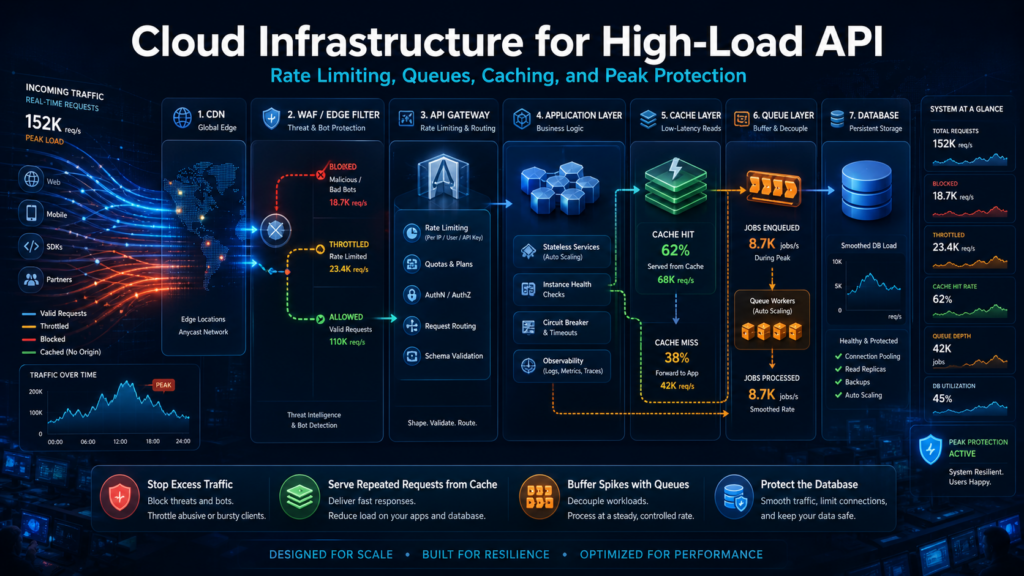
Каждому специалисту, который отвечает за API под нагрузкой, знаком неприятный сценарий: трафик резко вырос, приложение вроде масштабируется, но система всё равно начинает упираться в базу данных, платёжный сервис, внешнюю интеграцию или очередь задач. Проблема часто не в самом количестве запросов, а в том, сколько ресурсов требует каждый из них.
Десять тысяч простых обращений к справочнику могут пройти спокойно, если ответ отдаётся из кэша. А несколько сотен тяжёлых операций могут занять базу данных, обработчики и внешние сервисы. Поэтому high-load API нужно защищать не одним большим лимитом, а несколькими слоями.
Чтобы API выдерживал пики, защиту стоит строить так:
- Лишний и подозрительный трафик отсекать на CDN/WAF и API Gateway;
- Повторяемые ответы отдавать из кэша;
- Дорогие операции переводить в очередь и выполнять с контролируемой скоростью;
- Базу данных и внешние сервисы защищать таймаутами, лимитами и деградацией;
- Лимиты считать не только по числу запросов, но и по стоимости операций, клиентам, тарифам и приоритетам.
Главная цель — не принять бесконечно много запросов, а сделать поведение API предсказуемым под нагрузкой. Часть трафика должна быть ограничена, часть обслужена из кэша, часть отложена, а самые дорогие зависимости не должны получать весь пик напрямую.
Сначала разберём, где именно должен останавливаться лишний трафик. Без такой карты защиты лимиты, кэширование и очереди превращаются в набор отдельных инструментов, а не в единую схему устойчивости API.
Многоуровневая защита API: где должен останавливаться лишний трафик
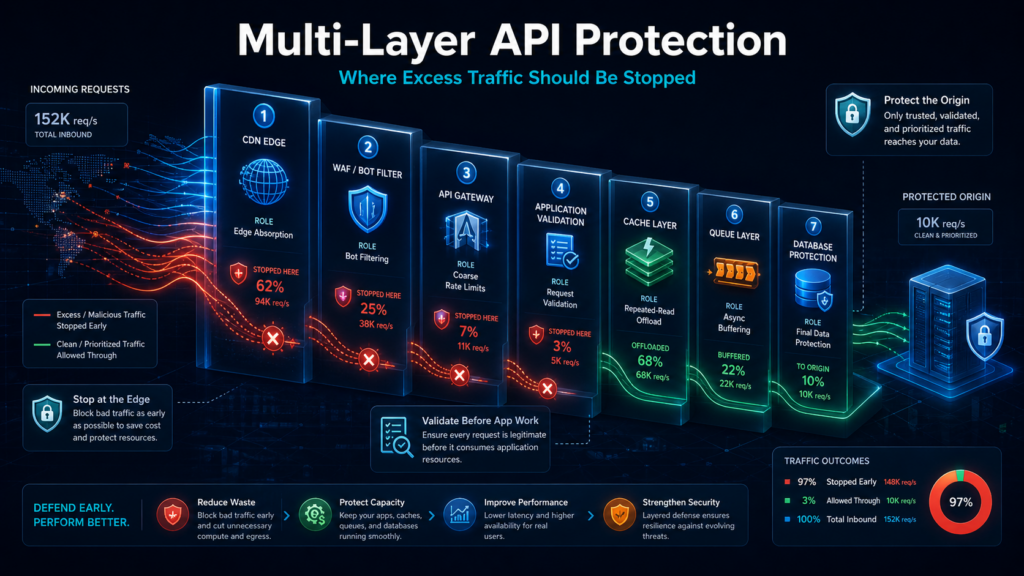
Если смотреть на API только как на входную точку в приложение, защита неизбежно съезжает ближе к коду и базе. Это дорого: к моменту, когда запрос дошёл до бизнес-логики, он уже занял соединение, поток выполнения, память, место в логах и, возможно, начал транзакцию.
