
В Kubernetes дорогим может быть даже “недогруженный” кластер. kubectl top и Grafana показывают фактическое потребление CPU и памяти, но планировщик размещает Pod’ы не по среднему usage, а по заявленным requests. Если команды ставят ресурсы “с запасом”, Kubernetes считает эту ёмкость занятой, даже если приложение большую часть времени её не использует.
Финансовая цепочка выглядит так:
container requests
→ pod requests
→ scheduler
→ node allocatable
→ количество нод
→ cloud bill
Поэтому снижение limits само по себе обычно не уменьшает счёт. limits ограничивают потребление контейнера после запуска, но не заставляют кластер держать меньше нод. Для экономии важнее правильно настроить requests, плотность размещения Pod’ов, node pools и autoscaling.
Основные рычаги работают вместе:
- Rightsizing — приближает завышенные requests к реальному профилю нагрузки, но с запасом под пики и соблюдение SLА;
- ResourceQuota — ограничивает суммарные заявки namespace и помогает связать технические лимиты с бюджетами команд;
- LimitRange — задаёт значения по умолчанию и границы для Pod’ов без нормальных requests и limits;
- Autoscaling и node pools — превращают освобождённую ёмкость в меньшее число оплачиваемых нод;
- Spot-ноды — снижают цену части capacity, но подходят только для нагрузок, которые переживают прерывания.
Правильный порядок такой: сначала понять, сколько CPU и памяти Kubernetes уже считает зарезервированными, затем найти завышенные requests, проверить пики, throttling, OOMKilled, eviction и SLA. После этого можно вводить quotas, пересматривать node pools, настраивать autoscaling и переносить подходящие нагрузки на spot.
Главный критерий успешной оптимизации — не красивый график низкой загрузки, а уменьшение оплачиваемой, но неиспользуемой ёмкости без деградации сервиса.
Как Kubernetes requests превращаются в стоимость кластера

После TL;DR главный вопрос такой: почему кластер может быть дорогим, хотя CPU и память на графиках выглядят свободными. Причина в том, что Kubernetes принимает решения о размещении Pod’ов не по среднему фактическому потреблению, а по заявленным requests.
Scheduler смотрит на заявку, а не на средний usage
Для scheduler важно, сколько CPU и памяти Pod попросил заранее. Если контейнеру указали 500m CPU и 1Gi памяти, Kubernetes считает, что под этот контейнер нужно зарезервировать именно такой объём. Даже если большую часть времени приложение использует меньше.
Request всего Pod’а складывается из requests всех контейнеров внутри него. Поэтому учитывать нужно не только основное приложение, но и sidecar-контейнеры: service mesh proxy, агенты логирования, security agent, контейнеры для метрик. Лёгкий сервис может стать заметно тяжелее для планировщика из-за инфраструктурной обвязки.
Дальше scheduler ищет ноду, где хватает доступной ёмкости. Но доступная ёмкость — это не полный размер виртуальной машины. У ноды есть node allocatable: часть CPU и памяти уже вычтена под kubelet, системные резервы, container runtime и DaemonSet’ы. Поэтому нода на 8 vCPU не означает, что все 8 vCPU можно отдать пользовательским Pod’ам.
Где появляется разрыв между графиками и счётом
Цепочка стоимости выглядит так:
container requests
→ pod requests
→ scheduler
→ node allocatable
→ количество нод
→ cloud bill
Именно здесь появляется разрыв между “кластер почти не загружен” и “инфраструктура дорогая”. Процесс может реально потреблять мало CPU и памяти, но для scheduler ресурсы уже заняты заявками. Он не может разместить новый Pod на CPU или RAM, которые формально зарезервированы другим Pod’ом.
Например, Pod запрашивает 2 vCPU и 8 GiB RAM, но обычно потребляет 400m CPU и 2 GiB RAM. На графике это выглядит спокойно. Но для размещения такой Pod занимает именно 2 vCPU и 8 GiB. Если таких Pod’ов много, кластер заканчивается по requests раньше, чем по реальному потреблению.
