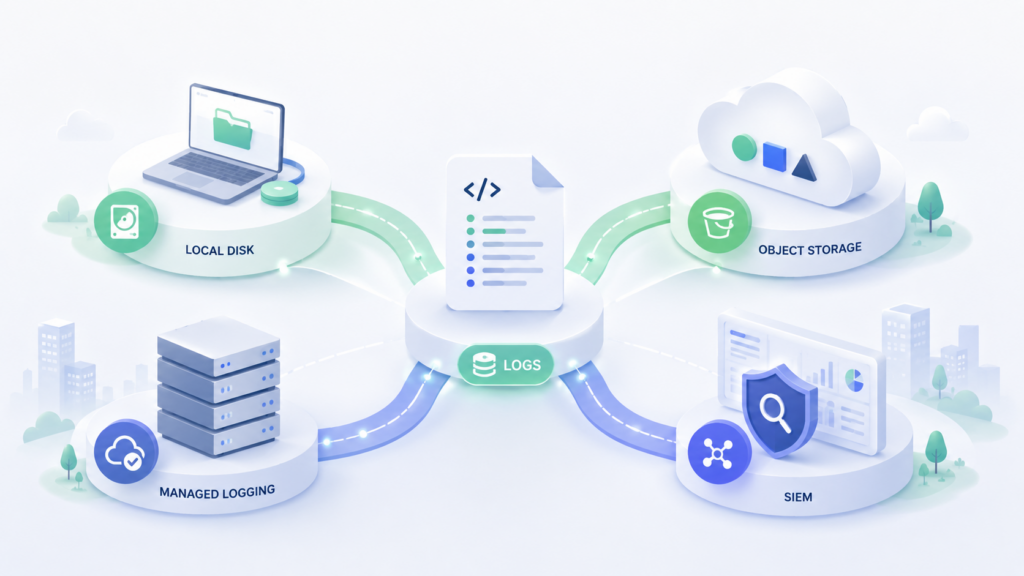
Стратегия хранения логов не должна сводиться к выбору одного “лучшего” хранилища. Логи живут в разных сценариях: одни нужны для быстрой отладки, другие — для мониторинга SLA, третьи — для аудита, расследований и долгосрочного архива.
Практичная схема обычно многоуровневая:
- Local disk — короткий буфер на хосте или в контейнере, полезный для первичной диагностики;
- Managed logging — оперативный поиск, дашборды, мониторинг и алерты за последние дни или недели;
- Object storage — долгосрочный архив больших объёмов с контролем стоимости и политиками хранения;
- SIEM — события безопасности, корреляция, расследования и контроль действий пользователей и администраторов.
Типичная ошибка — отправлять весь поток логов в managed logging и хранить его там месяцами. Это удобно для поиска, но дорого при больших объёмах. При этом журналы аудита могут остаться без защиты от удаления, а старые debug-записи будут почти не использоваться.
Выбор начинается не с инструмента, а с задачи: зачем хранится конкретный лог, за какой период он нужен, насколько быстро его нужно найти, кто имеет к нему доступ и требуется ли защита от изменения или удаления.
Зачем разделять логи по задачам хранения
Логи нужны разным командам и для разных задач. Разработка ищет причины ошибок, эксплуатация следит за доступностью и SLA, безопасность выявляет подозрительные действия, аудиторы проверяют изменения в критичных системах, регуляторы (если применимо к бизнесу) могут запросить действия пользователей.
Поэтому стратегия хранения не должна отвечать только на вопрос “куда отправить все логи”. Важно заранее определить, какие логи где хранить, сколько времени, насколько быстро к ним нужен доступ и как подтвердить их целостность.
Например, отладочные логи приложения могут быть полезны несколько дней после релиза. Журналы доступа к критичным системам могут понадобиться через месяцы. События безопасности должны быть связаны между источниками, а аудиторские записи — защищены от незаметного удаления или изменения.
Более устойчивый подход — разделить роли хранилищ. Local disk использовать как краткосрочный резерв, managed logging — для оперативного поиска и алертов, object storage — для долгого архива, а SIEM — для безопасности, корреляции событий и расследований.
