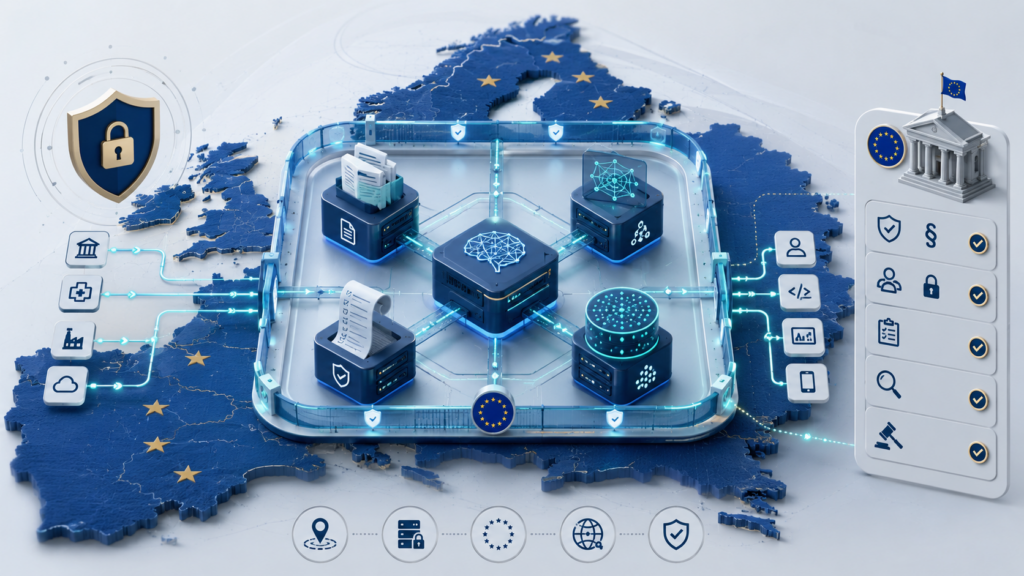
Суверенный AI — это не только выбор облачного региона для основной базы данных. В AI-системах чувствительная информация появляется в нескольких слоях: запросах к модели, ответах, embedding-базах, RAG-индексах, датасетах дообучения, логах, телеметрии, файлах, резервных копиях и обращениях в поддержку.
Поэтому проверять нужно весь маршрут данных: где они хранятся, где обрабатываются, куда передаются во время запроса, кто имеет доступ поддержки, как долго сохраняются производные копии и используются ли они для обучения, диагностики или улучшения сервиса.
Практический принцип такой:
- Исходные документы, персональные данные, коммерческая тайна, embedding-базы и неочищенные логи должны оставаться в контролируемом регионе;
- Внешнему AI API можно передавать только минимальный, очищенный, обезличенный или токенизированный контекст;
- Датасеты дообучения, checkpoints, адаптеры и веса после обучения на внутренних данных нужно считать чувствительными активами;
- Логи запросов, ответов модели, ошибок и трассировок не должны превращаться в теневую базу чувствительных данных;
- Удаление исходного документа должно быть связано с удалением фрагментов, embeddings, индексов, логов и резервных копий, где это применимо.
Главный вопрос не в том, “где лежит основная база”, а в том, контролирует ли компания весь путь данных — от документа до запроса, embedding, ответа модели, лога, бэкапа и доступа поддержки.
