
Когда мы открываем приложение банка, маркетплейса или социальной сети, снаружи все выглядит просто: экран загрузился, кнопки работают, данные появились, платеж прошел, уведомление пришло. Но за этим стоит инфраструктура.
Иногда это десятки серверов. Иногда сотни. А у крупных компаний — тысячи серверов, сотни сервисов, команды разработчиков, DevOps-инженеров, администраторов баз данных, специалистов по информационной безопасности и вообще большое количество людей, которые поддерживают работу продукта.
И тут возникает вопрос: как это вообще так выросло?
Кто все это спроектировал? Сидел ли какой-то архитектор и заранее рисовал схему на 500 сервисов? Или эта сложность появилась сама?
На самом деле крупная IT-инфраструктура почти никогда не возникает сразу в готовом виде. Она растет постепенно. Каждый новый слой появляется в ответ на конкретную проблему: сервер упал, база начала тормозить, пользователей стало больше, деплой стал опасным, команде стало тесно в старых процессах, появились требования к доступности, безопасности или законодательству.
Представим для чистоты схемы, что у нашей условной IT-компании есть достаточно денег, чтобы не экономить на правильных решениях. Не в смысле «купим серверов на миллиард», а в смысле — если нужно сделать правильно, у нас есть возможность это сделать. В реальной жизни компании часто срезают углы из-за бюджета, и это нормально. Но чтобы проследить эволюцию инфраструктуры без лишних компромиссов, пойдем по идеальному пути.
Все начинается не с серверов, а с идеи
На самом деле инфраструктура начинается не с Kubernetes, не с облаков и не с дата-центров. Она начинается с человека и идеи.
Есть условный Вася. У него появляется мысль: сделать приложение, которое выполняет какую-то полезную функцию. Пока не важно, что это — сервис доставки, B2B-платформа, маркетплейс, социальная сеть или что-то еще.
На этом этапе нет ничего:
- нет кода;
- нет серверов;
- нет пользователей;
- нет команды;
- нет базы данных;
- нет DevOps;
- нет мониторинга;
- нет сложной архитектуры.
Есть только компьютер, голова и желание сделать продукт. И этого достаточно, чтобы начать.
Люди часто думают, что настоящая инфраструктура начинается с Kubernetes и облаков. Но на практике все гораздо проще. Настоящая инфраструктура часто начинается с обычной VPS за 500 рублей. А все серьезное появляется уже потом — когда без него становится невозможно.

Первый этап: локальное приложение нужно выкатить в интернет
Вася написал первую версию приложения. Оно работает у него локально на компьютере. Следующий шаг очевиден: приложение нужно показать пользователям, то есть выкатить в интернет.
Для этого Вася арендует VPS — виртуальный сервер у какого-нибудь хостинг-провайдера. Потом покупает домен и настраивает DNS, чтобы этот домен вел на правильный IP-адрес сервера.
Дальше ему нужно развернуть приложение на сервере. Он может сделать это в Docker, а может поставить приложение прямо на сервер без контейнеров. На этом этапе это не принципиально. Главное, что у него появляется сервер, на котором работает приложение и какая-то база данных.
Затем нужно настроить TLS с бесплатным сертификатом, чтобы пользователи могли нормально открывать сайт по HTTPS. Плюс Вася ставит Nginx, чтобы все работало правильно.
Первый этап завершен:
- приложение доступно в интернете;
- есть домен;
- DNS настроен;
- TLS работает;
- Nginx стоит;
- база данных находится рядом с приложением;
- появляются первые пользователи.
