
Экономия на S3 появляется не от механического перевода «всего старого» в Glacier, а от политики, привязанной к роли данных. Важно понимать, как часто объект читают, сколько бизнес готов ждать восстановления, можно ли удалять объект автоматически, включён ли versioning, есть ли требования RPO/RTO, аудита, compliance или Object Lock.
Дешёвый storage class может увеличить итоговый счёт из-за retrieval fees, restore operations, minimum storage duration, transition requests, большого числа мелких объектов и старых данных, которые продолжают храниться незаметно для приложения.
Безопасная lifecycle-стратегия строится по префиксам или тегам: отдельно для активных файлов, временных экспортов, логов, архива, редко используемых данных и noncurrent versions. Сначала нужна инвентаризация, анализ доступа и владельцы данных, затем пилотные правила transition, expiration, очистки старых версий, delete markers и незавершённых multipart-загрузок.
Главный вывод: lifecycle должен делать хранение предсказуемым, а не просто переносить данные в самый дешёвый класс.
Почему экономия на object storage начинается не с Glacier

Счёт за S3 Standard обычно растёт незаметно: пользовательские файлы, выгрузки, медиаданные, логи, старые версии объектов. В какой-то момент в биллинге появляется крупная строка за хранение, и первое решение кажется очевидным: всё старше 90 дней отправить в Glacier, временное удалить, логи заархивировать.
На схеме это выглядит как экономия. В рабочей инфраструктуре — как зона риска.
Дешёвый класс хранения не всегда означает дешёвые данные. Объекты могут внезапно понадобиться аналитике, аудиторам, поддержке или процессу восстановления после сбоя. Тогда появляются плата за извлечение, задержки восстановления, доплаты из-за минимального срока хранения, старые версии и delete markers — маркеры удаления, из-за которых объект может выглядеть удалённым, но место фактически не освобождается.
Хорошая lifecycle-логика начинается не с возраста объекта, а с его роли:
- Как часто объект читают;
- Сколько бизнес готов ждать восстановления;
- Можно ли удалять объект автоматически;
- Включён ли versioning и нужны ли старые версии для отката;
- Есть ли требования аудита, compliance, RPO/RTO или Object Lock.
RPO — допустимая точка восстановления: сколько данных бизнес может потерять при сбое. RTO — допустимое время восстановления. Object Lock — механизм защиты объектов от удаления или изменения на заданный срок, часто используемый для compliance.
S3 Lifecycle полезен, когда превращается в управляемую политику: сначала понять экономику хранения, затем выбрать классы, разделить объекты по сценариям и только потом включать transition, expiration и очистку версий. Иначе оптимизация легко становится новым источником расходов — или слишком быстрым способом удалить данные, которые ещё должны были жить.
Из чего на самом деле складывается экономия в S3
В S3 важно считать не только цену гигабайта в месяц, а стоимость владения объектом на всём его жизненном пути: объект записали, хранили, прочитали, перевели в другой класс, восстановили, удалили или сохранили как старую версию.
Упрощённо: экономия = снижение стоимости хранения − плата за извлечение − стоимость запросов и переводов − начисления за минимальный срок хранения − стоимость восстановления
Эта формула не про точный расчёт до цента, а про дисциплину мышления. Класс хранения с низкой ценой за объём выгоден только тогда, когда поведение данных совпадает с его экономикой: объект редко читают, он живёт достаточно долго, а восстановление не ломает SLA и рабочие процессы.
В счёте нужно учитывать:
- Хранение объектов в выбранном классе;
- API-запросы, чтение и листинг;
- Запросы на перевод между классами;
- Плату за извлечение из «холодных» классов;
- Операции восстановления из архива;
- Минимальный срок хранения и начисления при раннем удалении;
- Старые версии объектов при включённом versioning;
- Незавершённые multipart-загрузки.
Здесь часто ломается модель «переложили туда, где дешевле — сэкономили». Например, аналитический pipeline раз в неделю перечитывает архивные выгрузки. После перевода в IA или Glacier хранение дешевеет, но появляются расходы на извлечение, восстановление и задержки доступа. IA означает Infrequent Access: класс дешевле по хранению, но рассчитан на редкие чтения.