Почему одного правильного региона недостаточно
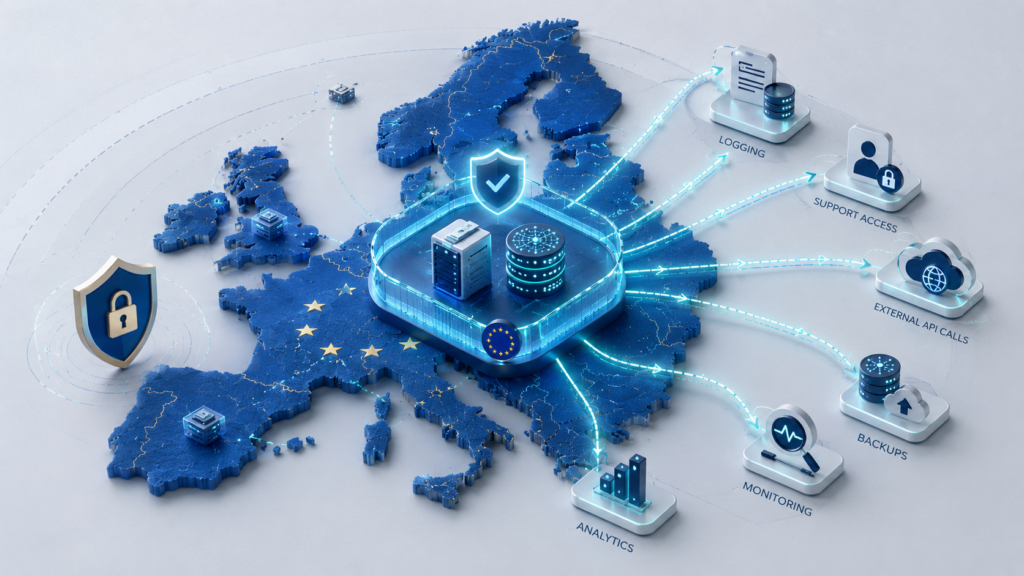
Компания может хранить документы и клиентские данные в нужном облачном регионе, настроить доступы и шифрование, пройти аудит — и всё равно случайно вывести чувствительную информацию из контролируемой зоны.
Для этого не обязательно переносить основную базу. Достаточно отправлять фрагменты договоров во внешний AI API, держать embedding-базу в глобальном хранилище или писать запросы, ответы модели и ошибки в SaaS-мониторинг без очистки. Формально источник данных может оставаться в правильном регионе, но копии и производные слои уже живут по другим правилам.
В AI-системах риск возникает не только вокруг базы данных. Данные появляются в контекстах запросов, ответах модели, векторных индексах, наборах для дообучения, логах, телеметрии, файлах, резервных копиях и обращениях в поддержку.
Поэтому суверенный AI — это не только юридический вопрос, а вопрос облачной архитектуры: где хранятся данные, модели, логи и embedding-базы, какие компоненты остаются в контролируемом регионе, что можно передавать наружу и на каких условиях.
Дальше разберём главный принцип такой архитектуры: сначала нужно контролировать не отдельную базу, а полный маршрут данных внутри AI-контура.
Маршрут данных важнее выбранного региона

Выбор облачного региона ещё не означает, что весь AI-контур стал суверенным. Резидентность данных отвечает на вопрос, где данные хранятся и обрабатываются. Суверенность шире: она включает договорные условия, технические ограничения, доступ поддержки, сроки хранения, удаление производных копий и правила передачи данных во внешние сервисы.
Главная ошибка — считать резидентность полной суверенностью. Основная база может находиться в регионе ЕС, но фрагмент договора уйдёт во внешний AI API, embedding-база окажется в глобальном сервисе, а тело запроса сохранится в SaaS-мониторинге. Формально база не переносилась, но часть данных уже вышла из контролируемого маршрута.
Поэтому проверять нужно не один ресурс, а весь путь данных:
- Где данные хранятся;
- Где они обрабатываются;
- Куда передаются во время запроса, диагностики и интеграции;
- Кто имеет административный доступ или доступ поддержки;
- Как долго сохраняются копии, логи и промежуточные результаты;
- Используются ли данные для обучения, диагностики или улучшения сервиса.
Если хотя бы один слой не контролируется, регион основной базы не закрывает риск. Поэтому следующий шаг — разделить данные по чувствительности и понять, какие производные слои AI тоже требуют защиты.
Чувствительные, обезличенные и производные данные

В AI-системе чувствительными становятся не только исходные документы. Риск может сохраняться в коротком фрагменте запроса, ответе модели, embedding-базе, журнале ошибки или наборе данных для оценки качества.
К чувствительным данным относятся персональные данные, коммерческая тайна, договоры, клиентская переписка, медицинская и финансовая информация, внутренние документы и исходные обращения в поддержку. Чувствительность определяется не форматом, а содержанием и контекстом: PDF договора, строка из CRM и выдержка из тикета могут требовать одинакового уровня контроля.
Обезличенные данные можно обрабатывать свободнее, но их нельзя автоматически считать безопасными. Если из текста удалили имя, но оставили номер дела, редкую медицинскую формулировку, адрес объекта или уникальную комбинацию признаков, повторная идентификация всё ещё возможна.
