
В Kubernetes сеть лучше понимать как несколько слоёв, а не как один “сетевой объект”. Pod’ы постоянно меняются: пересоздаются, получают новые IP, переезжают между Node и исчезают при обновлении Deployment. Поэтому напрямую строить доступ вокруг Pod’ов нельзя.
В этой схеме у каждого объекта своя роль:
- Service даёт стабильную точку доступа к группе Pod’ов: постоянное DNS-имя и внутренний адрес.
- Ingress описывает HTTP/HTTPS-маршруты снаружи к Service: например, какой host или path должен попасть в какой backend.
- Gateway API решает похожую задачу входящего трафика, но более формально: с разделением ролей между платформенной командой и командами приложений.
- NetworkPolicy не публикует приложение и не выбирает маршрут. Она отвечает на другой вопрос: какие соединения разрешены между Pod’ами, namespace и внешними адресами.
Главное не смешивать адресацию, маршрутизацию и доступ. Service делает приложение адресуемым, но не делает его защищённым. Ingress и Gateway API помогают направить входящий запрос, но сами по себе не являются сетевой изоляцией. NetworkPolicy ограничивает соединения, но не заменяет Service, Ingress или Gateway.
Практическая цепочка обычно выглядит так: внешний клиент приходит на балансировщик или контроллер входящего трафика, дальше запрос проходит через Ingress или Gateway API, попадает в Service, а Service направляет его к подходящим Pod’ам. Для внутреннего трафика путь короче: один Pod обращается к DNS-имени Service, а Service ведёт к нужной группе Pod’ов.
Поэтому проектировать Kubernetes Networking лучше в таком порядке: сначала понять, кто с кем должен общаться, затем создать Service как стабильную цель, выбрать Ingress или Gateway API для входящего HTTP/HTTPS-трафика и только после этого закрыть лишние связи через NetworkPolicy.
Принцип разделения сетевых задач в Kubernetes

В Kubernetes сетевой доступ не строится вокруг отдельных Pod’ов. Pod может быть пересоздан, получить новый IP, переехать на другой Node или исчезнуть при обновлении Deployment. Если приложение будет обращаться к конкретным IP Pod’ов, такая схема быстро сломается.
Поэтому Kubernetes использует несколько сетевых слоёв. Service скрывает изменчивость Pod’ов и даёт стабильную внутреннюю точку доступа. Ingress и Gateway API описывают правила входящего трафика. NetworkPolicy определяет, какие соединения вообще разрешены.
Эти объекты часто стоят рядом в одной архитектуре, но решают разные задачи. Ошибка начинается там, где от Service ждут защиты, от Ingress — сетевой изоляции, а от NetworkPolicy — маршрутизации. На практике они работают вместе: один слой отвечает за адрес, второй — за входящий маршрут, третий — за разрешения.
Дальше логично сначала разобрать путь запроса в Kubernetes, а затем отдельно пройти Service, Ingress, Gateway API и NetworkPolicy.
Как проходит запрос в Kubernetes

В Kubernetes важно отличать объект с правилами от компонента, который реально обрабатывает трафик. Service, Ingress и Gateway API — это не “одна большая труба”, а разные слои одной цепочки.
Для входящего HTTP/HTTPS-запроса путь обычно выглядит так:
external client
→ cloud Load Balancer
→ Ingress Controller или Gateway Controller
→ Ingress / Gateway + HTTPRoute
→ Service
→ Pod
Service находится ближе к Pod’ам. Он скрывает их изменчивость и даёт стабильную внутреннюю цель: DNS-имя или ClusterIP. Клиент не должен знать IP конкретного Pod’а внутри кластера — он обращается к Service, а Kubernetes направляет трафик к актуальным backend Pod’ам.
Ingress и Gateway API находятся ближе к внешнему входу. Они описывают, какой запрос должен попасть в какой Service: например, app.example.com/api — в api-service, а app.example.com/web — в web-service. Но сами по себе эти объекты не принимают трафик как процесс. Ingress применяет Ingress Controller, а ресурсы Gateway API применяет Gateway Controller.