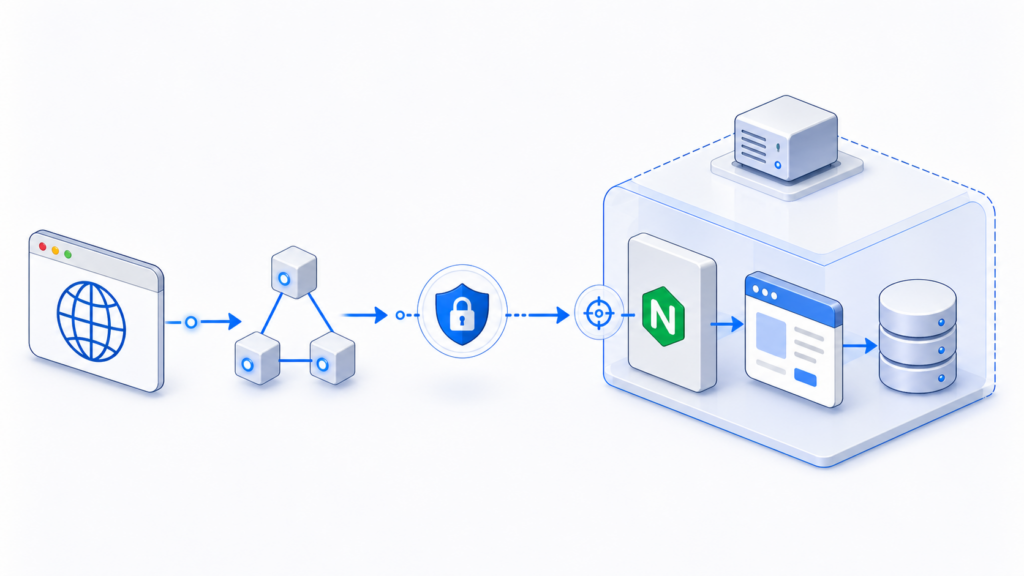
На этом этапе Вася один. Он и разработчик, и DevOps, и саппорт, и владелец бизнеса. Это абсолютно нормальный MVP. Большинство стартапов начинают примерно так.
Первые пользователи и первые проблемы
Проходит три месяца. У Васи уже не 10 пользователей, а 500. Кто-то рассказал знакомым, кто-то увидел продукт в соцсетях, где-то сработала реклама. Продукт живет.
И тут начинаются первые проблемы.
Проблема первая: сервер упал ночью
Сервер упал, Вася спал, сайт лежал 6 часов. Утром он проснулся, увидел кучу сообщений в поддержке, зашел на сервер и перезагрузил его. Все снова заработало.
Но пользователи уже успели разозлиться.
Главный вывод: если сервис падает, об этом нужно узнавать сразу, а не через несколько часов от пользователей.
Проблема вторая: база данных растет
База данных начинает занимать все больше места. Вася видит, что диск забит уже на 80%. Значит, скоро придется расширять диск или думать, что делать с ростом данных.
Пока это еще не катастрофа, но уже понятный сигнал: инфраструктуру нужно контролировать.
Проблема третья: деплой может сломать приложение
Рано или поздно Вася делает обновление, деплоит его — и что-то ломается. Когда пользователей было мало, это казалось терпимым. Но теперь любой сломанный деплой заметен людям.
Значит, нужно менять подход.

Первые инфраструктурные решения: мониторинг, бэкапы, автозапуск
На этом этапе появляются первые обязательные элементы нормальной инфраструктуры.
- Первое — мониторинг. Пока самый простой: проверять, что сайт жив, и если что-то не так, присылать alert. Главная задача — не допустить ситуации, когда сервис лежит 6 часов, а владелец узнает об этом только утром.
- Второе — бэкапирование. Самое главное, чтобы оно было регулярным. Так как проект еще небольшой, достаточно раз в сутки делать бэкап базы. Иногда можно делать бэкап всего сервера целиком.
- Третье — автозапуск. Если сервер перезагрузился, сервисы должны подняться сами. Приложение, база и все нужные процессы не должны зависеть от того, зайдет ли Вася руками и запустит их.
И тут появляется еще одна важная проблема. Сервер теперь боевой. Там постоянно сидят пользователи. Значит, проверять изменения прямо на production уже нельзя.