Часто ограничителем становится память. CPU может выглядеть свободным, но новый Pod всё равно не разместится, если по requested memory подходящих нод уже нет.
Почему autoscaler добавляет ноды
Если Pod’ы не помещаются на текущие ноды, Cluster Autoscaler или Karpenter могут добавить новые. Для облака это уже прямой расход: оплачиваются ноды или VM, а не среднее потребление процессов внутри Pod’ов.
Поэтому стоимость растёт не только из-за реально использованных millicores и гигабайт памяти. Она растёт из-за ёмкости, которую кластер обязан держать под обещанные requests.
В расчётах стоимости это удобно понимать через простую логику: если request выше фактического usage, неиспользованная часть превращается в idle cost — оплачиваемую, но пустующую ёмкость.
Отсюда и правильная точка входа для оптимизации: сначала нужно найти Pod’ы, контейнеры и sidecar’ы с завышенными requests. И только потом переходить к limits, quotas, node pools и spot-нодам. Иначе команда будет бороться с видимой загрузкой, хотя оплачиваемая проблема находится в другом месте — в том, что Kubernetes уже считает занятым.
Requests и limits: что влияет на размещение, а что ограничивает потребление

После цепочки requests → scheduler → ноды → счёт возникает практический вопрос: какие параметры в манифесте реально влияют на стоимость, а какие нужны для контроля поведения контейнера после запуска.
На первый взгляд кажется, что если снизить limits, то счёт тоже должен уменьшиться. Но облако выставляет счёт за ноды, а Kubernetes размещает Pod’ы по requests. Поэтому экономия появляется не от самого факта снижения limits, а от изменения потребности в нодах: их количества, размера или типа.
requests — это заявка на ресурсы, которые Kubernetes считает необходимыми для запуска Pod’а. Если контейнер просит 500m CPU, это половина vCPU; 1 CPU — один CPU в терминах Kubernetes. Память обычно задают в Mi и Gi: например, 512Mi или 2Gi. Именно эти значения участвуют в размещении.
limits решают другую задачу. Они задают верхнюю границу потребления контейнера после запуска. Это не инструмент прямой экономии, а защитный механизм: он ограничивает процесс, если тот начинает потреблять слишком много ресурсов и мешать соседним нагрузкам на ноде.
Разницу удобнее зафиксировать так:
| Параметр | Что означает | Влияет на размещение | Основной риск |
| CPU request | Заявленная потребность в CPU | Да | Завышение даёт пустующую ёмкость, занижение — нестабильную производительность |
| Memory request | Заявленная потребность в памяти | Да | Завышение ведёт к дорогому перерасходу, занижение — к eviction при memory pressure |
| CPU limit | Верхняя граница CPU | Нет напрямую | throttling, рост latency, падение пропускной способности |
| Memory limit | Верхняя граница памяти | Нет напрямую | OOMKilled, рестарты, нестабильность |
Requests определяют, сколько ёмкости Kubernetes считает занятой, а limits задают защитные границы потребления. Для экономии нужно корректировать резервирование и добиваться изменения потребности в нодах. Для стабильности — не ставить limits агрессивно без анализа пиков, SLA и событий throttling или OOMKilled.
Особенно аккуратно стоит относиться к CPU limits у API-сервисов и фоновых обработчиков. Команда может снизить CPU limit, ожидая уменьшения расходов, но ноды останутся теми же. Зато приложение начнёт чаще упираться в ограничение: вырастет throttling, увеличится latency, снизится пропускная способность, а финансовый эффект может оказаться нулевым.
С памятью риск ещё жёстче. Превышение Memory limit обычно заканчивается OOMKilled и рестартом контейнера. Поэтому память часто становится не только ограничителем размещения, но и источником нестабильности при пиках. CPU на нодах может выглядеть свободным, но Pod не разместится, если не хватает requested memory. А слишком низкий memory limit может превратить нормальный всплеск нагрузки в перезапуск.