Для внутреннего трафика цепочка короче:
Pod A → Service DNS / ClusterIP → Pod B
Например, frontend обращается к backend.app.svc.cluster.local, а Service направляет запрос к одному из backend Pod’ов. Если backend Pod пересоздался и получил новый IP, клиенту не нужно ничего менять: Service остаётся стабильной точкой доступа.
NetworkPolicy стоит в другой плоскости. Она не выбирает маршрут и не публикует приложение наружу. Её задача — проверить, разрешено ли соединение между участниками цепочки. То есть Service может сделать backend адресуемым, Ingress или Gateway могут направить к нему внешний запрос, но NetworkPolicy определит, кто действительно имеет право подключаться.
Так проще читать всю Kubernetes-сеть: Service отвечает за стабильную цель, Ingress и Gateway API — за входящий маршрут, а NetworkPolicy — за допустимость соединения. Дальше можно отдельно разобрать Service как базовый слой адресации к Pod’ам.
Service: стабильная точка доступа к Pod’ам

Service — базовый слой адресации в Kubernetes. Он нужен потому, что Pod’ы живут недолго: пересоздаются, меняют IP, переезжают между Node и обновляются вместе с Deployment. Клиенту не стоит обращаться к конкретному IP Pod’а, потому что такой адрес может быстро перестать существовать.
Вместо этого приложение обращается к Service. Например, frontend может идти не на IP backend Pod’а, а на стабильное имя backend.default.svc.cluster.local. Kubernetes сам поддерживает связь между Service и актуальным набором Pod’ов.
Упрощённо цепочка выглядит так:
labels на Pod’ах
→ selector в Service
→ EndpointSlice с актуальными адресами
→ DNS-имя или ClusterIP Service
→ backend Pod’ы
Service выбирает Pod’ы через selector. Например, если backend Pod’ы имеют метку app: backend, Service с таким же selector будет направлять трафик к этим Pod’ам. Когда Pod’ы масштабируются, обновляются или пересоздаются, Kubernetes обновляет EndpointSlice, а клиент продолжает использовать то же DNS-имя или ClusterIP.
Тип Service определяет, где и как эта стабильная точка будет доступна. Важно не смешивать это с другими задачами: Service не описывает HTTP-маршруты, не управляет TLS и не является политикой безопасности. Основные варианты такие:
| Тип Service | Где доступен | Когда использовать |
| ClusterIP | Внутри кластера | Внутренние вызовы между приложениями |
| NodePort | Через порт на каждом Node | Промежуточный доступ, часто под внешний балансировщик |
| LoadBalancer | Через внешний балансировщик провайдера | Прямая публикация одного сервиса наружу |
| ExternalName | Как DNS-алиас | Обращение к внешнему имени через Kubernetes Service |
ClusterIP — основной вариант для внутренних сервисов. Он не публикует приложение наружу, но даёт стабильную цель внутри кластера.
NodePort открывает порт на каждом Node. Сейчас его часто используют как промежуточный слой под внешний балансировщик или в специфичных сценариях, но он не даёт маршрутизацию по домену и пути.
LoadBalancer создаёт внешний балансировщик через интеграцию с облачным провайдером. Это удобно для прямой публикации одного сервиса, но не заменяет Ingress или Gateway API, если нужно маршрутизировать несколько приложений по host/path.
ExternalName работает как DNS-алиас на внешнее имя. Он не создаёт ClusterIP и не балансирует трафик на Pod’ы.
Главный вывод: Service делает Pod’ы адресуемыми через стабильное имя и адрес. Но он не решает все сетевые задачи. Для входящего HTTP/HTTPS-трафика нужны Ingress или Gateway API, а для ограничения соединений — NetworkPolicy.
Ingress: HTTP/HTTPS-маршрутизация к Service

После Service появляется следующий вопрос: как внешний HTTP/HTTPS-запрос должен попасть к нужному приложению внутри кластера. Для этого в Kubernetes часто используют Ingress.
Ingress описывает правила маршрутизации по имени хоста и пути. Например, один домен может вести к разным внутренним Service:
app.example.com/api → api-service
app.example.com/web → web-service
В этом сценарии внешний клиент обращается к app.example.com. Запрос приходит на входной балансировщик и дальше попадает в Ingress Controller. Контроллер читает правила Ingress и выбирает, к какому Service направить запрос: /api — в api-service, /web — в web-service.