Минимальный срок хранения добавляет ещё один эффект. Если объект перевели в более дешёвый класс, а затем быстро удалили, провайдер всё равно может начислить стоимость как за минимальный период. Поэтому временные файлы и промежуточные выгрузки обычно не стоит автоматически отправлять в холодное хранение: на бумаге они дешевеют, в счёте — нет.
Отдельная зона — версии объектов. Команда может смотреть на текущий объект и считать, что объём под контролем, но старые версии продолжают храниться и оплачиваться. Они полезны для отката, но без очистки превращаются в тихий множитель стоимости.
Поэтому storage class нужно выбирать не по самой низкой цене за GB, а по поведению данных: как часто объект читают, сколько он живёт, как быстро его нужно восстановить и есть ли у него старые версии.
Storage classes: выбирать по доступу, а не по минимальной цене хранения
Glacier Deep Archive выглядит как очевидный победитель: цена хранения ниже, значит старые данные надо отправлять туда. Но в B2B-системе объект может понадобиться сегодня: поддержке для разбора заказа, финансовой команде для сверки, инженерам для расследования инцидента.
Поэтому класс хранения влияет не только на счёт AWS, но и на SLA, ручную работу и скорость принятия решений.
S3 Standard
S3 Standard подходит для активных данных: пользовательского контента, рабочих файлов, медиаданных, документов и объектов, которые регулярно читает приложение.
Главный риск — переплата за данные, которые давно не используются. Если объект месяцами лежит без обращений, но остаётся в Standard, команда платит за быстрый доступ, который фактически не нужен.
Когда становится понятно, что часть данных уже не активна, но всё ещё должна быстро открываться по запросу, появляется следующий вариант — IA-классы.
Standard-IA и One Zone-IA
Standard-IA подходит для редко используемых данных, которые всё ещё должны быть доступны быстро: старые отчёты, закрытые заказы, завершённые кейсы, документы поддержки.
Но экономия работает только при редких чтениях. Если аналитика, поддержка или batch-задачи регулярно перечитывают такие объекты, retrieval fees могут съесть выгоду.
One Zone-IA стоит использовать осторожнее: он хранит данные в одной зоне доступности. Это разумно для воспроизводимых данных или некритичных копий, но опасно для единственной копии документов, пользовательских файлов, бэкапов или материалов аудита.
Если данные уже стали архивом, но ждать восстановления часами нельзя, IA-классов может быть мало. Тогда логичнее смотреть в сторону Glacier Instant Retrieval.
Glacier Instant Retrieval
Glacier Instant Retrieval подходит для архива, который нужен редко, но может потребоваться почти сразу. Например, для документов, старых заказов, материалов расследований или архивных резервных копий, где ожидание восстановления на часы недопустимо.
Риск в том, что массовые чтения такого архива могут стать дорогими. Если данные всё ещё регулярно поднимают отчёты, аналитика или поддержка, класс может оказаться не таким дешёвым, как кажется по цене хранения.
Когда архив почти не читается и бизнес допускает ожидание восстановления, можно уходить в более холодные классы.
Glacier Flexible Retrieval и Deep Archive
Glacier Flexible Retrieval подходит для долгосрочного архива, где допустимо ждать восстановления. Deep Archive — для очень долгого хранения: аудита, compliance, исторических данных, которые почти не читаются.
Здесь главный вопрос не в цене за GB, а во времени восстановления. Если данные могут срочно понадобиться юристам, аудиторам, поддержке или команде расследования инцидента, слишком холодный класс может превратить экономию в простой и ручную эскалацию.
Но не всегда команда заранее понимает, как объект будет использоваться через месяц или полгода. Для таких непредсказуемых сценариев подходит Intelligent-Tiering.
Intelligent-Tiering
Intelligent-Tiering полезен, когда команда не может предсказать поведение объектов. Сегодня выгрузку читают каждый день, через месяц забыли, через полгода снова подняли для анализа.
Но это не «бесплатная магия». Intelligent-Tiering не отменяет финансовую модель S3: за автоматизацию, мониторинг и отдельные уровни хранения тоже нужно платить. Его стоит рассматривать как способ снизить риск ручной ошибки, а не как универсальную замену lifecycle-политике.
Класс хранения отвечает на вопрос, куда помещать данные. Но он не решает, когда переводить объект и когда его удалять. Для этого нужны правила S3 Lifecycle.
