть, диски, балансировщики, мониторинг, обновления, SLA провайдера и время команды.
Стоимость эксплуатации: считать нужно не только VM и рабочие узлы
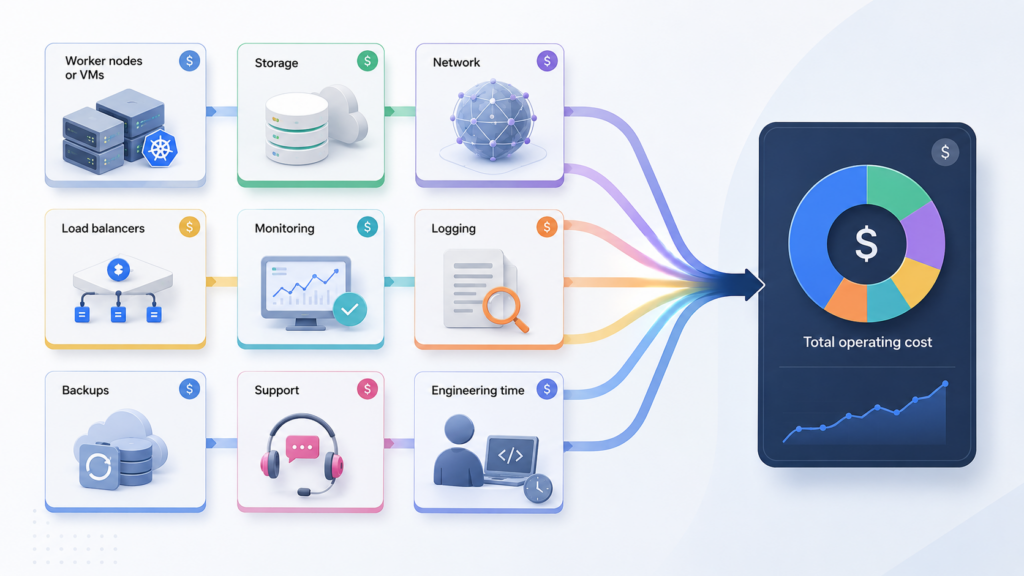
После запуска появляются расходы, которых не видно в простом сравнении “VM стоит X, рабочий узел Kubernetes стоит Y”. В реальную стоимость входят балансировщики, диски, NAT, публичные IP, межзональный и исходящий трафик, мониторинг, логи, резервное копирование, поддержка провайдера и время команды.
В Managed Kubernetes расходы часто распределены по нескольким слоям: плата за кластер, рабочие узлы, ingress-балансировщики, диски для stateful-нагрузок, NAT для приватных подсетей, хранение логов и метрик. В Managed VM часть инфраструктурных затрат тоже остаётся: инстансы, диски, сеть, публичные IP, бэкапы и мониторинг. Но к ним добавляется стоимость администрирования на стороне провайдера: SLA, обновления ОС, поддержка middleware, базовая диагностика, регламентные работы и реакция на типовые инциденты.
Сравнивать платформы удобнее не по одной строке прайса, а по полной модели затрат:
| Статья расходов | Managed Kubernetes | Managed VM |
| Вычисления | Рабочие узлы, часто с резервом под планировщик | Инстансы под приложения |
| Платформа | Возможна отдельная плата за кластер | Платформа виртуализации входит в услугу провайдера |
| Managed-администрирование | Часть платформы управляется провайдером, но workload остаётся на клиенте | Администрирование ОС, middleware, обновлений и базовых процедур может входить в SLA |
| Сеть | Ingress, балансировщики, NAT, межзональный трафик | Балансировщики, правила сети, публичные IP |
| Хранилище | Persistent volumes, storage classes, снапшоты | Диски VM, сетевые диски, снапшоты |
| Мониторинг и логи | Контейнеры, узлы, события кластера, control plane | ОС, middleware, приложения, агенты, SLA по реакции |
| Время команды | Меньше рутины при зрелой платформе, но сложнее диагностика | Меньше системного администрирования, но нужна работа с приложением, релизами и границами ответственности |
Из такой модели видно, что “дороже” или “дешевле” зависит не только от цены инстанса. Небольшая и стабильная нагрузка часто лучше укладывается в Managed VM: команда сохраняет понятную модель “сервер → ОС → приложение”, а часть регулярного администрирования передаёт провайдеру. Managed Kubernetes начинает окупаться там, где много сервисов, частые релизы, нужна унификация окружений и автоматическое управление размещением нагрузки.