Важно различать Ingress как объект и Ingress Controller как компонент. Ingress сам по себе — это набор правил в Kubernetes API. Реальный трафик принимает и обрабатывает контроллер: например, NGINX Ingress Controller, Traefik, HAProxy, cloud-controller или другой выбранный вариант.
Ingress удобен как единая точка входа для нескольких внутренних Service. Вместо отдельного LoadBalancer для каждого приложения можно использовать общий входящий слой и декларативно описывать правила маршрутизации.
Основная зона ответственности Ingress выглядит так:
- Маршрутизация HTTP/HTTPS по host и path;
- TLS-терминация;
- Направление запроса к Service;
- Базовые правила входа для web/API-приложений.
При этом Ingress не заменяет Service и не является механизмом сетевой изоляции. Он направляет входящий запрос, но не отвечает за то, какие Pod’ы имеют право общаться между собой. Для этого нужен NetworkPolicy.
У Ingress есть и практическое ограничение: многие расширенные возможности зависят от конкретного контроллера и его аннотаций. Пока маршрутов мало, это обычно не мешает. Но в много командных кластерах инфраструктурные настройки, прикладные правила и controller-specific annotations могут начать смешиваться. В таких случаях стоит смотреть в сторону Gateway API.
Gateway API: более управляемая модель входящего трафика
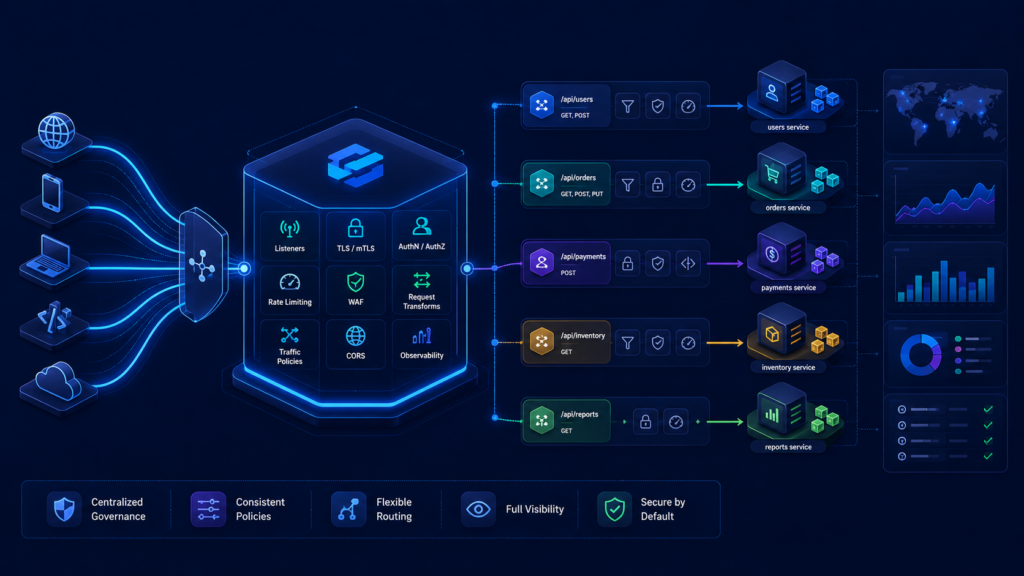
Gateway API решает похожую задачу: описывает входящий L4/L7-трафик к приложениям в Kubernetes. Но делает это более формально и с явным разделением ролей. Его не стоит путать с продуктовым API Gateway для авторизации, rate limiting и бизнес-логики API. В Kubernetes Gateway API — это набор ресурсов, которые описывают вход, маршруты и связь с контроллером.
Базовая модель строится вокруг трёх объектов:
| Объект | За что отвечает |
| GatewayClass | Указывает класс реализации и связанный Gateway Controller |
| Gateway | Описывает инфраструктурную точку входа: listeners, протоколы, домены |
| HTTPRoute | Задаёт прикладные правила маршрутизации к Service |
Главное отличие от Ingress — более понятное разделение ответственности. Платформенная команда может управлять GatewayClass и общим Gateway, а команды приложений — создавать свои HTTPRoute в разрешённых namespace.