Что умеет S3 Lifecycle: transition, expiration и работа с версиями
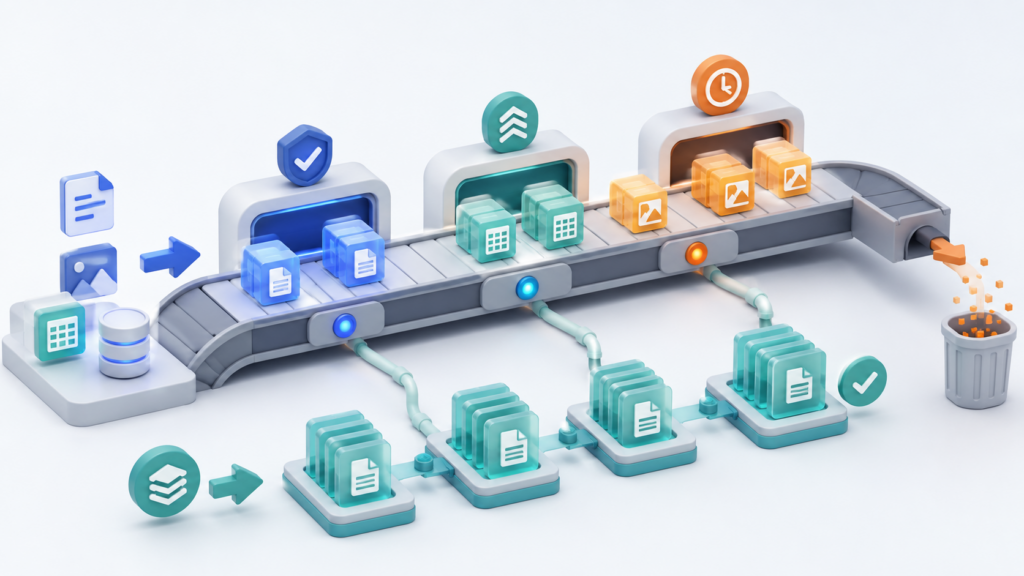
S3 Lifecycle — это не скидка и не кнопка «сделать дешевле». Это расписание эксплуатации данных: что остаётся в рабочей зоне, что переводится в холодный класс, что удаляется после срока жизни, а что нужно вычистить как технический хвост.
Правило можно назначить на бакет целиком, ограничить префиксом или отобрать объекты по тегу. Например: объекты с префиксом /exports/temp/ удалять через 7 дней, а старые версии переводить в IA через 30 дней и удалять через 180 дней.
Основные действия S3 Lifecycle:
- Transition — перевод текущего объекта в другой storage class.
- Expiration — удаление текущего объекта по сроку. В бакете без versioning это физическое удаление, а при включённом versioning может появиться delete marker, при этом старые версии останутся.
- NoncurrentVersionTransition — перевод старых, неактуальных версий в другой класс хранения.
- NoncurrentVersionExpiration — удаление старых версий после заданного периода.
- Удаление expired object delete markers — очистка устаревших маркеров удаления, когда за ними уже нет нужных данных.
- Abort incomplete multipart uploads — прерывание незавершённых составных загрузок, части которых занимают место.
Текущий объект и старая версия — разные сущности. Текущий объект видит приложение. Неактуальная версия нужна для отката, расследования или восстановления. У них разные роли, а значит, разные сроки жизни и последствия удаления.
Lifecycle безопасен только тогда, когда правило точно отвечает на три вопроса: какие объекты оно затрагивает, что делает и когда действие должно остановиться.