Корректное разделение этих параметров даёт две разные ручки управления. Через requests команда управляет стоимостью и плотностью размещения. Через limits — изоляцией и рисками во время выполнения.
Практический пример: rightsizing namespace до и после

После разделения requests и limits полезно посмотреть, как rightsizing влияет на стоимость на практике. Важно: оптимизация не обязательно снижает фактическое потребление приложения. Она уменьшает ёмкость, которую Kubernetes считает занятой для размещения.
Возьмём условный namespace. По графикам он выглядит спокойным: около 12 vCPU и 60 GiB RAM фактического потребления. Но суммарно Pod’ы в namespace запрашивают 40 vCPU и 160 GiB RAM. Для scheduler это тяжёлая нагрузка, даже если процессы реально используют меньше.
После пересмотра заявок картина может выглядеть так:
| Показатель | До rightsizing | После rightsizing | Что меняется |
| CPU request namespace | 40 vCPU | 18–22 vCPU | Меньше CPU считается занятым |
| Memory request namespace | 160 GiB | 80–90 GiB | Освобождается память для размещения Pod’ов |
| Фактический CPU usage | около 12 vCPU | без существенного изменения | Приложение не стало потреблять меньше CPU |
| Фактический memory usage | около 60 GiB | без существенного изменения | Рабочий профиль остался тем же |
| Резерв под пики | чрезмерный | ближе к реальному профилю | Запас остаётся, но не блокирует лишнюю ёмкость |
| Возможный эффект на ноды | больше нод удерживаются из-за requests | часть нод можно освободить | Экономия появляется на уровне оплачиваемых VM |
Вывод из таблицы простой: rightsizing не “ускоряет” приложение и не заставляет его потреблять меньше ресурсов. Он убирает лишнее резервирование, из-за которого кластер держит больше оплачиваемой ёмкости, чем нужно.
Теперь добавим условный расчёт. Пусть namespace размещается в отдельном пуле нод или занимает достаточно большую долю общего пула. Одна нода имеет 8 vCPU и 32 GiB RAM, но после системных резервов, DaemonSet’ов и служебных процессов для пользовательских Pod’ов доступно примерно 7,2 vCPU и 28 GiB RAM.
До rightsizing namespace запрашивает 40 vCPU и 160 GiB RAM. Это требует примерно 6 нод: и по CPU, и по памяти. После rightsizing берём верхнюю границу новых заявок — 22 vCPU и 90 GiB RAM. Такой объём уже помещается примерно в 4 ноды.
Получается модельный эффект: пул может уменьшиться с 6 до 4 нод. Условная экономия — 2 ноды, или около 33% стоимости этого пула.
Это не гарантированная сумма экономии. В реальной среде результат зависит от фрагментации Pod’ов, mix’а нагрузок, требований по зонам доступности, anti-affinity, минимального размера node pool и настроек autoscaler. Но модель показывает главное: экономия появляется не в момент снижения числа в манифесте, а когда после этого можно удалить оплачиваемые ноды или хотя бы отложить следующее масштабирование.
Важно не брать среднее потребление как новый request. В примере 12 vCPU и 60 GiB RAM — это нижняя граница для анализа, а не безопасная новая заявка. Нужен запас под пики, деплой, фоновые задачи и суточные колебания. Поэтому CPU requests снижаются не до 12 vCPU, а до диапазона 18–22 vCPU; память — не до 60 GiB, а до 80–90 GiB.
CPU и память стоит проверять отдельно. Можно освободить много CPU, но не удалить ноду, если память всё ещё фрагментирована. Или наоборот: снизить memory requests и резко улучшить размещение, хотя CPU на графиках и раньше выглядел свободным.
Если после rightsizing ноды не удаляются, это не всегда провал. Возможно, кластер дольше не достигнет порога масштабирования. Следующий шаг — смотреть распределение Pod’ов, размеры нод, фрагментацию ресурсов и настройки autoscaler.