Вася поднимает вторую VPS. На ней находится копия production. Это отдельное окружение для разработки. Теперь он может сначала проверять изменения там, а потом катить их в прод.
На этом этапе Вася все еще один, но уже начинает понимать, что вдвоем было бы легче.
Появляется команда: код, доступы, CI/CD и тикетница
Продукт растет, нагрузка увеличивается, задач становится больше. В какой-то момент одному уже невозможно справляться. Вася нанимает двух разработчиков.
И тут появляется первый управленческий вопрос: где хранить код?
До этого Вася мог держать все в приватном репозитории GitHub. Для трех разработчиков это тоже может работать. Но возникает вопрос: оставаться на публичном GitHub или GitLab Cloud либо поднимать свой GitLab?
Для старта оставаться на публичном сервисе нормально. Self-hosted GitLab требует ресурсов, времени на поддержку и отдельного внимания. Для трех человек это может быть избыточно. Поэтому команда остается на GitHub или GitLab Cloud, но использует приватные репозитории.
Следующий вопрос — права доступа.
У Васи есть доступ ко всему. Но новичкам не нужно давать полный доступ везде. Они должны иметь доступ только к своим репозиториям и тем ресурсам, которые нужны им для работы. Доступ к production остается у Васи и, возможно, у более опытного разработчика.
Это базовый принцип: опасно давать root-доступ всем и везде.
На этом же этапе появляется первый CI/CD. Он еще примитивный, но уже существует. Пайплайн делает простые вещи: собрать приложение и задеплоить его.
При этом на production можно пока не деплоить автоматически. Продукт небольшой, и команда может оставить ручной деплой в прод. Автоматизация используется для dev-стенда: туда изменения можно катить проще и быстрее.
Еще одна важная вещь — тикетница.
Когда Вася был один, он мог вести задачи где угодно: в заметках на компьютере, в телефоне, в Telegram или просто в голове. Но когда людей уже несколько, нужно понимать:
- кто что делает;
- какие задачи в работе;
- что уже сделано;
- сколько времени уходит;
- кто за что отвечает.
На этом этапе достаточно простого решения: Trello, Notion, YouTrack или чего-то похожего. Главное — появляется возможность отслеживать процесс.
Сам Вася уже не кодит 100% времени. Он начинает заниматься менеджментом: раздает задачи, контролирует процесс разработки, общается с инвесторами, анализирует пользователей и занимается тем, что должно двигать компанию дальше. Инфраструктура все еще остается на нем, но это уже не единственная его деятельность.

Приложение начинает тормозить: базу нужно вынести отдельно
Проходит еще полгода. Пользователей уже несколько тысяч. Команда выросла до шести человек. И появляется новая проблема: приложение тормозит.
Команда начинает разбираться и выясняет, что база данных потребляет слишком много ресурсов. При этом база живет на одном сервере с приложением. Когда база выполняет тяжелый запрос, приложение начинает отвечать медленно.
Решение очевидно: нужно разнести приложение и базу данных на разные серверы.
Но между этими серверами должна быть приватная сеть. Трафик не должен ходить через интернет. Так появляется новая сущность — приватная сеть. Это может быть VPC или VLAN у провайдера.
Смысл простой:
- приложение и база видят друг друга;
- база недоступна извне;
- в интернет смотрит только приложение;
- внешние запросы идут только по HTTP/HTTPS.