Матрица объектов и lifecycle-решений
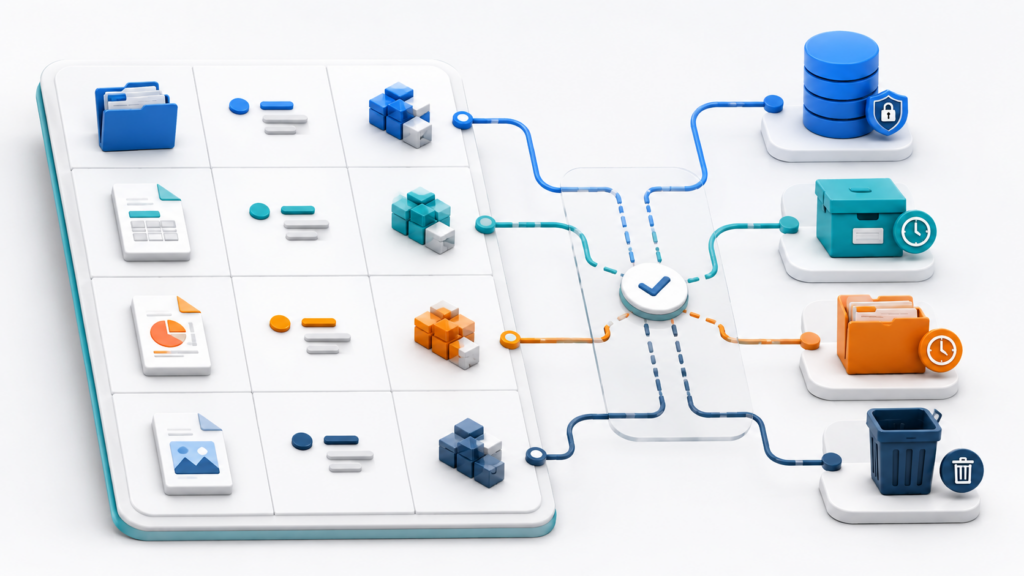
В одном бакете могут соседствовать пользовательские файлы в /media/, временные выгрузки в /exports/temp/, audit-логи в /logs/audit/ и старые версии документов. Для S3 это просто объекты, но для бизнеса у них разная ценность, срок жизни и цена ошибки.
Поэтому lifecycle-политика не должна быть одной для всего бакета. Правило «всё старше 90 дней отправить в архив» одинаково относится к пользовательскому документу, временному экспорту и audit-логу, хотя последствия ошибки у них разные.
Перед настройкой lifecycle для каждой группы объектов нужно отдельно определить:
- Как часто данные читаются;
- Какой storage class подходит под сценарий доступа;
- Когда объект можно переводить в более дешёвый класс;
- Когда его можно удалять;
- Что делать со старыми версиями;
- Какой риск будет главным: задержка восстановления, потеря отката, лишние retrieval fees или преждевременное удаление.
Например, активные пользовательские файлы обычно не стоит переводить в холодный класс только по возрасту. Временные экспорты чаще выгоднее быстро удалять, а не отправлять в IA или Glacier. Audit-логи требуют осторожности из-за расследований, compliance и внутренних политик хранения. Старые версии объектов нужно управлять отдельно, потому что приложение их не видит, но счёт за них продолжает расти.
Такая матрица решений нужна не как готовое правило для AWS, а как способ разделить данные по ролям. После этого можно переходить к практическим lifecycle-политикам: отдельно для активных файлов, редко используемых данных, архива, временных объектов, старых версий и логов.
Lifecycle-политики по сценариям: как применять матрицу на практике
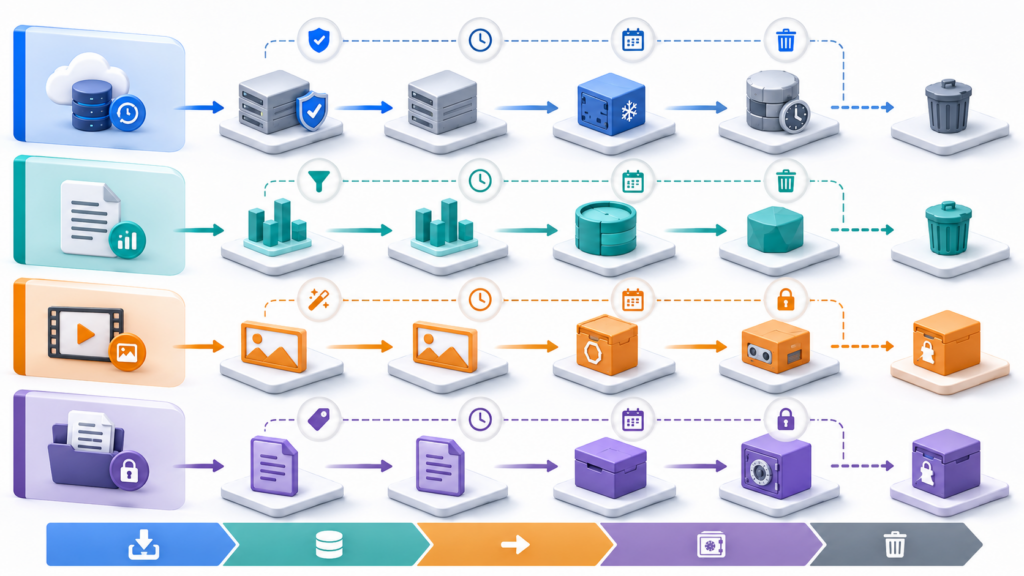
Часто используемые объекты
Для /media/active/, пользовательских документов и файлов приложения не стоит включать перевод в холодный класс только по возрасту. Старый объект не всегда редко читается: его могут открывать пользователи, поддержка, интеграции или фоновые процессы.