Quotas и overprovisioned namespaces: как ограничить аппетит команд
Namespace’ов несколько, и каждый держит запас “на всякий случай”. В итоге команды конкурируют не за фактическое потребление, а за зарезервированную ёмкость, а кластер растёт даже без заметного роста нагрузки.
ResourceQuota помогает поставить верхнюю границу: сколько суммарных requests и limits CPU/RAM может быть в namespace. Но quota — это не автоматическая оптимизация. Она ограничивает аппетит, но не проверяет, насколько обоснованы конкретные заявки.
Например, команде выделили namespace с quota на 80 vCPU. Фактически сервисы используют около 20 vCPU, но суммарные requests уже выставлены на 60 vCPU. Формально команда остаётся в лимите. Но для scheduler эта ёмкость уже занята, другие Pod’ы размещаются хуже, autoscaler добавляет ноды, а расходы растут из-за завышенного резервирования внутри “разрешённого” бюджета.
Чтобы quota работала как управленческий инструмент, нужны не только числа, но и правила:
- Лимиты по requests и limits для namespace;
- Регулярный пересмотр quota по данным потребления;
- Видимость стоимости для команды: сколько CPU/RAM она резервирует;
- Понятная процедура запроса увеличения, если нагрузка действительно выросла;
- Связь quota с rightsizing, а не только с административным запретом.
Без процесса quota быстро становится либо формальностью, либо источником заблокированных релизов. Слишком мягкий потолок закрепляет overprovisioning как норму. Слишком жёсткий может остановить развёртывание в неподходящий момент.
Дополнительно можно использовать LimitRange: он задаёт значения по умолчанию и допустимые границы для Pod’ов без нормальных requests и limits. Но LimitRange тоже не заменяет анализа профиля нагрузки. Он помогает не оставлять ресурсы пустыми или бесконтрольными, но не решает, сколько конкретному сервису действительно нужно.
Вывод простой: quotas задают бюджетные рамки для команд, а rightsizing проверяет, что внутри этих рамок ресурсы не зарезервированы впустую. Поэтому после настройки ограничений нужно перейти к безопасной процедуре пересмотра requests и limits, чтобы экономия не превратилась в несоблюдение SLA.
Как проводить rightsizing без деградации сервиса

ResourceQuota задаёт потолок для namespace, но не отвечает, какие requests и limits безопасны для конкретного сервиса. Этим занимается rightsizing: не разовое “срезание запасов”, а регулярная проверка по данным — с учётом пиков, SLA и реальной возможности освободить ноды.
Главная ошибка — смотреть только на среднее потребление. API-сервис может большую часть суток использовать мало CPU, но во время пика, деплоя или пакетной обработки упираться в ресурс и давать рост latency. Для CPU такая ошибка часто проявляется как throttling. Для памяти цена жёстче: слишком низкие значения могут привести к OOMKilled, eviction и рестартам.
Безопасный rightsizing лучше проводить как процедуру:
- Собрать историческое потребление за полный рабочий цикл сервиса;
- Смотреть не только average, но и p95/p99, пики, сезонность, cron-задачи и окна batch-обработки;
- Анализировать CPU и память отдельно;
- Проверить throttling, OOMKilled, eviction, latency, error rate и нарушения SLO;
- Учитывать тип нагрузки: API, consumer очереди, cron job, batch/ML, stateful-сервис;
- Менять requests и limits постепенно, через релизы и наблюдение;
- После изменений проверять, освободились ли ноды или хотя бы отложилось масштабирование.
Инструменты autoscaling помогают, но не заменяют этот процесс. VPA может давать рекомендации по requests, но автоматический режим в production стоит включать осторожно: он не знает всех бизнес-пиков и требований SLA. HPA меняет число реплик, но не исправляет завышенные requests. Cluster Autoscaler или Karpenter уберут ноды только тогда, когда высвободится целая размещаемая ёмкость.