Поэтому устойчивость строится как цепочка фильтров. Ранние слои принимают более грубые, но дешёвые решения. Поздние слои работают точнее, потому что видят больше контекста, но каждый ошибочно допущенный запрос там уже стоит дороже.
Почему фильтровать нужно раньше
Здесь подойдёт одна хорошая аналогия, а именно — аэропорт. Часть людей не попадает внутрь из-за базовой проверки на входе, часть быстро проходит стандартный контроль, а часть уходит на дополнительную проверку. В API роль таких зон выполняют пограничный уровень, API Gateway, приложение, кэш, очередь, обработчики и нижележащие сервисы.
Цепочка выглядит так:
- CDN/WAF — отсекает очевидный мусор и часть подозрительных всплесков.
- API Gateway — проверяет ключи, маршруты, методы и базовые лимиты.
- Приложение — принимает решения с учётом пользователя, тарифа, клиента и типа операции.
- Кэш — снимает повторную работу с приложения и базы.
- Очередь — переводит тяжёлые операции в контролируемую фоновую обработку.
- Обработчики — выполняют задачи с ограниченной параллельностью.
- БД и внешние сервисы — остаются последним и самым дорогим участком системы.
Смысл такой цепочки не в том, чтобы любой запрос обязательно дошёл до базы. Наоборот, большинство решений должно приниматься раньше: что заблокировать, что отдать из кэша, что ограничить, а что поставить в очередь.
Чтобы эта схема работала, слои не должны дублировать друг друга вслепую. У каждого из них своя задача, свой уровень контекста и своя цена ошибки.
Как распределяются роли между слоями
На уровне CDN и WAF система отсекает ботов, подозрительные шаблоны, часть DDoS-подобных всплесков и некорректные запросы. Там же можно обслужить кэшируемые GET-запросы без обращения к исходному серверу. Решение здесь может быть грубым, зато оно дешёвое: лучше не пустить заведомо лишнее, чем тащить его в серверную часть.
API Gateway работает ближе к сервисам. Он проверяет ключи, маршруты, методы, окружения и базовые правила доступа. Gateway ещё не знает всех деталей тарифа или состояния клиента, но хорошо подходит для технической дисциплины на входе: кто имеет право вызвать маршрут, с каким методом и в каком объёме.
Приложение принимает более точные решения. Оно уже понимает, кто пользователь, какой у него тариф, к какому клиентскому контуру он относится, какая операция выполняется и можно ли её делать прямо сейчас. Здесь появляется бизнес-контекст, но и цена ошибки выше: запрос уже дошёл до серверной части.
Дальше кэш снижает повторную нагрузку на приложение и базу, очередь переводит тяжёлые операции в управляемую обработку, а обработчики, пулы соединений, таймауты и circuit breaker защищают БД и внешние API от каскадного отказа. Circuit breaker — это механизм, который временно прекращает вызовы к нестабильной зависимости, если ошибки или задержки превысили заданный порог.
Эта карта слоёв показывает, где лишний трафик должен останавливаться. Но она ещё не задаёт сами правила допуска. Поэтому дальше важно отдельно разобрать rate limiting: почему лимиты на CDN, API Gateway и в приложении не заменяют друг друга, а закрывают разные риски.
Rate limiting на CDN, API Gateway и в приложении: почему нужен не один лимит, а несколько

После общей карты защиты входные лимиты проще рассматривать не как одно правило «N запросов в секунду», а как несколько фильтров с разной точностью. Один слой отсеивает грубый мусор, другой следит за техническими ограничениями API, третий учитывает тариф, клиента и стоимость конкретной операции.
Главный принцип простой: чем ближе слой к краю сети, тем дешевле отказ. Чем ближе слой к бизнес-логике, тем точнее решение. Поэтому лимиты на CDN/WAF, API Gateway и в приложении не заменяют друг друга, а закрывают разные риски.
Например, пограничный слой может быстро ограничить подозрительный всплеск по IP, стране, пути или заголовкам. Но он обычно не понимает, какой у клиента тариф, сколько ресурсов стоит операция и можно ли конкретному пользователю выполнять её прямо сейчас. Эти решения появляются уже ближе к приложению.
Поэтому лимиты лучше распределять по слоям. Таблица ниже показывает, какую роль каждый уровень играет в общей защите API:
| Уровень | Что защищает | Ключи лимитирования | Сильные стороны | Ограничения |
| CDN/WAF | Исходный сервер от ботов, злоупотреблений, подозрительных всплесков | IP, страна, URI, заголовки, шаблоны поведения | Рано и дёшево отсекает мусорный трафик | Не знает тариф, пользователя и стоимость операции |
| API Gateway | Контур API: ключи, маршруты, окружения, регионы | Ключ API, маршрут, метод, окружение, регион | Удобно задаёт техническую дисциплину и возвращает стандартный "429" | Не всегда понимает, насколько дорог запрос внутри приложения |
| Приложение | Тарифы, квоты, справедливое распределение ресурсов, защиту от «шумного соседа» | Пользователь, клиентский контур, тариф, тип операции, бизнес-квота | Видит контекст и может отличить дешёвый запрос от тяжёлой операции | Запрос уже дошёл до серверной части и занял часть ресурсов |
Вывод из сравнения простой: ранние уровни защищают инфраструктуру от лишнего трафика, поздние — бизнес-правила и ресурсы конкретных клиентов. Если оставить только CDN, система будет плохо понимать тарифы, квоты и стоимость отдельных операций. Если оставить только приложение, лишний трафик уже успеет занять часть серверных ресурсов.
Представим партнёра, который резко увеличил число вызовов по своему ключу API. API Gateway фиксирует превышение технического лимита и возвращает 429 Too Many Requests вместе с Retry-After, чтобы клиент понимал, когда повторить запрос. Но этого недостаточно для полной защиты: приложение всё равно должно отдельно учитывать тариф, клиентский контур и тип операции.