Токенизированные данные дают больше контроля. В этом случае реальные значения заменяются токенами, а восстановление возможно только внутри контролируемой зоны. Например, внешний AI-сервис получает CLIENT_123, а не имя клиента, номер полиса или счёта.
Для AI-архитектуры важно учитывать не только исходные данные, но и производные слои:
- Запросы к модели и ответы модели;
- Embeddings и embedding-базы;
- RAG-индексы;
- Датасеты дообучения и оценки;
- Артефакты модели, адаптеры и контрольные точки;
- Логи, телеметрию и данные поддержки;
- Резервные копии всех этих слоёв.
Производные данные не становятся безопасными автоматически. Ответ модели может повторить имя, номер заказа или диагноз. Журнал API может сохранить и запрос, и ответ. Embeddings тоже нельзя считать обезличенными по умолчанию: они сохраняют смысловую близость к исходным документам и могут раскрывать контекст через поиск.
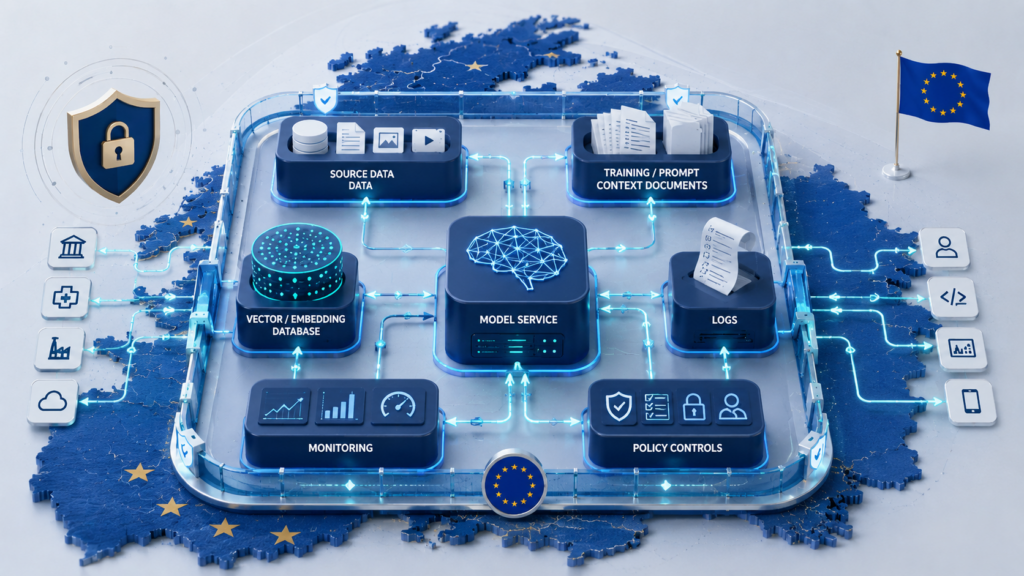
Схема размещения AI-компонентов

После классификации данных архитектуру нужно разложить по зонам контроля. Это помогает увидеть, какие компоненты остаются внутри управляемого облачного контура, а какие могут взаимодействовать с внешними сервисами только после очистки, маскирования или токенизации.
Главный принцип простой: документ может храниться в нужном регионе, но его фрагмент может уйти в запрос к модели, embedding-базу, лог, трассировку ошибки или тикет поддержки. Поэтому правила размещения должны охватывать не только исходную базу, но и все производные слои AI-системы.
| Зона контроля | Что туда относится | Главное правило |
| Контролируемый регион | Исходные документы, персональные данные, коммерческая тайна, embedding-базы, RAG-индексы, датасеты дообучения, резервные копии | Чувствительные и производные данные остаются в утверждённом регионе |
| Среда выполнения AI | Модель, частная сеть, доступ к данным, ключи шифрования, роли, DLP, аудит | Запросы обрабатываются под контролем компании и с ограниченными правами |
| Шлюз перед внешним AI API | Минимизация контекста, маскирование, токенизация, фильтрация запрещённых категорий данных | Наружу уходит только то, что действительно нужно для ответа |
| Зона мониторинга | Логи, метрики, трассировки, события безопасности | Запросы и ответы модели очищаются до попадания в мониторинг |
| Поддержка и администрирование | Доступы инженеров, аварийные права, обращения в поддержку, вложения к тикетам | Доступ временный, журналируемый и без неочищенных выгрузок |
Такая схема нужна, чтобы не перепутать “данные лежат в регионе” и “весь AI-контур контролируется”. Если embedding-база, логи или тикеты поддержки живут по другим правилам, суверенность основной базы не закрывает риск.