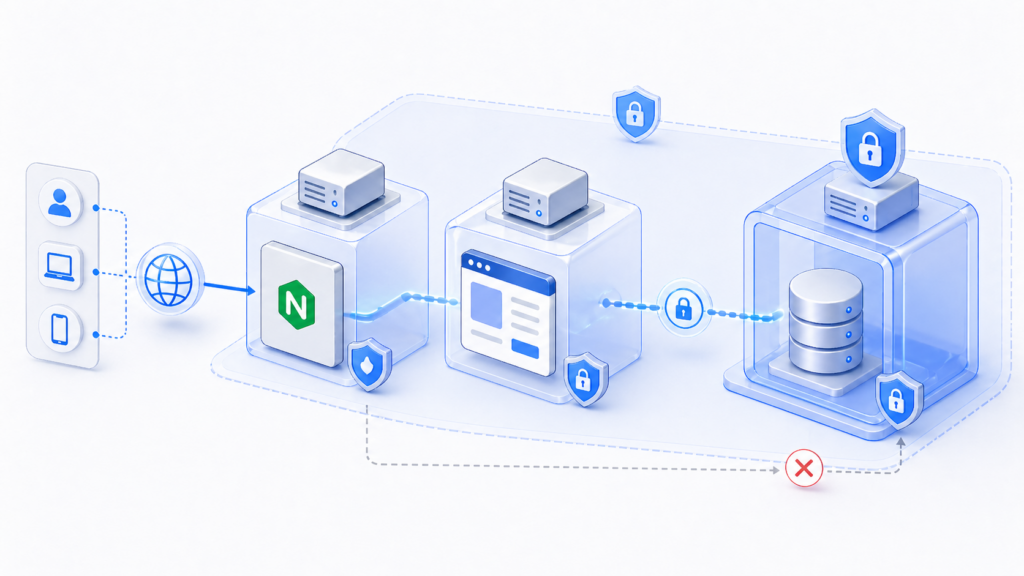
На этом этапе Nginx уже становится полноценным reverse proxy. Раньше он в основном терминировал HTTPS. Теперь он также кэширует статику, сжимает ответы и ограничивает количество запросов с одного IP.
Но остаются две проблемы.
Первая — деплой все еще ручной.
Вторая — миграции базы. Каждый раз, когда нужно изменить схему базы данных, кто-то делает это руками. И всегда есть риск дропнуть какую-нибудь production-таблицу.
Компания продолжает развиваться, команда растет до 10 человек. Один из разработчиков все больше занимается инфраструктурой и постепенно становится полу-DevOps. По сути, это последний этап, когда еще можно обходиться без выделенного DevOps-инженера.
Появляются требования к uptime: один сервер больше не подходит
Бизнес окреп. Появились первые крупные долгосрочные клиенты. Вместе с ними появились требования к доступности. Например, uptime 99,9%.
Это означает, что сайт может быть недоступен максимум около 8 часов в год. С одним сервером это нереально. Любое обновление, любая перезагрузка или любое падение сервера — это сразу downtime.
Значит, нужна новая архитектура.
Первое решение — два сервера приложения. Перед ними ставится балансировщик. Если один сервер падает, трафик идет на второй.
Балансировщик может быть собственным: например, Nginx или HAProxy. А может быть облачным. Это зависит от того, кто занимается инфраструктурой и какое решение он примет.
Второе важное решение — репликация базы данных.
На этом этапе уже критически важно, чтобы база была реплицирована. Записи идут в master, а читать можно и с master, и с replica. Если master падает, replica становится новым master. Так можно избежать критического downtime.
Дальше инфраструктура начинает быстро обрастать новыми сущностями.
Выделяется отдельный сервер для статики. Картинки, CSS и JavaScript уезжают на отдельный сервер или в объектное хранилище, то есть S3. Приложение начинает генерировать только HTML и API-ответы, а статика отдается отдельно, быстро и не мешает основной логике.
Появляется вопрос хранилища образов. До этого Docker-образы можно было хранить в Docker Hub. Но для бизнеса это риск: Docker Hub может ограничить скачивание или заблокировать аккаунт. Значит, нужен свой registry. Например, Harbor, Nexus или GitLab Registry.
Приложение к этому моменту уже давно перестало быть одним монолитным сервисом. Оно состоит из большого числа небольших компонентов. Поэтому возникает необходимость в централизованных логах.
Раньше логи можно было читать как угодно. Но теперь серверов несколько, и так работать больше нельзя. Нужен инструмент, куда будут стекаться логи со всех сервисов. Это может быть Graylog, Loki или ELK-стек. Главное, чтобы логи лились в одно место и по ним можно было искать одновременно.