Условный расчёт помогает проверить экономику. Если три VM требуют регулярных патчей, бэкапов, настройки middleware и диагностики, то в обычной VM-модели это превращается во внутренние часы команды. В Managed VM часть этих часов заменяется платой за managed-услугу. Поэтому сравнивать нужно не “стоимость VM против стоимости Kubernetes”, а “стоимость VM + managed SLA + оставшееся время команды” против “стоимости Kubernetes + инфраструктурные компоненты + время команды на платформенную эксплуатацию”.
Например, если managed-администрирование VM стоит дороже базовой VM, но снимает 15–20 часов системной рутины в месяц, это может быть выгоднее для небольшой команды. Но если приложение требует частых релизов, сложного масштабирования, множества окружений и унифицированного деплоя, Kubernetes может оказаться экономически разумнее даже при большей платформенной сложности.
Поэтому после расчёта денег нужно смотреть на компетенции. Одна и та же managed-платформа может ускорить зрелую команду и замедлить команду, которая впервые сталкивается с её абстракциями, неправильно понимает границы ответственности провайдера или требуются нетиповые решения от провайдера.
Компетенции команды: где managed экономит время, а где создаёт новый порог входа

После расчёта стоимости нужно оценить не только деньги, но и навыки команды. “Время DevOps/SRE” — это не абстрактные часы, а конкретные компетенции, от которых зависит, станет managed-сервис ускорителем или новым источником инцидентов.
Команда, которой привычна модель “сервер → ОС → приложение”, часто быстрее и безопаснее запустит Managed VM. Провайдер может взять на себя администрирование ОС, базовые обновления, часть middleware, мониторинг и типовые эксплуатационные операции. Это снижает требования к глубокой системной эксплуатации внутри команды, особенно для монолита, унаследованной нагрузки или умеренного числа релизов.
Но Managed VM не отменяет инженерные компетенции полностью. Команда всё равно должна понимать архитектуру приложения, релизный процесс, зависимости, требования к безопасности, работу с логами, порядок эскалации и границы SLA. Если неясно, кто отвечает за обновление middleware, восстановление после сбоя, изменение конфигурации nginx или реакцию на алерт, managed-услуга может не ускорить работу, а создать новую зону неопределённости.
Обратная ситуация — команда уже использует контейнеры, CI/CD, инфраструктуру как код, SRE-практики и умеет описывать окружения декларативно. Для неё Managed Kubernetes может снизить рутину: стандартизировать деплой, упростить откаты, дать пространства имён, автоматическое восстановление и единую модель окружений.
Критичные навыки различаются:
- Managed VM — понимание модели “ОС → middleware → приложение”, работа с SLA провайдера, постановка задач на администрирование, анализ логов, контроль релизов, требования к безопасности, проверка бэкапов, эскалация инцидентов и автоматизация там, где зона ответственности остаётся у команды;
- Managed Kubernetes — контейнерные образы, манифесты, Helm/Kustomize, GitOps, RBAC, IAM-интеграции, сетевые политики, storage classes, ingress, requests/limits, автомасштабирование и диагностика кластера.
Один и тот же управляемый сервис может быть ускорителем для зрелой команды и риском для команды, которая впервые сталкивается с его абстракциями. В Managed VM риск часто появляется из-за неверно понятых границ ответственности: команда считает, что провайдер “ведёт всё”, а в SLA не входят прикладные релизы, бизнес-метрики или конкретный сценарий восстановления. В Managed Kubernetes ошибки в лимитах ресурсов, ролях доступа или сетевых политиках способны ухудшить SLA не меньше, чем неудачный релиз в VM-модели.
После компетенций логично проверить переносимость: даже если команда умеет работать с платформой и провайдером, важно понимать, что она сможет забрать в другое облако при миграции.