Дальше выбор стоит вести не от названия инструмента, а от жизненного цикла логов: какие записи нужны прямо сейчас, какие должны храниться долго, а какие требуют неизменяемости, строгих прав доступа и доказуемой целостности.
Сначала определить цель хранения логов

Перед сравнением хранилищ нужно разделить логовые потоки по назначению. Единая политика “хранить всё год” обычно либо завышает расходы, либо не защищает действительно важные записи.
Основные цели можно разложить так:
| Цель | Что важно |
| Оперативная отладка | Быстро найти ошибку, связать событие с запросом, релизом или конфигурацией |
| Мониторинг и SLA | Увидеть рост ошибок, задержки, недоступность компонентов и срабатывание алертов |
| Аудит действий | Подтвердить, кто, когда и что изменил, и доказать, что запись не была или была изменена |
| Расследование инцидентов | Восстановить хронологию и взаимное влияние событий по нескольким источникам |
| Долгосрочный архив | Сохранить данные, которые редко используются, но могут потребоваться позже |
| Договорные и регуляторные требования | Показать, что события фиксируются и хранятся по заданным правилам |
Важно не смешивать аудит и расследование. Для аудита ключевое — доказуемость, контроль доступа и защита от изменения. Для расследования — связность событий: входы, API-вызовы, изменения прав, сетевые события, действия администраторов. Один и тот же лог может участвовать в обоих сценариях, но требования к хранению будут разными.
После цели хранения можно переходить к критериям: сколько хранить, как быстро искать, сколько это стоит и насколько записи должны быть защищены от удаления.
Критерии выбора: срок, доступ, стоимость и защита

Сравнивать local disk, object storage, managed logging и SIEM нужно не только по цене за гигабайт. В логах часто дороже не само хранение, а индексация, запросы, восстановление из архива, лицензирование и потеря доказательств.
Для отладочных логов обычно важны быстрый поиск и короткий срок хранения: дни или недели. Для аудита и событий безопасности важнее целостность, контроль доступа, защита от удаления и возможность поднять запись через месяцы или годы. Для расследований нужны связность событий, нормализация полей, единые временные метки и возможность быстро собрать временную линию по нескольким системам.
Отдельно нужно учитывать чувствительность данных. В логах могут быть IP-адреса, email, идентификаторы пользователей, токены, персональные данные и фрагменты запросов. Это влияет на маскирование, шифрование, доступы и сроки хранения.
Качество записи тоже критично. Лог теряет ценность, если в нём нет точного времени, источника, субъекта действия, идентификатора запроса, ресурса или результата операции. Формально запись есть, но использовать её для расследования или аудита сложно.
Простой пример: хранить год отладочные логи приложения в индексированной системе обычно экономически неоправданно. Но журналы аудита за тот же период могут быть обязательны, даже если открываются редко: для них важны целостность, ограничение доступа и возможность доказать неизменность.
Четыре стратегии хранения: где каждая работает, а где нет

В зрелой схеме local disk, managed logging, object storage и SIEM не заменяют друг друга. Они закрывают разные этапы жизненного цикла логов: короткий буфер, оперативный поиск, долгий архив и безопасность.
Local disk: короткий буфер и первичная диагностика
Local disk полезен, когда нужно быстро посмотреть, что происходило с процессом, агентом или контейнером до отправки логов наружу. Это удобный краткосрочный резерв на хосте и источник для первичной диагностики.
Но локальный диск не должен быть финальным хранилищем. Виртуальная машина может быть удалена, контейнер пересоздан, диск повреждён, а ротация — перезаписать события. Если хост скомпрометирован, локальные файлы также нельзя считать надёжным доказательством.
Роль local disk — буфер и оперативная диагностика, а не аудит, долгосрочное хранение или централизованный поиск.
Managed logging: быстрый поиск и операционные алерты
Managed logging подходит для ежедневной эксплуатации: найти ошибку по идентификатору запроса, проверить релиз, увидеть рост 5xx, исследовать задержки, построить дашборд или настроить алерт.