Например, платформа создаёт общий HTTPS-вход для *.example.com, а команда приложения описывает маршрут:
app.example.com/api → api-service
В такой модели команда приложения не управляет всей входной инфраструктурой, но может безопасно добавлять свои маршруты в рамках разрешённых правил. Это особенно полезно, когда в кластере много команд, общие домены, несколько namespace и требования к делегированию.
Gateway API помогает уменьшить зависимость от неформальных аннотаций и лучше подходит для сценариев, где нужны общие точки входа, разделение инфраструктурной и прикладной ответственности, более строгие правила подключения маршрутов и расширяемая модель трафика.
Но Gateway API не обязан заменять Ingress в каждом кластере. Для простого HTTP/HTTPS-входа Ingress часто остаётся достаточным: один контроллер, несколько host/path-правил, понятная публикация Service. Gateway API становится полезнее там, где входящий трафик уже нужно не просто “пробросить к сервису”, а управлять им как частью платформы.
После Ingress и Gateway API можно сравнить все три объекта — Service, Ingress и Gateway API — по задачам, чтобы окончательно не смешивать адресацию, входящую маршрутизацию и сетевые разрешения.
Service, Ingress и Gateway API: сравнение по задачам
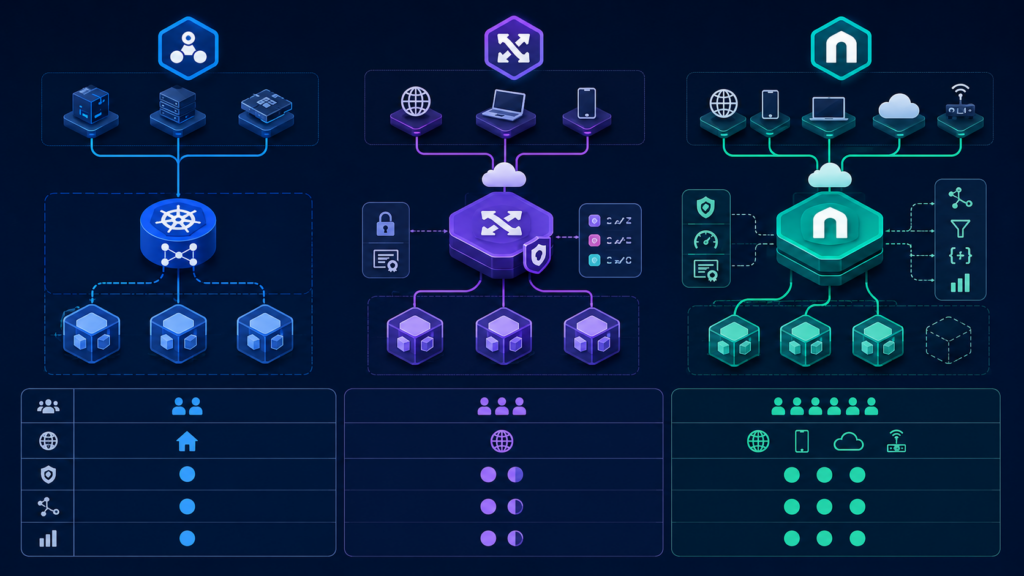
Все они работают на разных участках сетевой цепочки. Service даёт стабильную цель внутри кластера, Ingress описывает базовую HTTP/HTTPS-маршрутизацию, а Gateway API помогает формальнее управлять входящим трафиком и разделять роли между командами.
Удобнее сравнивать их по задаче:
| Объект | Основная задача | Типичный сценарий | Что не делает |
| Service | Стабильная адресация группы Pod’ов | frontend → backend Service | Не маршрутизирует HTTP по host/path и не задаёт права доступа |
| Ingress | HTTP/HTTPS-маршрутизация к Service | app.example.com/api → api-service | Не заменяет Service и не является сетевой политикой |
| Gateway API | Более ролевая модель входящего трафика | Общий Gateway и отдельные HTTPRoute для команд | Не нужен для каждого простого маршрута и не ограничивает Pod-to-Pod трафик |
Service нужен почти всегда как стабильная внутренняя цель. Ingress выбирают для стандартной HTTP/HTTPS-публикации. Gateway API уместен, когда входящий трафик должен управляться более формально: через общие точки входа, делегирование маршрутов и разделение инфраструктурной и прикладной ответственности.