Transition обычно не нужен. Если доступ непредсказуемый, лучше рассмотреть Intelligent-Tiering или сначала собрать статистику обращений. Expiration стоит привязывать не к возрасту, а к бизнес-событию: закрытию аккаунта, истечению договора, явному сроку хранения или запросу на удаление.
Если включён versioning, старые версии можно чистить отдельно, сохраняя окно отката 30–90 дней. Слишком короткий срок опасен: ошибку могут обнаружить не сразу.
Когда объект перестаёт быть активным и переходит в завершённый бизнес-контекст, lifecycle можно делать агрессивнее.
Редко используемые данные
Закрытые заказы, старые отчёты и завершённые кейсы лучше переводить по понятной метке: дате закрытия заказа, завершению периода или тегу, который ставит приложение.
Для таких данных подойдёт Standard-IA, если нужен быстрый доступ. One Zone-IA стоит использовать только для копий, которые можно восстановить из другого источника. Автоматическое удаление можно рассматривать через 1–3 года после закрытия кейса, если нет требований регулятора, аудита, договора или поддержки клиентов.
При включённом versioning нужно отдельно задать окно отката: например, переводить noncurrent versions в Standard-IA через 30 дней и удалять через 180–365 дней.
Если данные уже вышли из операционного контура и почти не участвуют в рабочих процессах, это уже не просто «редкий доступ», а архив.
Архивные данные
Архив переводят после выхода из операционного контура: закрыт финансовый период, завершён проект, данные больше не нужны в ежедневной работе.
Выбор между Glacier Instant Retrieval, Glacier Flexible Retrieval и Deep Archive зависит от допустимого времени восстановления. Если legal-команда, аудит или безопасность могут запросить данные срочно, Deep Archive может быть слишком медленным.
Expiration для архива включают только после проверки срока хранения, compliance, legal hold и Object Lock. Для одних данных это 3 года, для других — 7 или 10 лет. Если архивные объекты версионируются, старые версии считаются частью архива и должны храниться по тем же или более строгим правилам.
Совсем другая логика нужна для объектов, которые не должны жить долго изначально.
Временные файлы
Для /exports/temp/ обычно выгоднее оставить S3 Standard и быстро удалять. Перевод в холодные классы часто делает временные данные дороже из-за minimum storage duration и стоимости операций.
Основной механизм экономии здесь — expiration. Экспорты и промежуточные файлы можно удалять через 1, 3 или 7 дней, но только после проверки, что пользователь или интеграция успевают забрать файл. Отдельно стоит включить abort incomplete multipart uploads, например через 1 день.
Если versioning включён на всём бакете, временные файлы могут создавать старые версии при перезаписи. Для такого префикса нужно отдельное правило удаления noncurrent versions через 1–7 дней.
Версионированные бакеты вообще требуют отдельной логики: текущий объект и его история управляются разными правилами.
Версии объектов
В бакете с versioning текущие объекты и старые версии — разные сущности. Текущий объект видит приложение, а noncurrent versions остаются в истории и продолжают занимать место.
Текущий объект может оставаться в своём классе или управляться обычным правилом сценария. Старые версии через NoncurrentVersionTransition можно переводить через 30 дней в Standard-IA, а позже — в Glacier. Для удаления нужен отдельный NoncurrentVersionExpiration, например через 180 или 365 дней.
Срок хранения неактуальных версий нужно согласовать с RPO/RTO, поддержкой и расследованиями. Если удалить их слишком рано, команда потеряет возможность восстановиться после неудачного релиза, повреждения данных или ошибочного удаления.
Отдельный случай — логи: у них свои сроки, свои владельцы и свои последствия удаления.
Логи
Логи лучше разделять: журналы приложения, access-логи, audit- и security-логи не должны жить по одной политике.
App-логи можно переводить в IA через 30 дней, затем в Glacier через 90–180 дней. Audit- и security-логи обычно требуют более осторожной политики: срок активного хранения и удаления должен быть согласован с безопасностью, юридической командой и аудитом.