Главное ограничение — стоимость. При большом потоке цена растёт из-за приёма логов, индексации, хранения, запросов и алертов. Особенно дорого хранить месяцами технический шум: debug-записи, подробные access logs и повторяющиеся сообщения, которые почти не используются.
Роль managed logging — оперативный поиск и мониторинг, а не бессрочный архив всего объёма логов.
Object storage: долгосрочный архив больших объёмов
Object storage удобен для хранения сырых логов и архивов. В нём можно применять политики жизненного цикла, переводить старые данные в более дешёвые классы, задавать сроки удаления и включать неизменяемое хранение.
Но объектное хранилище не является поисковой системой. Для анализа нужны каталогизация, понятная структура путей, форматы, схема полей и отдельный движок запросов. Иначе архив будет дешёвым, но трудным для использования.
Роль object storage — долгий архив, резерв для аудита и источник исторических данных. Его не стоит считать заменой managed logging или SIEM.
SIEM: безопасность, корреляция и расследования
SIEM нужен для событий, значимых для безопасности: входов, изменений прав, действий администраторов, событий IAM, подозрительных API-вызовов, сетевых и облачных событий, изменений политик.
Ценность SIEM не столько в хранении, а в нормализации, корреляции и приоритизации сигналов. Например, вход из новой страны, отключение MFA и создание ключа доступа по отдельности могут выглядеть допустимо, но вместе указывать на компрометацию.
SIEM обычно дороже архива и managed logging, поэтому не должен хранить весь отладочный поток. Его роль — безопасность и расследования, а не универсальное хранилище всех логов приложения, нормальная история когда сырые логи вовсе не хранятся в SIEM (максимум - несколько дней), в отличие от нормализованных и коррелированных событий.
После разделения ролей можно сравнить стратегии по срокам, стоимости и сценариям: local disk — коротко, managed logging — быстро, object storage — долго, SIEM — для безопасности и расследований.
Сравнение стратегий по срокам, стоимости и сценариям

Ниже — ориентировочное сравнение четырёх уровней хранения логов. Конкретные сроки зависят от отрасли, договоров, требований безопасности, законодательства и внутренней модели рисков.
| Стратегия | Типичные сроки | Стоимость | Где полезна |
| Local disk | От нескольких часов до 7–14 дней, часто до ротации или отправки дальше | Низкая как прямые затраты, но высокая цена потери данных при сбое или удалении хоста | Локальная диагностика, буфер при сбое доставки, временное хранение системных и агентских логов |
| Managed logging | Обычно 7–90 дней; для критичных сервисов иногда до 180 дней | Средняя или высокая: приём, индексация, хранение, запросы, алерты, тарифы за объём и срок | Поиск ошибок, поддержка SLA, эксплуатационные алерты, анализ релизов, диагностика обращений |
| Object storage | От месяцев до нескольких лет; для архивных требований — 3–7 лет и более | Низкая за хранение больших объёмов, но важны запросы, извлечение из архива, каталогизация и обработка | Долгосрочный архив, резерв для аудита, хранение сырых логов, последующий анализ |
| SIEM | Часто 5–30 дней в горячем поиске; 1–3 года и более в архиве в нормализованном виде | Высокая: лицензирование, нормализация, индексация, корреляция, хранение и работа аналитиков | Мониторинг безопасности, расследование инцидентов, контроль привилегированных действий |
Из таблицы следует базовая схема: local disk не должен быть единственным хранилищем, managed logging подходит для оперативного поиска, object storage — для долгого и относительно дешёвого архива, SIEM — для безопасности и расследований.
На практике эти уровни комбинируют: часть логов быстро индексируется, часть уходит в архив, а события безопасности дополнительно направляются в SIEM. Дальше стратегию стоит проверять не только по хранилищам, но и по сценариям: аудит, расследование инцидентов и долгосрочное архивирование требуют разных правил.
Рекомендации по сценариям
Сравнение по срокам и стоимости задаёт общую роль каждого уровня, но окончательный выбор обычно делается по сценарию. Аудит, расследование инцидентов и долгосрочное архивирование требуют разных правил хранения.