NetworkPolicy в эту таблицу не попадает как альтернатива, потому что решает другую задачу. Она не публикует приложение и не выбирает маршрут. Она отвечает на вопрос, какие соединения разрешены поверх уже существующей адресации и маршрутизации.
NetworkPolicy: сетевые разрешения, а не маршрутизация
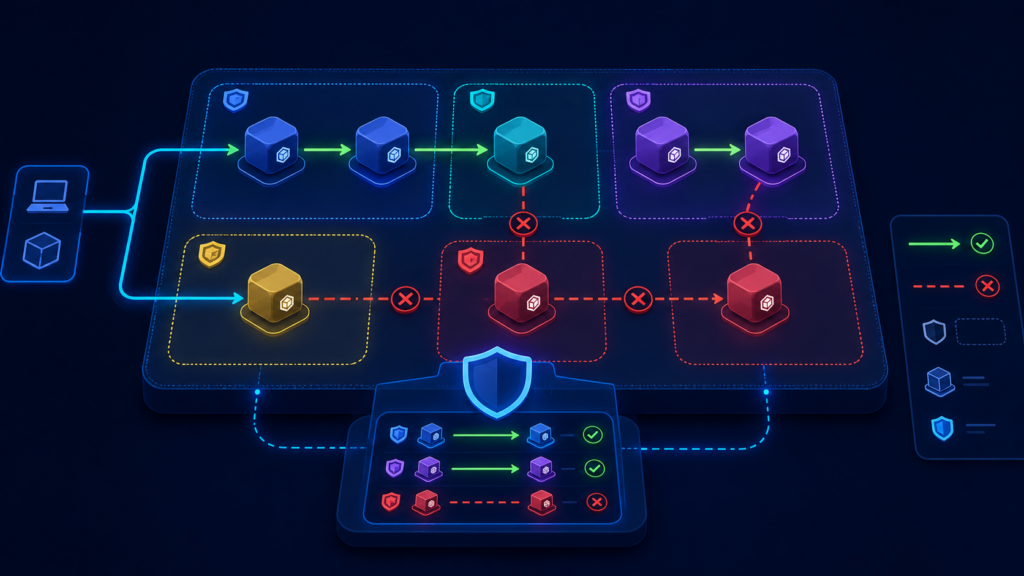
После Service, Ingress и Gateway API остаётся последний слой — сетевые разрешения. NetworkPolicy отвечает не на вопрос “куда направить запрос”, а на вопрос “разрешено ли это соединение”.
Service делает Pod’ы адресуемыми. Ingress и Gateway API направляют входящий HTTP/HTTPS-запрос к нужному Service. NetworkPolicy ограничивает, кто может подключаться к выбранным Pod’ам и куда эти Pod’ы могут ходить сами.
Проще всего думать о NetworkPolicy как о правилах доступа:
- Сначала политика выбирает Pod’ы, которые нужно защитить;
- Затем описывает, от кого им можно принимать входящие соединения;
- Отдельно описывает, куда им можно отправлять исходящие соединения;
- Всё, что не попало в разрешения, блокируется для выбранных Pod’ов.
В стандартной NetworkPolicy нет привычного правила deny. Запрет появляется иначе: если Pod выбран политикой, но нужное соединение не разрешено, оно не проходит. Если Pod вообще не выбран никакой NetworkPolicy, он обычно остаётся неизолированным.
Базовые принципы такие:
- PodSelector выбирает Pod’ы, к которым применяется политика;
- Ingress ограничивает входящие подключения к выбранным Pod’ам;
- Egress ограничивает исходящие подключения из выбранных Pod’ов;
- NamespaceSelector нужен, когда источник или цель находятся в другом namespace;
- фактическая работа NetworkPolicy зависит от CNI-плагина.