App-логи можно удалять через 1–2 года, если это соответствует внутренней политике. Audit- и security-логи удаляют только после утверждённого срока хранения. Если versioning включён, старые версии логов тоже нужно чистить отдельным правилом.
Практически безопаснее включать lifecycle не сразу на весь бакет, а по одному префиксу или тегу: проверить владельца данных, срок хранения, восстановление, versioning и расчёт стоимости с учётом чтений. Особенно аккуратно нужно работать с версионированными бакетами: там удаление текущего объекта ещё не означает, что расходы действительно ушли.
Версионирование и delete markers: почему «удалили» не значит «освободили место»

В B2B-хранилищах версии — один из самых частых источников скрытых расходов. Lifecycle вроде бы настроен, текущие объекты удаляются или переезжают в дешёвые классы, а счёт снижается слабее ожиданий.
Обычно это происходит так: правило удаляет текущую версию, S3 создаёт delete marker, приложение больше не видит объект, но старые версии продолжают храниться и оплачиваться. Сам delete marker обычно не главный потребитель объёма, но он создаёт управленческую проблему: команда видит «удалено», а история объекта остаётся в бакете.
Перед включением правил нужно посмотреть объём noncurrent versions, количество delete markers и наличие отдельной политики для старых версий. Это можно делать через инвентаризацию S3, Storage Lens или выборочную проверку префиксов, где часто перезаписываются документы, выгрузки и пользовательские файлы.
Безопасный порядок такой: сначала определить окно отката вместе с владельцем данных и требованиями RPO/RTO, затем настроить перевод старых версий в более дешёвый класс, после этого — удаление по сроку, и только потом очищать устаревшие маркеры удаления.
Если начать с удаления, можно потерять восстановление. Если ограничиться маркерами, экономии почти не будет. Поэтому version cleanup должен быть отдельной частью lifecycle-стратегии, а не побочным эффектом обычного expiration.
Скрытые факторы стоимости перед включением lifecycle
Lifecycle-правило меняет сразу несколько строк счёта. Перед массовым переводом объектов полезно пройти короткую проверку: где может появиться дополнительная стоимость и что нужно проверить до включения правила.
Доступ и восстановление
Первый риск — чтение данных после перевода в более дешёвый класс. Для Standard-IA, One Zone-IA, Glacier Instant Retrieval и архивных классов частые обращения могут съесть экономию за счёт retrieval fees.
Для Glacier Flexible Retrieval и Deep Archive добавляется ещё один фактор — restore operations. Данные нельзя читать сразу: их нужно восстановить, а это влияет на стоимость, RTO, клиентскую поддержку, аудит и расследования.
Перед переводом стоит проверить отчёты, batch-задачи, обращения поддержки, аналитику и сценарии аварийного восстановления. Если объект всё ещё часто читают или он нужен срочно, дешёвый класс может быть правильным только на бумаге.
Минимальный срок хранения и переходы
IA- и Glacier-классы имеют minimum storage duration. Если объект быстро удалить после перевода, ожидаемой экономии может не быть: провайдер всё равно начислит стоимость как за минимальный период.
Отдельно нужно учитывать transition requests. Массовые переводы между классами — это тоже операции, особенно заметные при большом числе мелких объектов.
Поэтому перед настройкой стоит посмотреть срок жизни объектов, средний размер файла и количество объектов по префиксам. Для временных выгрузок главный рычаг часто не transition, а короткий, но безопасный expiration.
Versioning, delete markers и multipart uploads
В versioned bucket старые версии продолжают храниться даже после удаления текущего объекта. Поэтому нужно заранее проверить объём noncurrent versions и наличие правила NoncurrentVersionExpiration.
Delete markers создают другую проблему: объект выглядит удалённым, но его история может оставаться в бакете. Если не чистить устаревшие маркеры и старые версии, счёт снижается слабее ожиданий.
Ещё один скрытый хвост — incomplete multipart uploads. Незавершённые загрузки могут занимать место без видимого объекта, поэтому для них стоит включить AbortIncompleteMultipartUpload.
Агрессивное удаление
Короткий expiration быстро снижает объём, но может удалить данные раньше, чем их забрал пользователь, интеграция, аудит или служба поддержки. Особенно опасно применять короткие сроки к логам, документам, архивам и объектам с legal hold, Object Lock или compliance-требованиями.