Поэтому корректный rightsizing — это не просто “снизили requests и стало дешевле”. Нужно подтвердить два результата: сервис не потерял стабильность, а кластер действительно стал лучше размещать Pod’ы. Если ноды не удалились сразу, эффект всё равно может быть полезным: кластер дольше не достигнет порога масштабирования.
Когда requests, quotas и rightsizing приведены в порядок, можно переходить к следующему рычагу экономии — spot-нодам. Но их стоит рассматривать только после базовой оптимизации: дешёвая нода не исправит завышенную заявку Pod’а.
Spot-ноды: где они снижают стоимость, а где создают риск
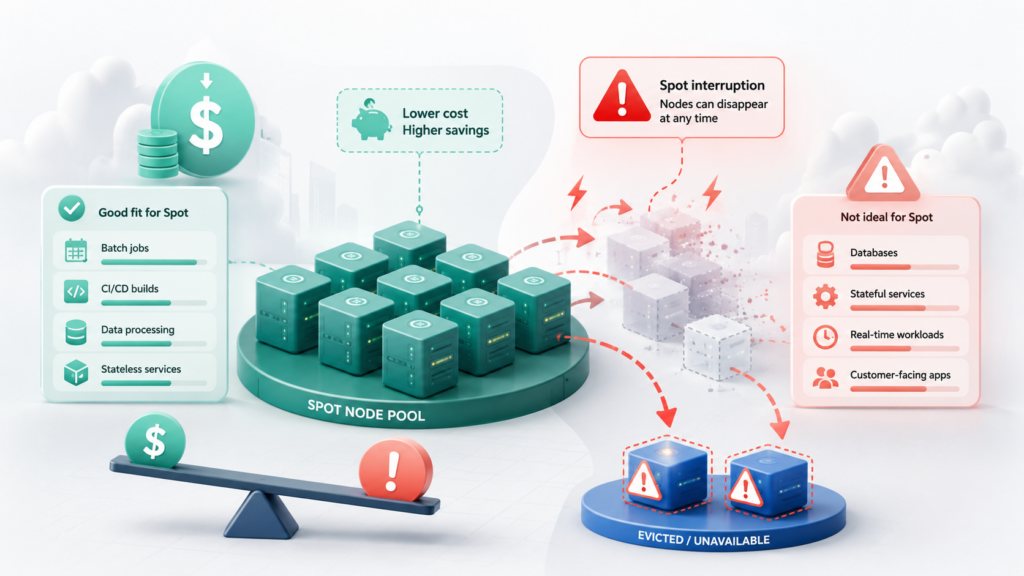
Spot-ноды — это более дешёвая, но прерываемая ёмкость облачного провайдера. Провайдер может забрать такую ноду при нехватке capacity или изменении условий. Для Kubernetes это обычно означает вытеснение Pod’ов, drain или termination ноды и повторный запуск нагрузки на другой ёмкости.
Поэтому решение о переносе на spot нужно принимать не только по цене. Важно понять, выдержит ли приложение внезапную потерю ноды.
Перед переносом стоит проверить:
- Есть ли у сервиса несколько реплик;
- Распределены ли реплики по разным нодам или зонам;
- Умеет ли приложение корректно завершаться через graceful shutdown;
- Можно ли безопасно повторить задачу после прерывания;
- Идемпотентны ли операции, особенно в очередях и batch-обработке;
- Настроены ли PodDisruptionBudget, anti-affinity или topology spread constraints, если они нужны;
- Как прерывание повлияет на соблюдение SLA, latency и error rate.
Практически spot лучше рассматривать как отдельный пул нод с понятными правилами попадания нагрузок. Для этого используют taints/tolerations, node affinity и отдельные node pools. Так команда явно контролирует, какие Pod’ы могут размещаться на прерываемой ёмкости, а какие должны оставаться на regular или on-demand нодах.