Если сетевой плагин не поддерживает NetworkPolicy, манифесты могут успешно создаваться в Kubernetes API, но ожидаемой изоляции не будет.
На практике NetworkPolicy удобнее разбирать через три простых сценария: закрыть всё по умолчанию, разрешить frontend ходить в backend и ограничить связи между namespace.
Сценарий 1. Закрыть всё по умолчанию
Default deny — это стартовая политика “ничего не разрешено, пока мы не разрешили явно”. Она выбирает все Pod’ы в namespace и запрещает для них входящий и исходящий трафик, если нет отдельных разрешающих правил.
Это полезно, когда команда хочет перейти от открытой сети к контролируемой модели. Сначала namespace закрывают, затем добавляют только нужные исключения: доступ к DNS, backend, базе данных, брокеру, мониторингу или внешнему API.
Самая частая ошибка после default deny — забыть про DNS. Pod может быть живым, Service может существовать, но приложение перестанет резолвить имена вроде backend.app.svc.cluster.local, если не разрешить исходящие запросы к CoreDNS.
Поэтому смысл default deny не в том, чтобы “сломать всё”, а в том, чтобы поменять подход: не искать, что запретить, а явно перечислять, что разрешить. Такой подход иногда называют "нормально-закрытым фаерволом".
Сценарий 2. Разрешить frontend ходить в backend
Допустим, в namespace app есть frontend и backend. Frontend должен ходить в backend на порт 8080, а остальные Pod’ы — нет.
Здесь NetworkPolicy выбирает backend Pod’ы и говорит: входящий трафик к ним разрешён только от Pod’ов с меткой app: frontend на нужный порт. Всё остальное для backend не разрешено.
Service при этом продолжает работать. Имя backend.app.svc.cluster.local может успешно резолвиться у всех. Но резолвинг имени не означает право подключиться. Неавторизованный Pod увидит адрес, но соединение будет заблокировано политикой.
Так проще запомнить разницу:
- Service отвечает: “где backend?”;
- NetworkPolicy отвечает: “можно ли этому Pod’у подключиться к backend?”.
Если frontend находится в другом namespace, нужно разрешить не только метку Pod’а, но и namespace, откуда приходит трафик. Для этого используют namespaceSelector.
Сценарий 3. Ограничить трафик между namespace
В много командном кластере часто нужно, чтобы Pod’ы внутри одного namespace общались между собой, но не ходили напрямую в namespace другой команды.
Здесь политика выбирает все Pod’ы в namespace и разрешает им принимать и отправлять трафик только внутри этого же namespace. Например, Pod’ы team-a могут общаться друг с другом, но не получают автоматического доступа к Pod’ам из team-b.
Важная деталь: podSelector без namespaceSelector работает только внутри namespace, где создана политика. Поэтому правило “разрешить Pod’ы с podSelector: {}” означает “разрешить Pod’ы в этом namespace”, а не во всём кластере.
Для реальной изоляции такую модель нужно применять во всех namespace, где она нужна. И почти всегда придётся добавить исключения: DNS, ingress-controller, Gateway Controller, мониторинг, service mesh или внешние управляемые сервисы.
Эти сценарии дают базовую логику: сначала выбрать защищаемые Pod’ы, затем явно разрешить нужные связи и отдельно проверить системные зависимости. Если после этого что-то не работает, проблему обычно ищут в метках, namespace, policyTypes, DNS или поддержке NetworkPolicy со стороны CNI.
Что проверять при отладке NetworkPolicy

Проблемы с NetworkPolicy часто выглядят одинаково: “сервис не отвечает”. Но причина может быть не в политике. Сначала нужно убедиться, что сам маршрут работает: Pod существует, Service выбирает нужные Pod’ы, DNS-имя резолвится, порт открыт, а Ingress или Gateway действительно направляет запрос к нужному Service.
После этого можно проверять NetworkPolicy. Удобнее идти по цепочке:
- Кого защищает политика. Нужно проверить, выбирает ли podSelector именно те Pod’ы, которые нужно изолировать. Частая ошибка — метки в policy не совпадают с метками реальных Pod’ов.