После такой карты можно перейти к практическому вопросу: где именно должны храниться ключевые слои AI-системы — данные, модели, логи и embedding-базы.
Где хранить данные, модели, логи и embedding-базы

Данные: исходные, очищенные и производные
Исходные чувствительные данные должны храниться в контролируемом регионе и обрабатываться в среде, где управляются доступы, шифрование, резервные копии и сроки хранения. Это касается не только основной базы, но и файловых хранилищ, очередей, временных каталогов, кэшей и экспортов для аналитики.
Обезличенные и токенизированные данные можно использовать шире, но только если процесс очистки описан и проверяем. Простое удаление имени не поможет - повторную идентификацию можно выполнить и по косвенным данным, или их совокупности, например компания и должность могут идентифицировать довольно точно.
Практическое правило: чувствительные данные остаются внутри контролируемого региона, а наружу передаётся только минимальный контекст без прямых идентификаторов и лишних деталей. Если модель может ответить без полного документа, полный документ не должен покидать контур.
Модели: базовая модель, дообучение и артефакты
Модель не всегда обязана храниться там же, где данные. Если компания использует базовую модель внешнего провайдера и передаёт ей только обезличенные фрагменты, главный риск связан не с весами модели, а с запросами, логами, файлами и условиями обработки у провайдера.
Другая ситуация — дообучение на внутренних данных. Датасеты, контрольные точки, адаптеры, веса после обучения и результаты оценки качества нужно считать чувствительными активами. Они могут не содержать исходный документ в явном виде, но отражать внутренние формулировки, классификации, клиентские сценарии или бизнес-логику.
Поэтому контур обучения и контур выполнения модели нужно описывать отдельно: где лежат обучающие наборы, где запускается обучение, где сохраняются артефакты и кто может их скачать.
Логи: диагностика не должна становиться теневой базой
Логи как правило нужны для расследований, мониторинга качества и безопасности, но в AI-системах они легко превращаются в копию чувствительных данных. Опасны журналы, где сохраняются запросы пользователей, ответы модели, тело API-запроса, идентификаторы, фрагменты документов, ошибки, трассировки и данные тикетов поддержки.
Логи должны храниться в регионе, совместимом с требованиями к исходным данным, либо очищаться до передачи в централизованный мониторинг. Для них, как и для других данных, нужны маскирование, ограниченные сроки хранения, права просмотра, контроль экспорта и понятная процедура удаления.
Частая ошибка — настроить основную AI-систему в нужном регионе, но отправлять необработанные журналы во внешний сервис наблюдаемости. В этом случае именно логи становятся каналом выхода данных из контролируемой зоны.
Embedding-базы и RAG: производное хранилище, а не кэш
Embedding-база хранит векторные представления документов и фрагментов. В RAG-архитектуре она используется для поиска релевантных внутренних источников, которые затем добавляются в контекст запроса к модели. Поэтому это не технический кэш, а производное хранилище, связанное с исходными документами.
Если embedding-база построена на чувствительных данных, её нужно хранить в контролируемом регионе, защищать доступом, шифрованием и аудитом, а удаление синхронизировать с исходными документами. Если документ удалён или истёк срок его хранения, соответствующие фрагменты и векторы должны быть удалены или переиндексированы.
Embeddings нельзя считать обезличенными по умолчанию. Даже без исходного текста индекс может раскрывать смысловую структуру документов, внутренние темы и связи между клиентами, событиями или договорами. Отдельный риск возникает, когда RAG возвращает во внешний AI API слишком большой фрагмент документа: embedding-база остаётся в регионе, но найденный текст всё равно уходит наружу.
После размещения основных компонентов остаётся проверить региональные требования шире: не только для баз и моделей, но и для логов, резервных копий, мониторинга, поддержки и субподрядчиков.
Требования к регионам хранения и обработки
Регион важен не только для основной базы: в AI-архитектуре данные и производные артефакты появляются в файлах, embedding-базах, датасетах дообучения, артефактах модели, логах, резервных копиях, мониторинге и обращениях в поддержку.