Переносимость: что реально можно забрать в другое облако
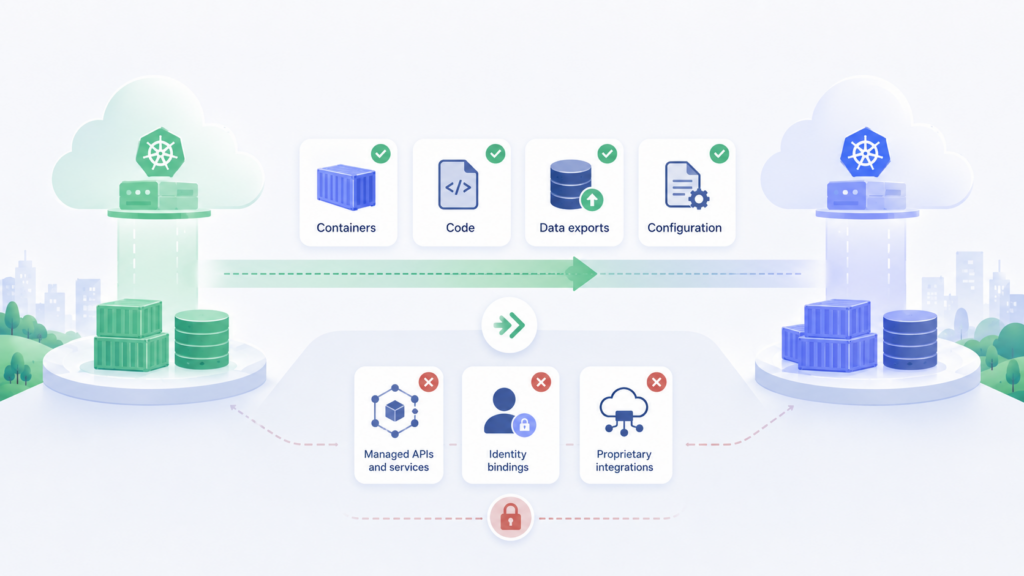
Переносимость часто описывают слишком обще: “Kubernetes стандартный, VM универсальные”. На практике переносить требуется не только приложение, но и сеть, хранилище, доступы, наблюдаемость, резервные копии, пайплайны релизов и операционные процедуры.
Сравнивать лучше не платформы целиком, а отдельные слои:
| Слой | Managed Kubernetes | Managed VM |
| Приложение | Контейнерные образы и стандартные манифесты обычно переносимы | Приложение можно перенести, если оно не зависит от специфичной настройки ОС, middleware и процессов провайдера |
| Сеть | Ingress, CNI, балансировщики и политики часто завязаны на облако | Зависят от VPC/VNet, firewall, маршрутов, балансировщиков и сетевых регламентов провайдера |
| Хранилище | Storage classes, CSI, снапшоты и диски часто специфичны | Диски, снапшоты, форматы бэкапов и процедуры восстановления могут быть привязаны к провайдеру |
| Доступы | RBAC переносим частично, IAM-интеграции отличаются | IAM-роли, ключи, системные доступы и модель заявок на администрирование зависят от облачной модели и SLA |
| Эксплуатация | GitOps и манифесты помогают, но cloud-addons нужно заменять | Риск в ручных изменениях, регламентах провайдера, локальных cron-задачах, нестандартизированных образах и неописанных managed-процедурах |
Kubernetes лучше переносит декларативно описанную модель приложения, но хуже переносит облачные интеграции вокруг неё. Managed VM проще перенести как вычислительный слой, но сложнее доказать, что все настройки ОС, middleware, бэкапы, доступы, регламенты поддержки и операционные зависимости были зафиксированы и воспроизводимы в другой среде.
Поэтому переносимость нужно проверять не словами “у нас Kubernetes” или “у нас VM”, а тестом восстановления: можно ли поднять приложение в другой среде, подключить сеть, восстановить данные, применить доступы, запустить мониторинг, воспроизвести регламенты администрирования и выполнить релиз без ручной реконструкции.
Наблюдаемость: где проще увидеть проблему

Наблюдаемость — это не только CPU и память. Для эксплуатации важны метрики, логи, трассировки запросов, события платформы, алерты, связь между релизом и деградацией, а также возможность быстро определить источник проблемы.
Managed VM: проще слои, больше ручной унификации
В Managed VM модель диагностики обычно понятнее. Есть ОС, службы, middleware, приложение, сетевые соединения и агент мониторинга. Провайдер может закрывать часть системной наблюдаемости: доступность VM, состояние ОС, базовые метрики, работу отдельных служб, бэкапов и типовых эксплуатационных процедур.