Аудит: доказуемость и защита от изменения
Для аудита важны доказуемость, целостность и управляемость. Нужно подтвердить, что событие произошло, запись не была изменена, доступ к ней ограничивался, а удаление контролировалось.
Основной уровень хранения для аудита — object storage с политиками жизненного цикла, шифрованием, раздельными правами и журналированием доступа. Для критичных журналов нужен WORM-режим или другая функция неизменяемого хранения. Managed logging можно использовать для быстрого поиска по недавним записям, а SIEM — для событий безопасности: входов, действий администраторов, изменений прав, отключения MFA и создания ключей доступа.
Для аудиторских логов важно заранее определить обязательные поля: время события, субъект, объект, источник, результат операции, идентификатор сессии или запроса. Администратор приложения не должен иметь возможность незаметно удалить собственные действия из журнала.
Расследование инцидентов: связность событий
Для расследования инцидентов важна не только сохранность логов, но и связность событий. Команде безопасности нужно быстро восстановить временную линию: когда началась активность, какой аккаунт использовался, какие системы были затронуты и какие данные могли быть прочитаны или изменены.
Основной слой расследования — SIEM. Туда направляют события входа, управления доступом, действия администраторов, сетевые и облачные события, изменения политик и срабатывания средств защиты. Managed logging даёт технический контекст: ошибки приложений, запросы, инфраструктурные события и взаимодействие сервисов. Object storage остаётся историческим источником, если нужно поднять полный или сырой набор логов за старый период.
Local disk может помочь при анализе конкретного хоста, но не должен быть единственной копией. Для расследований критичны синхронизация времени, единые временные метки, нормализация форматов и идентификаторы, которые связывают события между системами. Если инциденты часто обнаруживаются через 30–60 дней, хранение событий безопасности только 7 дней создаёт слепую зону.
Долгосрочное архивирование: стоимость и восстановимость
Долгосрочное архивирование нужно для данных, которые редко используются в ежедневной работе, но должны сохраняться по внутренней политике, контракту, требованиям регуляторов или модели рисков. Главные критерии — управляемая стоимость, целостность и возможность восстановить данные.
Основной уровень здесь — object storage. Логи лучше хранить в структурированных путях по системе, дате, типу события и окружению. Для старых данных можно применять жизненный цикл: переводить их в более дешёвые или архивные классы хранения. Постоянно индексировать весь архив обычно не нужно: практичнее поднимать временные наборы для конкретных проверок.
Для долгого архива важно сохранить контекст. Файл с миллионами строк через несколько лет бесполезен, если неизвестно, из какой системы он пришёл, какие поля содержит, в каком часовом поясе записано время и какие данные были замаскированы.
Как собрать практическую схему хранения
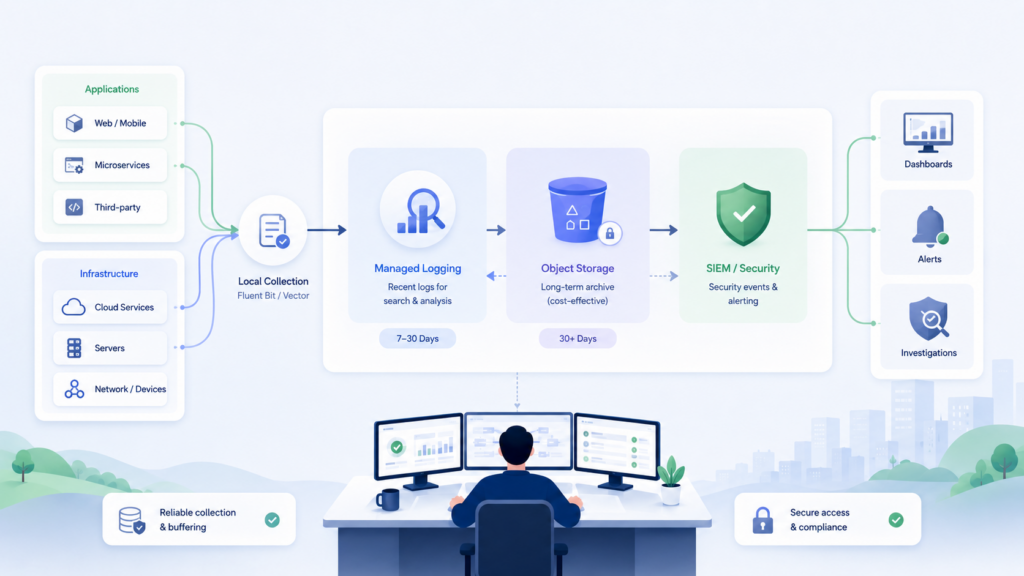
Многоуровневая схема обычно строится по жизненному циклу логов:
local disk → managed logging → object storage → SIEM для событий безопасности
На хосте или в контейнере логи хранятся короткое время и быстро отправляются дальше. Local disk работает как буфер, а не как финальное хранилище.