Перед включением удаления нужно проверить SLA, срок хранения, владельца данных и сценарии восстановления. Lifecycle должен сокращать лишние расходы, а не создавать риск преждевременной потери данных.
Эта проверка не заменяет расчёт стоимости, но помогает не смотреть на lifecycle только как на снижение цены за хранение. Если объект нужно часто читать, быстро восстанавливать или долго держать из-за compliance, дешёвый класс может оказаться дороже ожидаемого.
Как внедрять lifecycle без сюрпризов

Безопасное внедрение начинается с инвентаризации. Нужно понять, какие префиксы и теги есть в бакете, какие объекты читаются, где включён versioning, сколько занимают старые версии и есть ли незавершённые multipart-загрузки.
Для этого используют S3 Inventory, Storage Class Analysis, Storage Lens, access logs или статистику приложения.
После этого бакет лучше разделить управленчески: /media/active/, /exports/temp/, /logs/app/, /logs/audit/, /archive/, теги проекта или клиента. У каждой группы должен быть владелец данных. Без владельца срок удаления превращается в догадку, а догадка в lifecycle-политике — плохой контроль.
Рабочий порядок:
- Собрать фактическое использование и объём по префиксам;
- Разделить объекты по сценариям и владельцам;
- Согласовать сроки хранения, восстановления и удаления;
- Настроить transition, expiration и version cleanup для пилота;
- Проверить восстановление и влияние на биллинг;
- Масштабировать правило только на похожие группы объектов.
Такой процесс медленнее, чем правило «всё старше N дней», зато снижает риск двух типичных ошибок: заплатить за холодные данные дороже ожидаемого и удалить то, что ещё нужно бизнесу.
Заключение
S3 Lifecycle снижает расходы не тогда, когда всё старое механически уезжает в архив, а когда у каждого типа объектов есть своя политика: где хранить, когда переводить, когда удалять и сколько держать старые версии. Для бизнеса это не только цена за гигабайт, а управляемый риск: сможете ли вы быстро достать данные для клиента, аудита, расследования или восстановления после ошибки.
Безопасный подход выглядит так: разделить объекты по префиксам или тегам, проверить паттерны доступа, требования к хранению и восстановлению, выбрать storage class и только потом включать transition, expiration и очистку неактуальных версий.
Особенно внимательно стоит относиться к versioning, delete markers, minimum storage duration и retrieval fees: именно они чаще всего превращают ожидаемую экономию в неожиданный счёт.
Итоговая цель lifecycle-политики — не «убрать всё дешевле», а сделать хранение предсказуемым.
FAQ
Можно ли просто перевести всё старше 90 дней в Glacier?
Технически можно, но это плохая универсальная политика. Возраст объекта не всегда означает, что он редко нужен. Старые документы, логи или файлы заказов могут быть нужны поддержке, аналитике, аудиторам или процессу восстановления на регулярной основе.
Когда стоит использовать Intelligent-Tiering?
Когда доступ к объектам непредсказуем: сегодня данные читаются часто, через месяц почти не используются, а потом снова нужны аналитике. Intelligent-Tiering снижает риск ручной ошибки, но не отменяет проверку стоимости, мониторинга и сценариев доступа.
Почему после удаления объектов счёт за S3 может не уменьшиться?
Частая причина — versioning. В versioned bucket удаление текущего объекта может создать delete marker, а старые версии продолжат храниться и оплачиваться.
Нужны отдельные правила для noncurrent versions и, когда это безопасно, очистка устаревших delete markers.
Нужно ли переводить временные файлы в дешёвые классы хранения?
Обычно нет. Если файл живёт несколько дней, перевод в IA или Glacier может не дать экономии из-за minimum storage duration и стоимости transition requests.
Для временных экспортов чаще подходит короткий expiration и правило AbortIncompleteMultipartUpload для незавершённых multipart-загрузок.
Как понять, что lifecycle-правило безопасно включать?
У правила должен быть владелец данных, согласованный срок хранения, понятный сценарий восстановления и отдельная логика для старых версий.
Начинать лучше с одного префикса или тега: проверить фактический доступ, влияние на биллинг, работу восстановления и только потом масштабировать политику на похожие группы объектов.
Список источников
1. Amazon S3: Understanding and managing storage classes