Именно здесь появляется разница между дешёвым и дорогим запросом. Например, частая проверка статуса обычно легче для системы: она может быстро вернуть короткий ответ и не затронуть критичные зависимости. А массовая генерация отчётов — совсем другой случай. Такая операция может занять базу данных, обработчики, память и внешние сервисы, поэтому её лучше ограничить, отложить или перевести в очередь.
Поэтому rate limiting нельзя строить только вокруг запросов в секунду. Ограничение частоты отвечает за допуск: кого, сколько и на каких условиях пускать внутрь. Но оно не заменяет кэширование, очереди, таймауты и деградацию. Лимиты решают, какой поток попадёт в систему, а следующие механизмы определяют, как этот поток будет обслуживаться без перегруза.
Кэширование: как снять повторную работу с API и базы
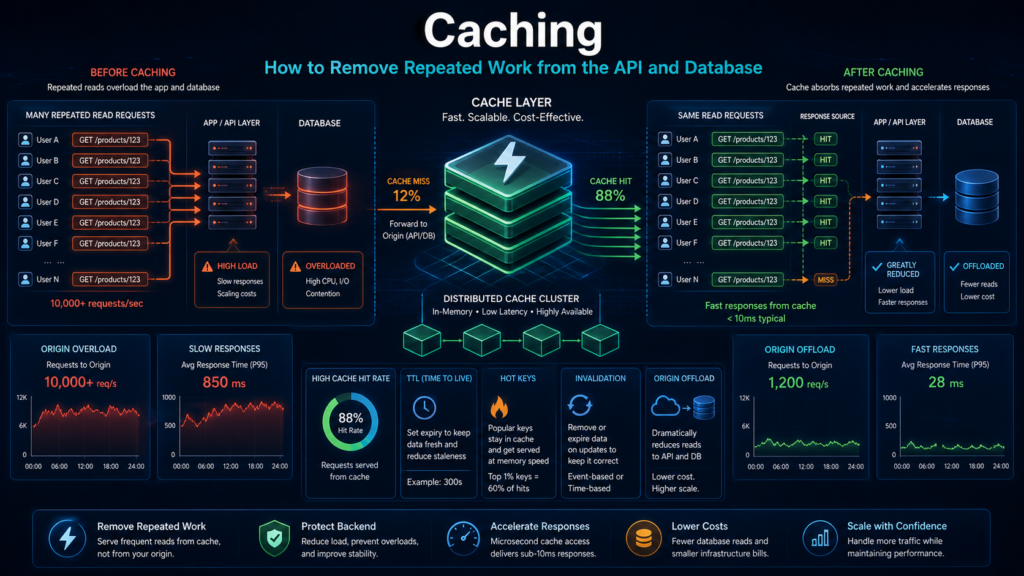
Rate limiting решает, какие запросы вообще допустить в систему. Но допущенный запрос не обязан каждый раз доходить до приложения и базы. Если после email-кампании тысячи пользователей открывают один и тот же каталог, список предложений или страницу со статусом, без кэша система снова и снова повторяет одну и ту же работу: маршрутизацию, бизнес-логику, запросы к БД и подготовку ответа.
Кэширование снижает не только задержку для пользователя, но и фактическую стоимость обслуженного трафика. Чем больше повторяемых ответов система отдаёт без обращения к дорогим слоям, тем меньше нагрузка на приложение, базу данных и внутренние сервисы.
Где должен срабатывать кэш
Кэш полезно разделять по месту, где он останавливает запрос. Чем ближе к краю сети сработал кэш, тем меньше работы дошло до приложения и базы. Чем ближе к приложению, тем больше контекста можно учесть, но тем дороже становится промах.
| Уровень кэша | Для чего подходит | Что важно проверить |
| CDN | Публичные и условно публичные данные: каталоги, лендинговые страницы, справочники, ответы без персонального контекста | Ответ не должен зависеть от конкретного пользователя или приватных данных |
| API Gateway | Повторяемые ответы по стабильным маршрутам и ограниченному набору параметров | Ключ кэша должен безопасно учитывать метод, путь и параметры запроса |
| Приложение или Redis-подобный слой | Данные с бизнес-контекстом: клиентский контур, тариф, регион, права доступа, дорогие агрегаты | Ключ кэша должен учитывать контекст, иначе есть риск отдать данные не тому клиенту |
Такой подход помогает не спорить, “где кэшировать всё”. Разные уровни решают разные задачи. CDN хорошо снимает массовые повторные чтения, API Gateway помогает с типовыми ответами на уровне API, а кэш приложения подходит там, где нужен бизнес-контекст.
Но кэширование работает только там, где результат можно безопасно переиспользовать. Если пользователь запускает уникальную или тяжёлую операцию — например, генерацию отчёта, массовую выгрузку, пересчёт данных или обработку платежей, — кэш уже не снимает нагрузку. Такую работу нужно не повторно отдавать из памяти, а выполнять с контролируемой скоростью. Для этого используется очередь и асинхронная обработка.