В managed logging попадают записи для ежедневной эксплуатации: ошибки, access logs за оперативный период, инфраструктурные события, данные для дашбордов и алертов.
В object storage отправляется полный или частично отфильтрованный поток для архива, аудита и восстановления исторических данных. Этот слой помогает не платить за долгий индексированный доступ ко всему объёму.
В SIEM направляются события безопасности и контроля доступа, а также часть прикладных логов, если они помогают расследовать действия пользователей или администраторов.
Фильтрацию и маршрутизацию нужно проектировать заранее. Если весь поток сначала попадает в дорогую индексированную систему, а затем вручную очищается, стоимость и сложность растут быстрее полезности.
Перед утверждением схемы стоит проверить четыре вопроса:
- Можно ли найти операционную ошибку за последние часы или дни;
- Можно ли доказать действия пользователя или администратора через месяцы;
- Можно ли восстановить временную линию инцидента из нескольких источников;
- Понятно ли, где хранятся сырые данные и как их восстановить из архива.
Если хотя бы на один вопрос нет ответа, схеме не хватает либо оперативного поиска, либо архива, либо слоя безопасности и корреляции.
Заключение
Устойчивая стратегия хранения логов строится вокруг жизненного цикла данных. Local disk закрывает короткий буфер, managed logging — быстрый поиск и алерты, object storage — долгий архив, SIEM — безопасность, корреляцию и расследования.
Практический выбор сводится к трём решениям: какие логи нужны в оперативном доступе, какие должны храниться долго и относительно дёшево, а какие требуют неизменяемости, строгого контроля доступа и отдельного анализа безопасности.
FAQ
Можно ли хранить логи только на local disk?
Только как временный буфер. Локальный диск подходит для оперативной диагностики, но не защищает от удаления виртуальной машины, сбоя диска, ротации логов, пересоздания контейнера или компрометации хоста.
Что отправлять в managed logging?
Логи, которые нужны для ежедневной эксплуатации и централизованного ручного поиска и анализа: ошибки приложений, логи доступа за оперативный период, инфраструктурные события, данные для алертов и поддержки SLA. Долгое хранение всего потока в индексированном виде обычно приводит к лишним расходам.
Какие логи должны попадать в SIEM?
События, значимые для безопасности: входы пользователей, изменения прав, действия администраторов, события IAM, подозрительные API-вызовы, сетевые и облачные события. Отладочные логи и технический шум лучше фильтровать или хранить отдельно.
Подходит ли object storage для поиска по логам?
Само по себе объектное хранилище больше подходит для архива. Для анализа нужны дополнительные инструменты: движок запросов, каталогизация, нормализация форматов и понятная схема хранения.
Как выбрать срок хранения логов?
Срок задают по типу логов и задаче: оперативные логи могут храниться недели, журналы аудита и события безопасности — месяцы или годы, архивные данные — по требованиям договора, регуляторики и внутренней политики.
Что важно для аудита логов?
Нужны неизменяемость или WORM-режим, раздельные права на чтение и удаление, журналирование доступа к самим логам, синхронизация времени и понятный контекст события: кто, когда, из какой системы и что изменил.
Список источников
1. NIST SP 800-92: Guide to Computer Security Log Management