- Кто является источником трафика. Если доступ должен быть только от frontend, нужно проверить метки frontend Pod’ов. Если источник находится в другом namespace, одного podSelector недостаточно: потребуется namespaceSelector.
- Какой тип трафика ограничивается. Ingress отвечает за входящие подключения к выбранным Pod’ам, Egress — за исходящие подключения из них. Если забыть нужный policyTypes, поведение может отличаться от ожиданий.
- Не сломан ли DNS. После default deny egress Pod’ы часто теряют доступ к CoreDNS. В результате приложение не может обратиться к Service по имени, хотя сам Service и backend работают.
- Поддерживает ли CNI NetworkPolicy. Kubernetes API может принять манифест NetworkPolicy, но реальную изоляцию выполняет сетевой плагин. Если CNI не поддерживает NetworkPolicy, правила не дадут ожидаемого эффекта.
- Нужны ли системные исключения. Часто нужно отдельно разрешить доступ от ingress-controller или Gateway Controller к Pod’ам приложения, а также egress к мониторингу, внешней базе, брокеру, объектному хранилищу или API.
NetworkPolicy лучше проектировать после понимания маршрута. Сначала описывают путь запроса: external client → Ingress/Gateway → Service → Pod или Pod → Service → Pod. Затем для каждого участка задают только те соединения, которые действительно нужны.
Так NetworkPolicy становится не случайным набором запретов, а последним слоем сетевой модели: адрес уже есть, маршрут понятен, теперь нужно ограничить доступ.
Заключение

В Kubernetes сетевую задачу нужно раскладывать по слоям. Service даёт стабильную внутреннюю точку доступа к изменяемому набору Pod’ов. Ingress и Gateway API описывают входящую HTTP/HTTPS-маршрутизацию и требуют контроллера, который применяет эти правила. NetworkPolicy не публикует приложение и не выбирает маршрут, а ограничивает допустимые соединения.
Практический порядок простой: сначала определить, кто с кем должен взаимодействовать, затем использовать Service как стабильную цель, выбрать Ingress или Gateway API для входящего трафика и закрыть лишние связи через NetworkPolicy. Отдельно нужно проверить исключения: DNS, системные контроллеры, мониторинг и внешние зависимости. Такой подход снижает риск типичных ошибок: считать Service границей безопасности, ждать изоляции от Ingress или создавать отдельный LoadBalancer для каждого HTTP-маршрута.
FAQ
Чем Service отличается от Ingress?
Service даёт стабильный адрес и DNS-имя для группы Pod’ов. Ingress описывает HTTP/HTTPS-правила входящего трафика по host и path и направляет запросы к Service через Ingress Controller.
Когда выбирать Gateway API вместо Ingress?
Gateway API уместен, когда нужно разделить ответственность между платформенной и прикладной командами, управлять общими точками входа и описывать более выразительные маршруты. Для простых HTTP/HTTPS-сценариев Ingress часто остаётся достаточным.
Является ли Service границей безопасности?
Нет. Service делает Pod’ы адресуемыми, но сам по себе не ограничивает, кто может к ним подключаться. Для сетевых разрешений используют NetworkPolicy и, если нужно, дополнительные механизмы безопасности.
Почему Ingress или Gateway API не работают без контроллера?
Ingress, Gateway и HTTPRoute — это декларативные объекты Kubernetes. Они хранят правила, но не обрабатывают трафик сами. Реальную работу выполняет установленный Ingress Controller или Gateway Controller.
Что происходит с трафиком, если NetworkPolicy не настроены?
Обычно трафик остаётся разрешённым, пока Pod’ы не изолированы политиками. NetworkPolicy работает по модели разрешающих правил: после изоляции нужно явно описать допустимые ingress- и egress-соединения.
Почему default deny egress может сломать DNS?
Если запретить весь исходящий трафик из Pod’ов, они могут потерять доступ к kube-dns или CoreDNS. В результате перестанут резолвиться имена Service и внешние домены, поэтому DNS нужно разрешать отдельным правилом.
Список источников
1. Kubernetes Documentation — Service
2. Kubernetes Documentation — Ingress