Очереди и асинхронная обработка: как сгладить пик, а не передать его базе
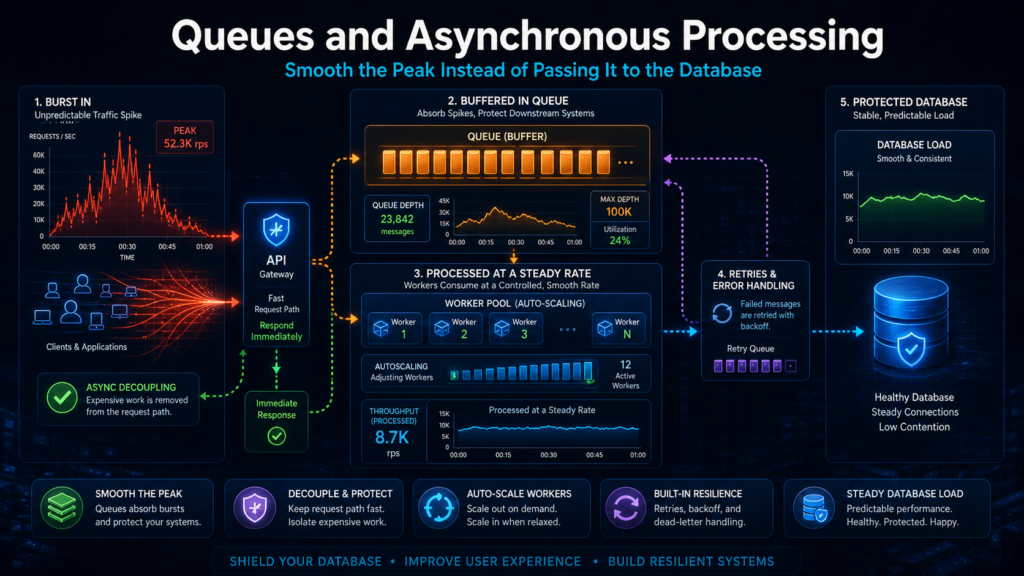
Очередь нужна там, где операция не обязана завершаться сразу в рамках одного HTTP-запроса. Если задача занимает секунды или минуты, невыгодно держать клиента, поток приложения, соединение к базе и внешние сервисы в ожидании результата.
Представим книжный интернет-магазин. Пользователь открывает карточку книги, проверяет статус заказа или читает список рекомендаций — такие операции должны выполняться быстро. Но генерация большого PDF-отчёта, массовая выгрузка каталога или обработка партии платежей могут уйти в фоновую обработку.
В такой схеме API принимает задачу, ставит её в очередь и сразу сообщает клиенту, что работа принята. Результат появляется позже: по идентификатору задачи, через уведомление или вебхук. Чтобы было проще читать дальнейшую схему, зафиксируем основные ответы и элементы асинхронного API:
| Элемент или ответ | Что означает | Зачем нужен |
| 202 Accepted | Задача принята, но ещё не выполнена | Подходит для отчётов, выгрузок и долгих операций |
| Идентификатор задачи | Уникальный номер принятой задачи | Позволяет позже проверить статус и получить результат |
| Запрос статуса задачи | Отдельная проверка состояния обработки | Не нужно держать исходное соединение открытым |
| Вебхук | Уведомление клиенту после завершения задачи | Клиент получает результат без постоянных проверок |
| 429 Too Many Requests | Клиент превысил лимит запросов или задач | Ограничивает слишком активных клиентов |
| 503 Service Unavailable | Система или зависимость временно перегружена | Лучше честно отказать, чем принять невыполнимую работу |
| Retry-After | Подсказка, когда повторить запрос | Помогает не создавать лишние повторные запросы |
В пиковые периоды очередь защищает самые дорогие участки системы: базу данных, платёжного провайдера, генератор отчётов или внешнюю интеграцию. Без очереди всплеск сразу давит на эти зависимости. С очередью входящий поток может быть выше скорости обработки, но задачи выполняются постепенно и с ограниченной параллельностью.
Рабочая схема обычно включает:
- Очередь задач — принимает работу, которую нельзя или невыгодно выполнять сразу;
- Обработчики — забирают задачи из очереди и выполняют их;
- Накопленную очередь — количество задач, ожидающих обработки;
- Задержку обработки — время между постановкой задачи и результатом;
- Очередь ошибок — место для задач, которые не удалось обработать после нескольких попыток.
Но очередь не делает систему бесконечно мощной. Если книжный магазин принял десять тысяч задач на генерацию отчётов, а обработчики могут выполнить только тысячу за разумное время, проблема не решена — она просто спрятана.
Поэтому масштабировать обработчики бесконечно тоже нельзя. Слишком много обработчиков могут добить базу или внешний API параллельными вызовами. Масштабирование должно учитывать не только длину очереди, но и лимиты зависимостей: соединения к базе, допустимую частоту внешних вызовов, стоимость операции и приоритет клиента.
Для быстрых операций синхронный ответ можно оставить: получить статус, прочитать кэшируемые данные, создать простую сущность. Тяжёлые задачи лучше принимать асинхронно: вернуть 202 Accepted, идентификатор задачи, текущее состояние и способ проверить результат.
Если очередь переполнена или задержка стала слишком большой, честный 429 или 503 с Retry-After лучше, чем молчаливое накопление задач, которые всё равно не будут обработаны вовремя.
Схема обработки пиковых нагрузок
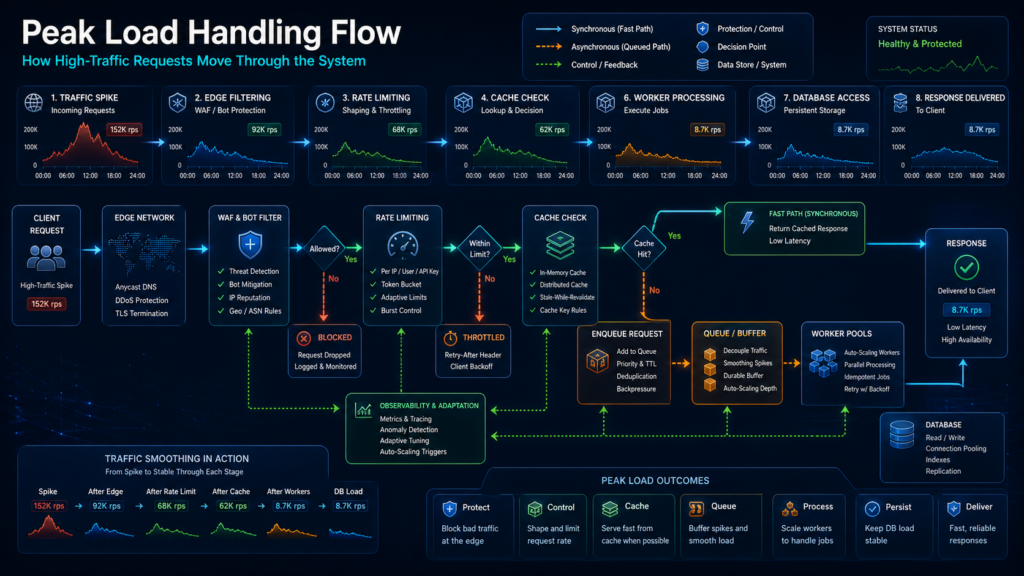
После лимитов, кэша и очередей поведение API под всплеском можно собрать в единую схему. Но это должна быть не диаграмма ради диаграммы, а понятный порядок решений: что отсекается на входе, что обслуживается дёшево, что откладывается, а где система сознательно ухудшает ответ, чтобы не упасть целиком.