Инфраструктура растет огромными темпами. Хотя по меркам IT-гигантов это все еще очень маленький масштаб.
Именно здесь появляется первый выделенный DevOps-инженер. До этого DevOps-работой занимался один из разработчиков, но инфраструктура стала слишком сложной, чтобы заниматься ей по остаточному принципу.
На этом же этапе появляются постмортемы. Если происходит инцидент, команда разбирает, почему он случился, и пишет, что нужно сделать, чтобы он не повторился.
Это первый признак зрелой инженерной культуры.

Серверов уже больше 30: приходит Kubernetes
Компания продолжает расти. Продуктов уже два. Серверов больше 30. Команд разработки — три.
Ручное управление инфраструктурой становится все сложнее. Логичным решением становится Kubernetes.
Не все компании обязаны его использовать. Кто-то осознанно остается на Docker Swarm. Кто-то живет на обычных VM с Ansible и Docker. Но если компания планирует дальше расти, Kubernetes часто становится естественным следующим этапом.
Суть Kubernetes в том, что команда описывает в манифестах, как должно быть устроено приложение, а Kubernetes следит, чтобы реальное состояние соответствовало описанному.
Вместе с компанией развивается и CI/CD.
Теперь это уже не просто «собрать образ и задеплоить». Процесс становится длиннее:
- тесты;
- линтеры;
- проверки безопасности;
- сборка;
- push в registry;
- деплой на dev;
- прогон дополнительных тестов;
- деплой на pre-prod;
- еще один прогон тестов;
- ручная проверка;
- деплой на prod.
Инструменты могут быть разными: GitLab CI, Jenkins, Argo CD. Конкретный инструмент не так важен. Важна сама логика: релиз проходит через несколько этапов проверки, прежде чем попасть в production.
Так как серверов стало много, нужно нормально управлять конфигурациями. Здесь помогают Terraform и Ansible. Главная польза в том, что больше не нужно настраивать каждый сервер руками. Можно взять нужные шаблоны и раскатить серверы по ним.
На этом этапе появляется и управление секретами.
Раньше пароли и токены могли лежать как попало. Это было небезопасно и неудобно. Теперь каждый сервис должен получать свои секреты, а доступ к ним должен аудироваться. В этом контексте появляются решения класса HashiCorp и похожие инструменты для управления секретами.
Мониторинг тоже становится серьезнее. Теперь собираются не только метрики CPU и памяти, но и бизнес-метрики. Например:
- сколько заказов приходит каждую минуту;
- какие конверсии;
- какие задержки у API.
Эти показатели становятся критически важными для компании.
Появляется распределенная трассировка. Запрос пользователя может проходить через 10 сервисов. Если он тормозит, нужно понять, на каком этапе возникает задержка. Для этого используются инструменты вроде Jaeger или Tempo, которые показывают путь запроса и время на каждом этапе.
На проекте такого масштаба DevOps-команда уже может состоять из трех человек. Плюс может появиться SRE.
Разница такая: SRE отвечает за надежность, измеряет ее метрики и может тормозить релизы, если показатели плохие. DevOps больше про процессы и автоматизацию. На практике границы между этими ролями размыты, а задачи могут сильно пересекаться.