Но прикладная наблюдаемость всё равно остаётся зоной команды. Провайдер может увидеть, что nginx работает, диск не заполнен и VM доступна, но не всегда поймёт, что после релиза выросло время оформления заказа, сломалась авторизация или бизнес-операция начала завершаться ошибкой. Поэтому команде нужны собственные прикладные метрики, логи, трассировки, алерты по пользовательским сценариям и связь между релизами и деградацией.
Минус появляется при росте парка VM и числа managed-регламентов. У разных серверов могут быть разные агенты, разные настройки логирования, разные версии middleware и разные правила реакции провайдера. Поэтому наблюдаемость в Managed VM проще на старте, но требует согласования: какие метрики видит провайдер, какие алерты получает команда, кто реагирует первым и где проходит граница между системным и прикладным инцидентом.
Managed Kubernetes: больше сигналов, выше сложность диагностики
В Managed Kubernetes сигналов больше. Нужно видеть состояние подов, узлов, контейнеров, контроллеров, событий планировщика, ingress, сервисной сети, хранилища и плоскости управления.
Провайдер может дать готовую интеграцию с логами и метриками кластера, но команда всё равно отвечает за прикладные метрики, трассировку, алерты, срок хранения данных и стоимость их объёма.
Преимущество Kubernetes раскрывается при зрелой настройке: единая схема метрик, метки, namespaces, автоматическое обнаружение сервисов, стандартные экспортёры и связь с декларативной моделью релизов. Недостаток — более сложный troubleshooting: проблема может быть в приложении, лимитах ресурсов, сетевой политике, DNS, хранилище, CNI-плагине или интеграции с балансировщиком.
Managed VM проще читать на старте, потому что слоёв меньше и они привычнее. Kubernetes удобнее стандартизировать на масштабе, но он экономит время только тогда, когда команда умеет обслуживать его сигналы, алерты и зависимости.
Обновления безопасности: что обновляет провайдер, а что остаётся клиенту
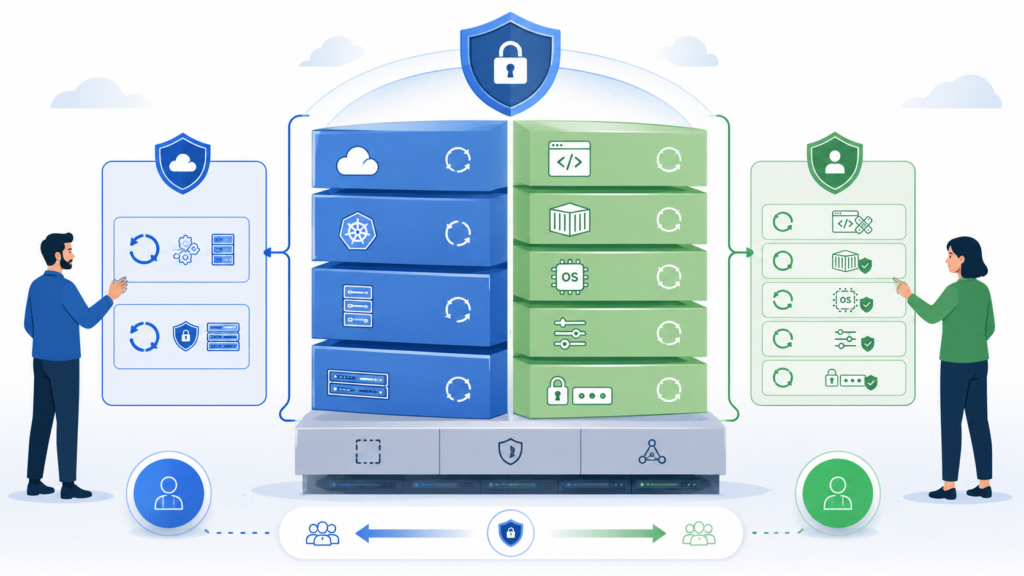
Обновления безопасности — частый источник неверных ожиданий от managed-сервисов. Провайдер не становится владельцем всей цепочки безопасности. Он закрывает свою часть платформы и те уровни, которые прямо входят в SLA, но у клиента остаются приложения, доступы, зависимости, секреты, политики и процедуры реагирования.
В Managed VM провайдер может брать на себя обновления гостевой ОС, системных пакетов, части middleware, агентов мониторинга и базовых служб. Но это нужно проверять в условиях услуги: какие компоненты обновляются автоматически, какие требуют согласования, кто выбирает окно обслуживания, кто перезапускает сервисы, кто проверяет совместимость и кто отвечает за откат после неудачного обновления.