Представим тот же книжный интернет-магазин. После рассылки или сезонной акции пользователи массово открывают карточки книг, проверяют наличие, добавляют товары в корзину, запускают выгрузки и обновляют статус заказов. Если отправить весь этот поток напрямую в приложение и базу, пик быстро станет хаотичным. Поэтому нагрузку нужно разбирать по этапам.
Шаг 1. Отсеять лишнее на входе
Первым делом система должна остановить то, что вообще не должно доходить до приложения: ботов, подозрительные шаблоны, грубые превышения лимитов, некорректные запросы и явно лишний трафик. Эту работу выполняют CDN/WAF и API Gateway.
На этом этапе решение может быть грубым, но дешёвым. Например, если один источник слишком часто запрашивает одни и те же страницы или перебирает маршруты API, его лучше ограничить до того, как он займёт ресурсы приложения. Если клиент превысил допустимую частоту запросов, API Gateway может вернуть 429 Too Many Requests и Retry-After.
Главная задача первого шага — не “спасти” весь полезный трафик, а не пустить внутрь очевидно лишний. Чем раньше система отсекает мусор, тем меньше нагрузка на дорогие слои.
Шаг 2. Отдать повторяемое без обращения к базе
После фильтрации остаётся нормальный пользовательский трафик. Но даже он не обязан каждый раз доходить до базы. В книжном магазине многие пользователи открывают одни и те же карточки популярных книг, подборки, справочники, страницы акции или списки рекомендаций.
Если эти данные можно безопасно переиспользовать, их лучше отдавать из кэша. Тогда приложение и база не повторяют одну и ту же работу тысячи раз. Пользователь получает ответ быстрее, а система сохраняет ресурсы для операций, которые действительно требуют свежих данных.
На этом шаге важно не кэшировать всё подряд. Персональные данные, состояние заказа, права доступа и быстро меняющиеся остатки требуют осторожности. Кэш должен снимать повторяемую работу, а не создавать риск устаревших или чужих данных.
Шаг 3. Отложить тяжёлые операции
Часть запросов нельзя просто отдать из кэша. Например, пользователь запускает большую выгрузку заказов, формирование PDF-отчёта, массовое обновление данных или операцию, которая зависит от внешнего сервиса. Такие задачи лучше не выполнять синхронно в рамках одного запроса.
API принимает задачу, возвращает 202 Accepted и идентификатор, а обработчики выполняют работу позже с ограниченной параллельностью. Так пик не исчезает, но становится управляемым: очередь показывает, сколько задач накопилось, как быстро они обрабатываются и когда задержка становится опасной.
Если очередь уже переполнена, честный отказ лучше молчаливого накопления. В этом случае API может вернуть 429 или 503 с Retry-After, чтобы клиент не создавал ещё больше повторов.
Шаг 4. Защитить зависимости и заранее выбрать деградацию
Даже после лимитов, кэша и очередей остаются самые дорогие зависимости: база данных, платёжный провайдер, поисковый сервис, внешние API и внутренние обработчики. Их нужно защищать таймаутами, ограничением параллельности, пулами соединений и circuit breaker.
Если зависимость начинает отвечать медленно или ошибаться, система не должна бесконечно ждать и накапливать зависшие запросы. Лучше временно ограничить часть функций: отключить дорогую сортировку, вернуть агрегаты за предыдущую минуту, скрыть неприоритетные поля, принять отчёт в очередь вместо синхронной генерации или ограничить низкоприоритетные клиентские контуры.
В такой схеме пик не исчезает, но перестаёт быть хаотичным: часть запросов отсекается, часть обслуживается из кэша, тяжёлые операции уходят в очередь, а самые дорогие зависимости получают ограниченную и предсказуемую нагрузку.
Но наличие CDN, кэша, очереди и обработчиков ещё не гарантирует устойчивость. API всё равно может ломаться, если компоненты масштабируются без общей модели стоимости, лимитов и приоритетов. Поэтому дальше важно разобрать типовые ошибки, из-за которых даже формально “правильная” архитектура начинает передавать пик в базу, внешние сервисы или очередь.
Типовые ошибки при масштабировании API
Даже если в архитектуре уже есть CDN, API Gateway, кэш, очередь и обработчики, система всё равно может ломаться под пиком. Чаще всего проблема не в отсутствии отдельного инструмента, а в том, что каждый компонент масштабировали сам по себе: приложение отдельно, очередь отдельно, базу отдельно, лимиты отдельно.
Для high-load API важно не просто “добавить больше ресурсов”, а понимать, куда пойдёт нагрузка после каждого решения. Если книжный интернет-магазин увеличит число контейнеров приложения, но не ограничит обращения к базе, пик не исчезнет. Он просто быстрее доберётся до самого слабого места.