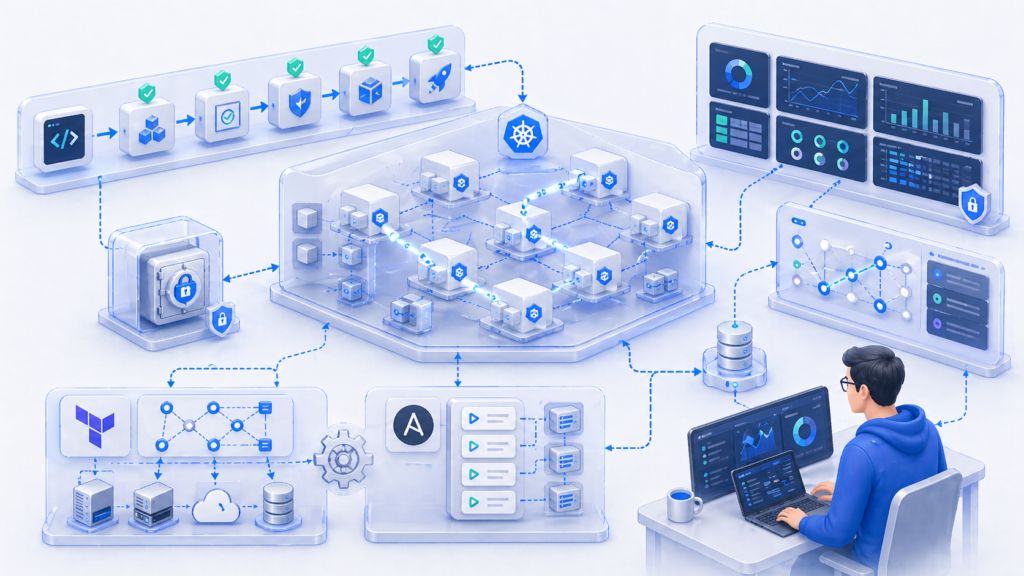
Когда команд много, появляется инфраструктурный хаос
Компания выросла: больше 100 человек, пять продуктов, восемь команд разработки.
И возникает новая проблема. Каждая команда делает инфраструктуру по-своему.
Одна команда использует GitLab CI, другая — Jenkins. Одна пишет Helm-чарты, другая использует Kustomize. Где-то свои подходы к мониторингу, где-то свои правила логирования, где-то свои пайплайны.
Это хаос.
Решение — платформенная команда.
Платформенная команда — это DevOps-инженеры, которые делают не инфраструктуру для конкретного продукта, а инструменты для других команд разработки. Их клиентами являются не пользователи приложения, а другие инженеры компании.
В продвинутом варианте такая команда создает внутреннюю платформу разработчика. Например, единый портал, где разработчик может одной кнопкой создать новый сервис. Вместе с ним появляется шаблон, настроенный CI/CD, мониторинг, логи и все базовые вещи из коробки.
Но это уже более продвинутая история.
Более приземленный первый шаг — общие стандарты. Все команды должны использовать одни и те же инструменты для CI/CD, мониторинга, логирования и других инфраструктурных задач. Не потому, что так удобнее каждой конкретной команде, а потому, что так удобнее компании в целом.
Еще одна задача инфраструктурной команды — продумать разделение окружений.
Есть классическая модель:
- dev;
- stage;
- prod;
- иногда pre-prod.
Но в зависимости от продукта могут появляться и другие окружения — для конкретных проверок, тестов или других мероприятий.
Так как продуктов много, под отдельный продукт может существовать отдельный production-кластер. Критические продукты могут получать даже несколько своих кластеров. А staging и dev-окружения могут жить в одном общем кластере, но с квотами на команду.
Организация такой логики — еще одна задача инфраструктурной команды.
На таком масштабе уже могут иметь смысл системы типа Service Mesh. Они дают mTLS между сервисами и детальные метрики. Но это не обязательный слой. Service Mesh — сложная тема, которую стоит внедрять только там, где она действительно нужна.

Появляются DBA и выделенные QA-инженеры
Когда компания дорастает до такого размера, базы данных уже нельзя администрировать по остаточному принципу.
Раньше этим могли заниматься DevOps-инженеры. Но когда базы растут до десятков или сотен терабайт, когда нужны сложные шардинги, репликации и оптимизации запросов, нужен отдельный специалист.
Так появляется DBA — администратор баз данных.
Похожая история происходит с тестированием. Раньше можно было отдавать тестирование самим разработчикам плюс иметь одного-двух тестировщиков на проект. Но теперь должна быть отдельная QA-команда, причем с автоматизацией.