Короткая классификация выглядит так:
| Категория | Примеры | Решение |
| Обычно подходят | CI runners, временные окружения, batch jobs, cron jobs, ML-задачи, часть consumer’ов очередей | Можно переносить на spot, если задачи поддерживают повторный запуск и корректное завершение |
| Подходят с условиями | Stateless-сервисы с несколькими репликами, некритичные фоновые обработчики | Нужны реплики на разных нодах/зонах, readiness/liveness probes, graceful shutdown и контроль метрик SLA |
| Лучше не переносить | Базы данных, критичные stateful-сервисы, single-replica приложения, latency-sensitive API, системные компоненты кластера | Прерывание может привести к простою, потере доступности, росту p95/p99 или проблемам восстановления |
Spot-ноды подходят для нагрузок, которые умеют переживать потерю реплики или повторный запуск задачи. Если сервис не выдерживает внезапного вытеснения, экономия может быстро превратиться в инцидент.
Внедрять spot-пул лучше постепенно. Хороший старт — CI, batch-задачи и часть потребителей очередей. После переноса нужно смотреть не только на экономию, но и на частоту вытеснений, время восстановления, рост очередей, повторные запуски задач и влияние на соблюдение SLА.
Если после перехода на spot команда получает нестабильную обработку, рост задержек или ручные вмешательства, такая экономия может быть дороже сохранения нагрузки на предсказуемой ёмкости.
Заключение

Оптимизация расходов в Kubernetes начинается не с дешёвых нод, а с понимания того, сколько ёмкости кластер уже считает занятой. requests влияют на размещение Pod’ов и количество нужных нод, поэтому rightsizing полезен тогда, когда после него улучшается плотность размещения, освобождаются VM или хотя бы откладывается следующее масштабирование.
Практический порядок такой: найти завышенное резервирование CPU и памяти, пересчитать requests и limits с учётом SLA, закрепить рамки через quotas, проверить node pools и autoscaling, а затем переносить подходящие нагрузки на spot. Успешная оптимизация — это не просто низкая загрузка на графике, а меньше оплачиваемой пустующей ёмкости без роста throttling, OOMKilled, eviction и нарушений SLO.
FAQ
Почему кластер дорогой, если CPU и память почти не загружены?
Потому что Kubernetes размещает Pod’ы по requests, а не по среднему фактическому потреблению. Если заявки завышены, ноды считаются занятыми для планировщика, даже когда процессы реально используют мало ресурсов.
Что важнее для экономии: requests или limits?
Для стоимости обычно важнее requests, потому что они влияют на размещение Pod’ов и количество нужных нод. limits ограничивают потребление контейнера после запуска, но сами по себе не уменьшают счёт, если состав нод не меняется.
Как понять, что requests завышены?
Нужно сравнивать историческое потребление с заявками: отдельно CPU и память, не только average, но и p95/p99, пики, cron-задачи и деплойные окна. После изменений важно смотреть throttling, OOMKilled, eviction, latency и нарушения SLA.
Помогают ли ResourceQuota снизить расходы?
Да, но косвенно. Quotas ограничивают суммарные requests и limits в namespace и помогают связать потребление с бюджетом команды. Но они не оптимизируют сервисы автоматически: если внутри quota заявки завышены, перерасход сохранится.
Какие нагрузки можно переносить на spot-ноды?
Обычно подходят stateless-сервисы с несколькими репликами, фоновые обработчики, batch-задачи, CI runners, потребители очередей и другие нагрузки, которые умеют переживать прерывание и повторный запуск.
Какие нагрузки лучше оставить на regular или on-demand нодах?
Базы данных, критичные stateful-сервисы, single-replica приложения, latency-sensitive сервисы, системные компоненты и нагрузки с жёстким SLA лучше держать на предсказуемой ёмкости. На spot их стоит переносить только после отдельной оценки рисков и тестирования отказов.
Список источников
1. Kubernetes Documentation — Resource Management for Pods and Containers