Ошибка 1. Масштабировать приложение, но забыть про зависимости
Самый простой соблазн — добавить больше контейнеров или инстансов приложения. Кажется логичным: если пользователей стало больше, нужно больше серверов. Облако действительно быстро поднимет дополнительный слой приложения, но база данных, внешний API, брокер сообщений, платёжный сервис и пулы соединений не становятся бесконечными.
Представим, что инженер Джон видит рост трафика после акции в книжном магазине и увеличивает число экземпляров приложения в три раза. Первые минуты всё выглядит лучше: приложение быстрее принимает запросы. Но затем каждый новый экземпляр начинает активнее ходить в одну и ту же базу, платёжный провайдер и сервис рекомендаций. В итоге приложение масштабировалось, а узкое место стало получать ещё больше параллельных вызовов.
Такое масштабирование не решает проблему, а иногда ускоряет отказ. Перед увеличением слоя приложения нужно понимать лимиты зависимостей: сколько соединений выдерживает БД, сколько запросов принимает внешний API, сколько задач реально обработают воркеры и где должен сработать отказ или очередь.
Ошибка 2. Считать все запросы одинаковыми
Лимит “100 запросов в секунду” выглядит аккуратно только на бумаге. В реальности один запрос может просто проверить статус заказа, а другой — запустить тяжёлую агрегацию, сформировать отчёт, обратиться к базе и внешнему сервису.
Если система считает их одинаковыми, активный клиент может формально не нарушать лимит, но всё равно создавать несоразмерную нагрузку. Например, партнёр книжного магазина не делает тысячи запросов в секунду, но массово запускает выгрузку статистики по продажам. По числу запросов всё выглядит допустимо, а по стоимости операций система уже перегружена.
Чтобы лимиты были полезными, запросы нужно сравнивать не только по количеству, но и по примерной стоимости для системы:
| Тип операции | Как выглядит для клиента | Реальная стоимость для API |
| Проверка статуса заказа | Быстрый короткий ответ | Низкая: часто можно отдать из кэша или простой выборкой |
| Открытие карточки книги | Обычное чтение данных | Средняя: зависит от кэша, БД и персонализации |
| Генерация отчёта | Один запрос на выгрузку | Высокая: БД, агрегации, память, обработчики |
| Массовая синхронизация каталога | Несколько запросов от партнёра | Высокая: много записей, внешние API, очередь, блокировки |
Поэтому лимиты должны учитывать не только частоту, но и тип операции, маршрут, клиента, тариф и примерную стоимость запроса. Дешёвое чтение и тяжёлая генерация отчёта не должны жить под одним и тем же правилом.
Ошибка 3. Держать тяжёлые операции синхронными
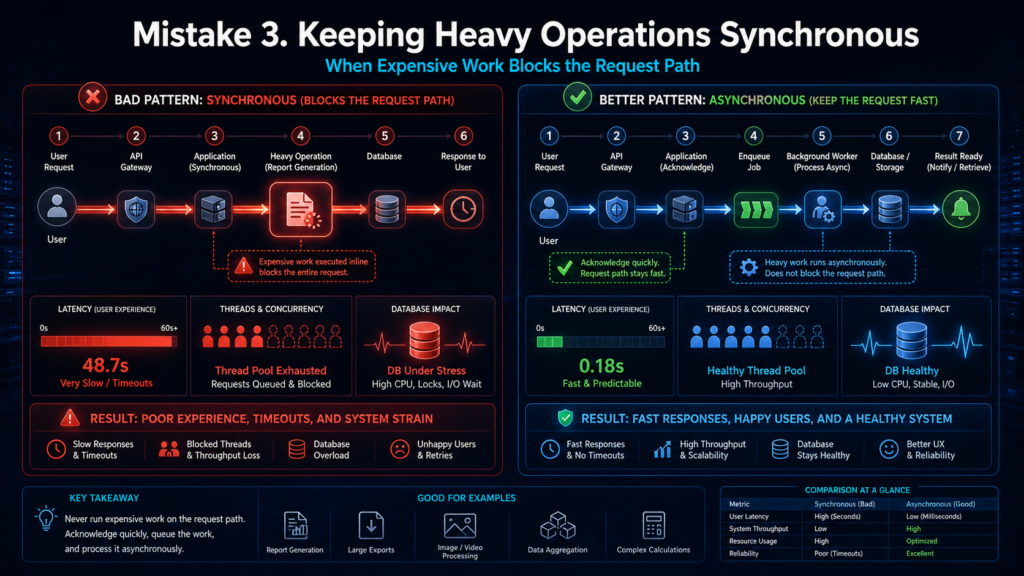
Другая частая ошибка — пытаться выполнить долгую операцию прямо внутри одного HTTP-запроса. Пользователь нажал кнопку, приложение начало формировать отчёт, держит соединение, ждёт базу, обращается к внешним сервисам и надеется успеть до таймаута.
Под пиком такая схема быстро ломается. Клиент не получает ответ, повторяет запрос, задача запускается ещё раз, нагрузка растёт, а система начинает дублировать работу. Для книжного магазина это может означать повторную генерацию одного и того же отчёта, дубли задач на обновление каталога или лишние обращения к платёжному сервису.
Такие операции лучше переводить в асинхронный контракт:
- Принять задачу и вернуть клиенту идентификатор;
- Показать текущее состояние обработки;
- Дать способ получить результат позже;
- Ограничить повторные запуски одной и той же операции;
- Вернуть честный отказ, если очередь уже перегружена.
Это не делает тяжёлую операцию бесплатной, но отделяет пользовательский запрос от внутреннего времени обработки.
Ошибка 4. Прятать проблему за очередью
Очередь помогает сгладить пик, но она не должна становиться складом задач, которые система всё равно не успеет выполнить. Длина очереди сама по себе мало что говорит без скорости обработки и допустимого времени ожидания.