Именно QA-инженеры разрабатывают тесты для пайплайнов. Без этих тестов релиз просто не должен докатываться ни до одного стенда.
Информационная безопасность становится отдельной командой
К этому моменту компания уже серьезная. А значит, есть что ломать:
- данные пользователей;
- данные бизнеса;
- интеллектуальную собственность;
- внутренние системы;
- инфраструктуру.
Появляется команда информационной безопасности.
У нее большой набор задач.
Во-первых, регулярные пентесты. Обычно для них нанимают внешних подрядчиков, которые целенаправленно пытаются взламывать компанию. Они находят уязвимости, пишут отчеты, а компания закрывает найденные проблемы.
Во-вторых, централизованный сбор и анализ событий безопасности. Нужно понимать, кто куда ходил, кто что скачивал, кто пытался зайти с неправильным паролем и что происходило в критичных системах.
В-третьих, WAF — Web Application Firewall. Это фильтр HTTP-запросов, который ловит SQL-инъекции, XSS-атаки и подозрительные паттерны.
Кроме того, IT-компания такого размера должна думать о двухфакторной аутентификации везде, где это возможно, об аудите доступов, управлении секретами и более сложных проверках безопасности в CI/CD.
С точки зрения информационной безопасности можно внедрять очень много разных вещей. Все зависит от критичности систем и от того, насколько это целесообразно.
Юридическое регулирование тоже влияет на инфраструктуру
Когда компания небольшая, ей могут вообще не интересоваться регуляторы. Но на большом масштабе появляется новая сложность — юридическое регулирование.
На первый взгляд кажется, что законы и инфраструктура — разные темы. Но на практике законы напрямую определяют, как должна быть устроена инфраструктура.
Например, если компания работает с персональными данными россиян, серверы с этими данными должны физически находиться в России.
Если компания работает с платежными картами, появляются отдельные требования: сегрегированная инфраструктура для обработки платежей, регулярные аудиты, шифрование и ограниченный доступ.
Если у компании пользователи из Евросоюза, нужно учитывать европейские правила: право на забвение, согласие на обработку данных, уведомления об утечках в течение 72 часов и разные юрисдикции для разных стран.
Поэтому IT-компании важно понимать, какая у нее аудитория и какие регуляторные требования она должна соблюдать. На этом тоже будет основываться инфраструктура.
Геораспределение: пользователи в разных странах
Финальный уровень — геораспределение.
Компания работает с пользователями в 10 странах. Среди них пользователи из России, Европы и США. Возникает вопрос: как сделать так, чтобы пользователь во Владивостоке открывал сайт так же быстро, как пользователь в Берлине?
Главное правило здесь простое: физику обмануть нельзя. Скорость конечна. Сигнал от одного сервера до двух разных локаций будет идти разное время. Куда ближе — туда быстрее.
Пользователям не нравится пинг в 120 миллисекунд. Значит, с этим нужно что-то делать.
Первое, что приходит в голову, — CDN, Content Delivery Network.
Статика — картинки, видео, JavaScript — кэшируется на серверах, разбросанных по миру. Пользователь скачивает ее из ближайшей точки, поэтому все происходит быстрее.
Но CDN решает проблему статики. А что делать с самим приложением?
Здесь нужен мультирегиональный deployment. Приложение разворачивается в нескольких регионах одновременно. Пользователь попадает в ближайший регион, потому что балансировщик на уровне DNS определяет, куда отправить его запрос.
Самая сложная часть — геораспределенные базы данных.
Простая база не умеет быть одновременно в Москве и Владивостоке с полной консистентностью. Это невозможно без серьезных компромиссов. Но есть варианты.
Можно синхронизировать данные с задержкой. Можно шардировать по регионам: европейские пользователи — в европейской базе, российские — в российской, американские — в американской.
Выбор зависит от потребностей конкретной компании.