Минимальная проверка по регионам должна отвечать на несколько вопросов:
- Основные данные — хранилища документов, файлов, баз и рабочих наборов;
- Выполнение модели — регион инференса, маршрутизация запросов и обработка ответов;
- Embedding-слой — место создания и хранения embedding-баз, RAG-индексов и связанных метаданных;
- Дообучение — среда обучения, датасеты, контрольные точки, адаптеры и результаты оценки;
- Наблюдаемость — журналы, метрики, трассировки, события безопасности и сервисы мониторинга;
- Резервные копии — основные, аварийные и архивные копии данных и производных артефактов;
- Поддержка — тикеты, вложения, аварийные выгрузки и ручной доступ инженеров;
- Административный доступ — страны, роли и условия, из которых возможны действия провайдера или подрядчика;
- Субподрядчики — сторонние сервисы, участвующие в обработке, хранении или поддержке.
Для суверенного AI чувствительные данные, embedding-базы, датасеты дообучения, артефакты модели, неочищенные логи и резервные копии должны оставаться в одном контролируемом регионе или в заранее утверждённом наборе регионов. Если часть обработки уходит в другую юрисдикцию, это должно быть видно не только в договоре, но и в архитектурной схеме, настройках сервиса и правилах доступа.
Формулировка “ресурс создан в регионе X” слишком слабая. Лучше фиксировать требование шире: данные, производные артефакты, логи, резервные копии и доступ поддержки ограничены регионом X или утверждённым набором регионов. Только так закрывается не декларативный, а архитектурный уровень суверенности.
После регионов остаётся самый спорный элемент AI-архитектуры — внешний AI API. Его можно использовать, но только если понятно, какие данные уходят наружу, где они обрабатываются и что происходит с ними после ответа модели.
Риски внешних AI API и проверки перед использованием
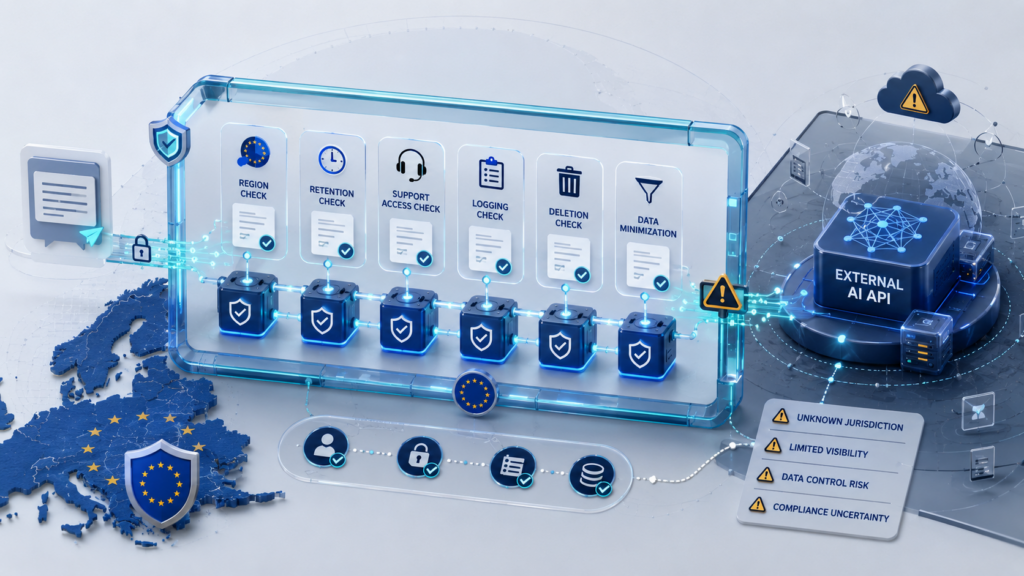
Внешний AI API может быть допустимым элементом архитектуры, если он получает только минимизированный и очищенный контекст. Но его нельзя оценивать как обычный вычислительный вызов. В запросе к модели могут оказаться фрагмент документа, история диалога, пользовательский идентификатор, внутренняя инструкция или результат поиска из RAG-системы.