Например, книжный магазин принимает десять тысяч задач на выгрузку отчётов. Очередь растёт, но обработчики справляются только с небольшой частью. Формально API продолжает принимать задачи, но пользователи ждут результат не минуты, а часы. В этот момент очередь уже не защищает систему, а скрывает невыполнимые обещания.
Чтобы понять, помогает очередь или уже маскирует проблему, нужно смотреть на несколько показателей одновременно:
| Что смотреть | Показывает сколько | Почему важно |
| Длина очереди | Задач ждёт обработки | Помогает увидеть накопление работы |
| Задержка обработки | Времени задача ждёт результата | Показывает реальный опыт клиента |
| Скорость поступления | Задач приходит за период | Показывает силу входящего потока |
| Скорость обработки | Задач завершается за период | Показывает реальную пропускную способность |
| Доля ошибок | Сколько задач уходит в ошибки | Помогает понять, не ломается ли обработка |
Если задержка вышла за допустимый предел, API должен ограничить приём новых задач, вернуть честный отказ или изменить контракт. Продолжать принимать работу бесконечно — значит превращать очередь в накопитель будущих проблем.
Ошибка 5. Кэшировать без правил консистентности
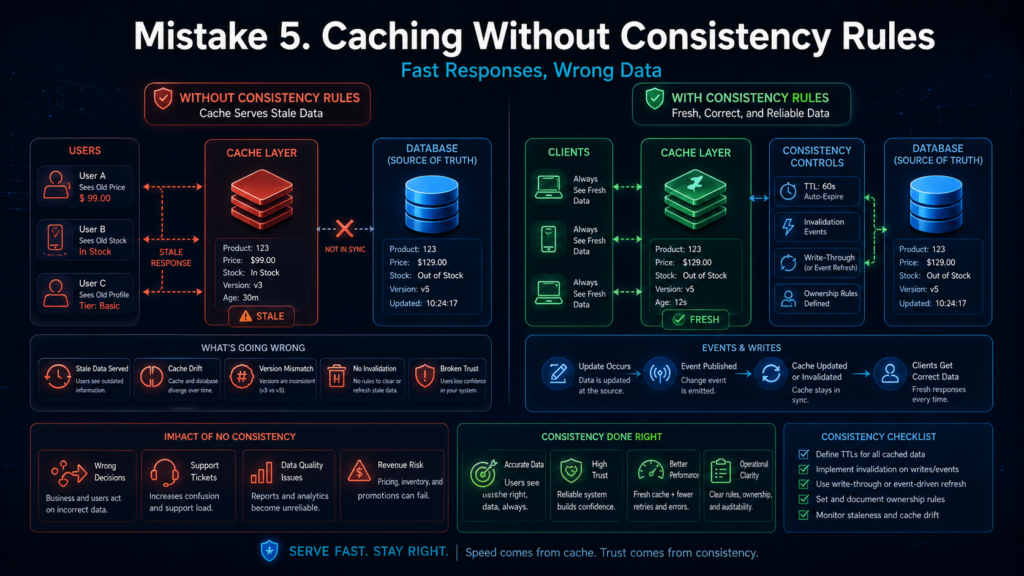
Кэш может сильно снизить нагрузку, но только если понятно, какие данные можно переиспользовать и как долго они остаются корректными. Без такой модели кэш превращается в источник ошибок.
Например, книжный магазин долго кэширует карточки товаров, но не учитывает, что остатки на складе быстро меняются. Пользователь видит книгу в наличии, добавляет её в корзину, а при оформлении оказывается, что товара уже нет. Ещё опаснее кэшировать персональные ответы без строгого ключа: так можно случайно отдать данные одного клиента другому.
Проблемы возникают и при лавине промахов: срок жизни популярной записи истёк, и сотни запросов одновременно пошли пересчитывать один и тот же объект. Поэтому для кэша нужны понятные ключи, сроки жизни, инвалидация и правила для популярных данных под пиком.
Ошибка 6. Не задавать бюджеты времени и отказа
Высокая нагрузка опасна не только количеством запросов, но и медленными зависимостями. Один внешний сервис может начать отвечать дольше обычного, и приложение будет терпеливо ждать. Потом таких ожидающих запросов станет много, рабочие потоки закончатся, и проблема одного сервиса потянет за собой весь API.
В книжном магазине это может быть сервис рекомендаций или платёжный провайдер. Если рекомендации недоступны, лучше временно скрыть блок “похожие книги”, чем задерживать всю карточку товара. Если платёжный сервис нестабилен, лучше честно ограничить операции, чем держать все соединения в ожидании.
Для этого нужны базовые правила защиты зависимостей:
- Таймауты, чтобы приложение не ждало внешний сервис бесконечно;
- Ограничение параллельности, чтобы одна зависимость не заняла все рабочие потоки;
- Контролируемые повторы, чтобы не создавать повторный пик;
- Circuit breaker, чтобы временно прекращать вызовы к нестабильному сервису;
- Запасной сценарий ответа, если часть функции можно безопасно ухудшить.
Так API не пытается любой ценой дождаться проблемного сервиса, а переходит в контролируемый режим.
Ошибка 7. Полагаться на повторы без идемпотентности
При ошибках клиенты и внутренние сервисы будут повторять запросы. Это нормально. Проблема начинается, если повтор одного и того же действия создаёт новый заказ, новый платёж или новую задачу.
Например, пользователь оформляет заказ на книгу, получает ошибку из-за таймаута и нажимает кнопку ещё раз. Если операция не защищена, система может создать два заказа или дважды отправить платёжную операцию. Под пиком такие ситуации становятся массовыми.
Для критичных действий нужны идемпотентные ключи: система должна понимать, что повторный запрос относится к той же операции, а не к новой. Это особенно важно для заказов, платежей, массовых задач и интеграций.