Даже если патчи ОС и middleware входят в managed-услугу, клиент всё равно отвечает за прикладный уровень: код приложения, библиотеки, бизнес-логику, настройки доступа, секреты, релизный процесс и проверку критичных сценариев после обновлений. Провайдер может обновить nginx или runtime, но не гарантирует, что конкретный релиз приложения после этого сохранит прежнее поведение.
В Managed Kubernetes провайдер обычно ведёт или помогает обновлять control plane, но это не закрывает всю поверхность риска. Остаются рабочие узлы, базовые образы, контейнерные образы приложений, зависимости внутри образов, RBAC, секреты, admission-контроллеры, ingress-контроллеры и дополнительные компоненты. Обновление версии Kubernetes также может затронуть API, манифесты и сторонние контроллеры.
Различие для бизнеса такое: в Managed VM часть системных обновлений можно передать провайдеру, но нужно явно зафиксировать SLA, окна обслуживания, зоны ответственности и порядок отката. В Managed Kubernetes часть обновлений централизуется на уровне control plane, но ошибка в общей политике, образе или контроллере может затронуть сразу много сервисов.
После обновлений безопасности нужно смотреть на зависимость от провайдера. Именно там managed-сервис может из экономии времени превратиться в lock-in.
Lock-in и зависимость от API провайдера

Lock-in возникает не из-за самого факта использования Managed Kubernetes или Managed VM, а из-за того, какие облачные API, регламенты и операционные процедуры становятся частью архитектуры.
В Managed Kubernetes базовые объекты Kubernetes дают уровень стандартизации: Deployment, Service, ConfigMap, Namespace и другие сущности можно переносить между совместимыми кластерами. Но зависимость появляется на границе с облаком:
- Балансировщики через Service type LoadBalancer или managed ingress;
- Storage classes, завязанные на диски, IOPS, зоны доступности и снапшоты провайдера;
- IAM-интеграции для сервисных аккаунтов;
- CNI- и CSI-драйверы для сети и хранилищ;
- Управляемые DNS, сертификаты, секреты и реестры образов;
- Нативные сервисы логирования, мониторинга, трассировки и автоскейлинга.
Последствие миграции — не просто “пересоздать кластер”. Нужно заменить сетевые и дисковые интеграции, перепроверить IAM-модель, перенастроить ingress, перенести секреты, пересобрать пайплайны и убедиться, что резервные копии можно восстановить в целевой среде.
В Managed VM зависимость менее заметна, но тоже существенна. Она появляется не только в образах VM, но и в снапшотах, сетевых интерфейсах, группах безопасности, балансировщиках, managed-дисках, публичных IP, правилах маршрутизации, IAM-ролях для VM, агентах мониторинга, форматах бэкапов и автоматизации создания инстансов. Дополнительно появляется зависимость от того, как именно провайдер администрирует ОС и middleware: какие регламенты использует, как ставит обновления, как оформляются заявки, какие окна обслуживания доступны, как устроена эскалация, какие логи и метрики он показывает клиенту и в каком формате выполняет восстановление.
Если инфраструктура и эксплуатация завязаны на ручные действия через консоль или поддержку провайдера, lock-in усиливается: зависимость находится не только в API, но и в незафиксированных действиях операторов, runbook’ах, SLA, регламентах поддержки и процедурах восстановления, которые провайдер может не предоставлять полностью.
Снижать lock-in можно одинаковыми принципами: описывать инфраструктуру как код, отделять стандартные манифесты от облачных параметров, документировать IAM-модель, фиксировать состав managed-услуги, хранить собственные runbook’и, тестировать восстановление из резервных копий, избегать неописанной ручной настройки, фиксировать зависимые API и считать стоимость выхода из платформы до внедрения, а не в момент миграции.