Перед подключением внешнего API стоит проверить ключевые зоны риска:
| Зона риска | Что проверить |
| Запросы и ответы | Сохраняются ли они для диагностики, безопасности или улучшения сервиса |
| Обучение | Используются ли запросы, файлы, ответы, оценки качества или логи для обучения |
| Регион обработки | Где выполняется модель, логирование, мониторинг и проверка злоупотреблений |
| Файлы и вложения | Какие сроки хранения и удаления применяются к загруженным документам |
| Векторные хранилища | Где создаются и хранятся embeddings, если провайдер строит их сам |
| Логи безопасности | Какие данные попадают в журналы мониторинга злоупотреблений |
| Ручной доступ | Кто может получить доступ при расследовании инцидента или обращении в поддержку |
| Субподрядчики | Какие сторонние сервисы участвуют в обработке и в каких юрисдикциях |
| Удаление | Как удаляются запросы, файлы, embeddings, логи и резервные копии |
Эта таблица нужна не для формальной оценки поставщика, а для решения: какие данные вообще можно отправлять наружу. Если провайдер не даёт ясных ответов по регионам, хранению, логам, обучению, ручному доступу и удалению, внешний API не должен получать чувствительные данные.
В таком случае остаются три безопаснее контролируемых варианта: запуск модели в собственной управляемой среде, использование внешнего API только с токенизированным контекстом или шлюз, который очищает запросы и блокирует передачу запрещённых категорий данных.
Главная проверка простая: внешний AI API не должен становиться обходным каналом, через который документы, идентификаторы, embeddings, логи или результаты RAG выходят из контролируемой зоны.
Заключение
Суверенность AI-системы определяется не только регионом основной базы, а контролем над всем маршрутом данных: от документа и запроса к модели до embedding-базы, ответа, лога, резервной копии и доступа поддержки.
Чувствительные данные и производные слои, из которых можно восстановить смысл, идентификаторы или бизнес-контекст, должны оставаться в контролируемом регионе и обрабатываться в управляемой среде. Во внешний AI API стоит передавать только минимальный, очищенный, обезличенный или токенизированный контекст.
Практический критерий простой: если компания понимает, где хранятся данные, модели, логи и embeddings, кто имеет к ним доступ, как они удаляются и что уходит во внешние сервисы, AI-контур можно считать управляемым. Если нет — выбранный регион остаётся декларацией, а не суверенной архитектурой.
FAQ
Нужно ли хранить модель в том же регионе, что и данные?
Не всегда. Если модель не содержит следов внутренних данных и получает только обезличенный контекст, её можно размещать отдельно при соблюдении договорных и технических условий. Но датасеты дообучения, контрольные точки и артефакты модели после обучения на внутренних данных лучше считать чувствительными активами.
Можно ли отправлять документы во внешний AI API?
Полные документы с персональными данными, коммерческой тайной, медицинской, финансовой или договорной информацией отправлять рискованно. Безопаснее извлекать минимальный фрагмент, удалять идентификаторы, применять токенизацию и проверять, где API обрабатывает и хранит запросы.
Почему embedding-база считается чувствительной?
Embedding не равен исходному тексту, но сохраняет смысловую структуру документа. Через поиск, сопоставление или ошибки доступа можно раскрыть закрытый контекст. Поэтому векторную базу нужно защищать как производное чувствительное хранилище, а не как технический кэш.
Какие логи опасны для резидентности данных?
Опасны журналы, где сохраняются запросы к модели, ответы модели, тело API-запросов, идентификаторы пользователей, фрагменты документов, трассировки ошибок и данные тикетов поддержки. Для них нужны очистка, маскирование, ограниченные сроки хранения и привязка к нужному региону.
Достаточно ли условия «данные не используются для обучения»?
Нет. Нужно также проверить срок хранения, регион обработки, хранение файлов, векторные хранилища, мониторинг злоупотреблений, ручной доступ, субподрядчиков, исключения из региональных гарантий и процедуру удаления данных.
Кто отвечает за суверенность AI в облаке?
Ответственность разделена. Провайдер отвечает за свою инфраструктуру и заявленные условия сервиса. Клиент отвечает за классификацию данных, маршрутизацию запросов, настройки доступа, шифрование, DLP-средства, логи, выбор региона и политику передачи данных во внешние сервисы.
Список литературы
1. NIST — AI Risk Management Framework
2. Cloud Security Alliance — Data Security within AI Environments
3. OWASP — Top 10 for LLM Applications 2025
4. Microsoft Learn — Data, privacy, and security for Azure OpenAI Service