Где размещать инфраструктуру: облако, bare metal или гибрид
Выбор архитектуры во многом зависит от того, где размещать инфраструктуру.
Есть три варианта.
- Первый — облако. Его можно быстро развернуть, оплата идет по факту использования, масштабироваться легко. Но на больших объемах облако становится дорогим. Плюс появляется зависимость от провайдера.
- Второй вариант — bare metal. Это свои серверы в собственных или арендованных дата-центрах. Так компания получает контроль над всем. Но это выгодно только на больших масштабах, потому что нужны капитальные затраты, команда, которая умеет работать с железом, и время на ввод дополнительных мощностей.
- Третий вариант — гибрид.
Критичные части живут на bare metal в собственных дата-центрах. Сервисы с эластичной нагрузкой или новые сервисы живут в облаке. Именно к такому варианту в итоге приходят многие крупные компании.

Как выглядит крупная IT-компания изнутри
В финальной точке у компании уже несколько продуктов. У каждого продукта — своя команда разработки и своя инфраструктура.
Есть собственный GitLab и собственное хранилище образов. Есть десятки Kubernetes-кластеров: для dev, prod, pre-prod. Они распределены по регионам и продуктам.
Инфраструктура гибридная: свои дата-центры, облака, географические точки в других странах.
Резервирование происходит на всех уровнях. Базы реплицированы. Сервисы работают в нескольких зонах. Бэкапы вынесены на отдельный контур.
Все это покрыто полным стеком мониторинга. Компания собирает метрики, логи, делает трассировку и настраивает alerts.
Появляется много команд:
- разработчики;
- тестировщики;
- платформенная команда;
- DevOps;
- DBA;
- дата-инженеры;
- информационная безопасность;
- архитекторы;
- юристы.
И это еще без подробного разбора процессов: agile, scrum, дежурства и других организационных вещей.
Главный вывод: сложность никто не спроектировал заранее
Самая важная мысль в том, что вся эта инфраструктура появляется не потому, что архитектор заранее нарисовал схему на 200 компонентов.
Она выросла.
Каждый компонент появился в ответ на конкретную боль.
Сначала был один человек и приложение на VPS. Потом сервер упал ночью — появился мониторинг. Потом стало страшно потерять данные — появились бэкапы. Потом стало опасно проверять изменения на production — появилось отдельное dev-окружение.
Потом пришли разработчики — появились доступы, репозитории, CI/CD и тикетница. Потом база начала мешать приложению — ее вынесли отдельно и добавили приватную сеть. Потом появились требования к uptime — добавили второй сервер приложения, балансировщик и репликацию базы.
Потом сервисов стало много — появились централизованные логи, registry, DevOps, постмортемы. Потом серверов стало больше 30 — пришли Kubernetes, Terraform, Ansible, управление секретами, серьезный мониторинг и распределенная трассировка.
Потом команд стало много — появилась платформенная команда. Потом базы выросли — появился DBA. Потом релизы стали сложнее — появилась выделенная QA-команда. Потом стало что защищать — появилась информационная безопасность. Потом появились разные страны и законы — инфраструктура начала учитывать юридические требования и географию.
Именно поэтому, когда человек впервые приходит в крупную компанию и видит десятки сервисов, сотни повторяющихся элементов и кучу окружений, ему кажется, что все слишком сложно. Но на самом деле каждый слой сложности появился из-за конкретной проблемы.
Нужно просто понимать, какой компонент для чего нужен.
Архитектор инфраструктуры — это не обязательно отдельная редкая должность. Это человек, который держит в голове всю сложную схему и понимает, почему каждый блок находится именно там, где он находится.
Можно быть senior DevOps и не быть архитектором. И можно быть архитектором без формальной должности.
Если хочется расти не вширь, а вверх, нужно учиться думать картиной целиком. Не только «как настроить X», а «зачем в системе нужен X и что будет, если его убрать».
Любая зрелая инфраструктура сложная. Потому что она прошла через много боли.