Промежуточный итог по критериям выбора
Сравнение Managed Kubernetes и Managed VM не сводится к вопросу, какая платформа “лучше”. Это разные профили экономии, сложности и риска.
| Критерий | Чаще подходит Managed VM | Чаще подходит Managed Kubernetes |
| Тип нагрузки | Стабильное приложение, монолит, унаследованная система, небольшое число сервисов | Много сервисов, контейнеры, частые релизы |
| Порог входа | Ниже: привычная модель “сервер → ОС → приложение”, часть администрирования берёт провайдер | Выше: нужны навыки Kubernetes и платформенной эксплуатации |
| Эксплуатация | Меньше системной рутины внутри команды, если ОС, middleware, мониторинг и бэкапы входят в SLA | Меньше рутины при зрелой платформе, но сложнее диагностика |
| Переносимость | Проще перенести приложение как VM-модель, но сложнее воспроизвести managed-регламенты провайдера | Лучше переносится декларативная модель, хуже — облачные интеграции |
| Lock-in | SLA, регламенты поддержки, образы, диски, сети, снапшоты, IAM, бэкапы, мониторинг | Storage classes, ingress, IAM, CNI/CSI, managed-addons, мониторинг |
| Когда оправдано | Нагрузка проста, команда хочет сохранить понятную серверную модель и передать часть администрирования провайдеру | Команда уже работает с контейнерами, CI/CD и IaC |
Практическое правило: managed-сервисы экономят время, когда заменяют операции, которые команда уже понимает и может контролировать. Они создают lock-in, когда удобство провайдера становится неявной частью релизов, мониторинга, безопасности, сети, хранилища и восстановления.
Заключение

Выбор между Managed Kubernetes и Managed VM — это выбор операционной модели, а не спор о “современной” или “старой” платформе.
Managed VM рациональнее там, где нагрузка стабильна, архитектура проста, а команде подходит модель “сервер → ОС → приложение” с передачей части администрирования провайдеру. Такой подход может снизить нагрузку на команду за счёт управляемых обновлений ОС, поддержки middleware, базового мониторинга, бэкапов и типовых эксплуатационных процедур в пределах SLA.
Managed Kubernetes оправдан, когда контейнеризация уже стала частью процесса, сервисов много, релизы частые, а команде нужны стандартизированный деплой, автомасштабирование и единая модель окружений.
Экономия времени появляется только там, где managed-сервис действительно снимает повторяемые операции. Lock-in возникает в тех же точках: балансировщики, хранилища, IAM, сетевые интеграции, логирование, бэкапы, API провайдера и регламенты managed-эксплуатации.
Финальное решение должно отвечать на три вопроса: что сервис снимает с команды, что добавляет в эксплуатацию и насколько дорого будет изменить выбор через год или два.
FAQ
Что дешевле: Managed Kubernetes или Managed VM?
Универсального ответа нет. Managed VM может быть выгоднее для небольших и стабильных нагрузок, если плата за администрирование ОС, middleware, мониторинг и бэкапы ниже, чем внутренние часы команды. Managed Kubernetes может быть выгоднее при большом числе сервисов, частых релизах и зрелой автоматизации, но в расчёт нужно включать кластер, узлы, диски, балансировщики, трафик, мониторинг и время команды.
Managed Kubernetes избавляет от администрирования?
Нет. Провайдер обычно берёт на себя плоскость управления, но команда отвечает за приложения, контейнерные образы, рабочие узлы, сетевые политики, доступы, хранилища, обновления дополнений и наблюдаемость.
Когда лучше выбрать Managed VM?
Managed VM подходит для монолитов, унаследованных приложений, небольшого числа сервисов и стабильной нагрузки, когда команде удобна модель “сервер → ОС → приложение”, но часть администрирования ОС, middleware, мониторинга, бэкапов и типовых операций выгоднее передать провайдеру. Это также разумный вариант, если Kubernetes потребует больше обучения и перестройки процессов, чем принесёт пользы.
Где чаще возникает lock-in в Managed Kubernetes?
Не в базовых манифестах Kubernetes, а в облачных интеграциях: балансировщиках, storage classes, IAM, CNI/CSI-плагинах, managed ingress, секретах, реестрах образов, мониторинге и автоскейлинге. Чем больше таких интеграций, тем сложнее миграция.
VM меньше привязаны к провайдеру?
Не всегда. VM тоже могут зависеть от сетей, дисков, образов, снапшотов, групп безопасности, балансировщиков, IAM-ролей, агентов мониторинга и форматов резервного копирования. В Managed VM добавляется зависимость от SLA, регламентов поддержки, процедур обновления, мониторинга, бэкапов и восстановления. Риск ниже только тогда, когда конфигурация описана как код, образы воспроизводимы, границы ответственности зафиксированы, а восстановление регулярно проверяется в другой среде.
Список источников
1. Kubernetes Documentation — Concepts
2. AWS — Security in Amazon EKS