Ошибка 8. Не разделять приоритеты клиентов и операций
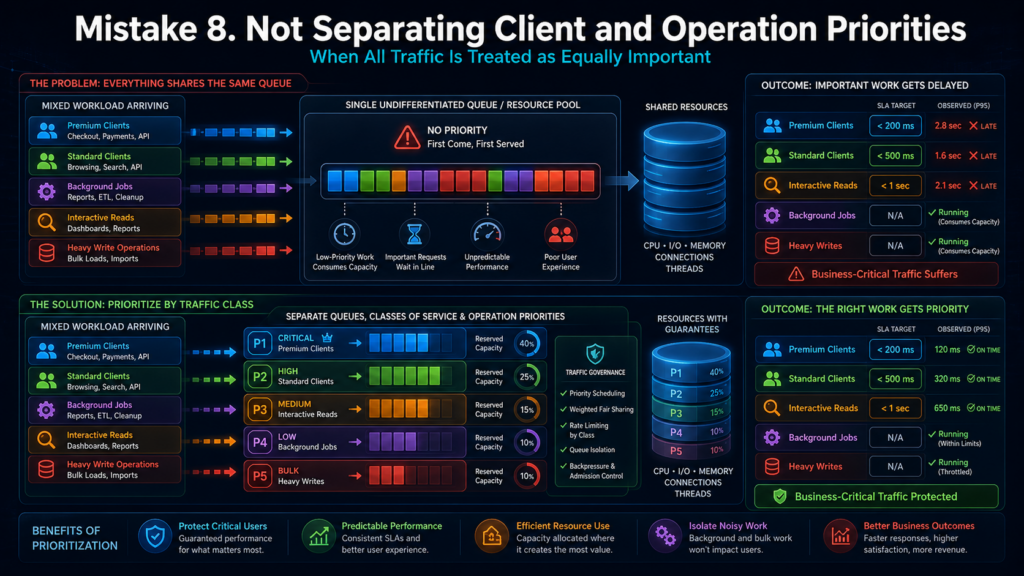
В API с несколькими клиентами один активный клиент может занять непропорционально много ресурсов. Это особенно опасно, если у всех одинаковые лимиты и нет разделения по тарифам, клиентским контурам и типам операций.
Например, крупный партнёр книжного магазина запускает массовую синхронизацию каталога. Если у системы нет квот и приоритетов, эта задача может вытеснить обычных пользователей: страницы открываются медленнее, статусы заказов задерживаются, очередь растёт.
Справедливое распределение нагрузки — это не только коммерческий вопрос. Это механизм устойчивости. API должен понимать, какие клиенты и операции критичны, что можно отложить, что ограничить, а что нужно обслужить в первую очередь.
Главная мысль этой главы: масштабирование API должно учитывать стоимость операций и связи между компонентами. CDN, кэш, очередь, обработчики и автомасштабирование работают только тогда, когда они подчинены общей модели: какие запросы допускать, какие обслуживать из кэша, какие откладывать, какие ограничивать и какие зависимости защищать в первую очередь.
Заключение
Устойчивый high-load API строится не вокруг идеи «принять как можно больше запросов», а вокруг контроля нагрузки. Повторяемые запросы лучше отдавать из кэша, лишний трафик — отсекать на ранних слоях, а тяжёлые операции — переводить в очередь, чтобы они не давили напрямую на базу данных и внешние сервисы.
Облако помогает масштабировать API, но само по себе не делает систему устойчивой. Если заранее не задать лимиты, таймауты, правила очередей, кэширования и деградации, пик всё равно дойдёт до самого слабого места. Хорошая архитектура не обещает бесконечную пропускную способность — она делает поведение системы под нагрузкой предсказуемым.
FAQ
Где лучше ставить rate limiting: на CDN, API Gateway или в приложении?
На всех трёх уровнях, но с разными задачами. CDN/WAF отсекает грубый и подозрительный трафик, API Gateway ограничивает вызовы по ключам и маршрутам, приложение применяет бизнес-лимиты по пользователям, тарифам, клиентским контурам и типам операций.
Когда API должен возвращать "429 Too Many Requests"?
Когда клиент превысил допустимую частоту, квоту или бизнес-лимит, но сама система остаётся работоспособной. Желательно возвращать "Retry-After", чтобы клиент мог корректно отложить повтор. Если же перегружена вся инфраструктура или зависимость временно недоступна, чаще уместнее "503 Service Unavailable" с тем же "Retry-After".
Всегда ли тяжёлые операции нужно отправлять в очередь?
Нет. Если операция стабильно укладывается в бюджет ответа, не блокирует критичные ресурсы и не создаёт риска каскадного отказа, её можно оставить синхронной. Очередь нужна там, где операция дорогая, долгая, зависит от внешних систем или может массово повторяться во время пиков.
Что важнее для high-load API: кэш или горизонтальное масштабирование?
Это разные инструменты. Горизонтальное масштабирование помогает увеличить число рабочих экземпляров приложения, но не отменяет стоимость запросов к БД и внешним сервисам. Кэширование уменьшает сам объём повторной работы. В реальной архитектуре обычно нужны оба механизма, но кэш часто даёт больший эффект для повторяемых "GET".
Как понять, что очередь уже не спасает, а скрывает проблему?
Смотрите не только на размер очереди, но и на задержку обработки, процент задач в dead-letter queue, скорость поступления и скорость выполнения. Если задержка стабильно растёт, а новые задачи принимаются без ограничений, очередь перестала сглаживать пик и начала накапливать невыполнимые обещания.
Список источников
1. Cloudflare Docs — Rate limiting rules
2. Microsoft Azure Architecture Center — Queue-Based Load Leveling pattern
3. AWS Well-Architected Framework — REL05-BP02 Throttle requests
4. Google Cloud — Rate Limiting | Service Infrastructure
5. AWS Builders’ Library — Making retries safe with idempotent APIs


