Disaster Recovery в облаке для SMB начинается не с выбора «самой надёжной» архитектуры, а с двух бизнес-вопросов: сколько компания может позволить себе простоя и сколько данных может потерять без неприемлемого ущерба. Эти ответы выражаются через такие метрики, как RTO и RPO, но задавать их одной цифрой для всей инфраструктуры нельзя: интернет-магазин, CRM, платежи, почта и архивы имеют разную критичность.
Одних бэкапов часто недостаточно. Резервная копия помогает вернуть данные, но не гарантирует, что приложение быстро запустится вместе с DNS, доступами, сертификатами, интеграциями и платёжным контуром. Поэтому SMB обычно используют смешанный подход: некритичные системы оставляют на схеме восстановления backup-only, важные сервисы переводят в pilot light, а выручку и клиентские обязательства защищают через warm standby.
Подход типа active-active нужен редко — только там, где простой дороже постоянной сложности такой архитектуры. При этом рабочий план восстановления (DRP, Disaster Recovery Plan) — это не просто схема на бумаге, а проверенный план: критичные сервисы, зависимости, порядок восстановления, ответственные, критерии запуска и регулярные тесты.
Что такое Disaster Recovery в облаке и чем оно отличается от backup, HA и business continuity
Бэкапы есть, счёт за облако оплачен, мониторинг до аварии был зелёным. А потом сервис не поднимается: DNS смотрит не туда, доступы завязаны на недоступный SSO, сертификат просрочен, интеграция с платежами молчит, а порядок действий хранится в голове инженера, который сегодня вне связи.
На бумаге компания «защищена». На практике бизнес не принимает заказы, не видит CRM и не может назвать клиентам срок восстановления.
Облако помогает быстро выдавать ресурсы, хранить копии, реплицировать данные и запускать резервные среды. Но оно не знает, какой сервис для компании критичнее: интернет-магазин, CRM, складской учёт или вообще почта. И точно не назначит ответственного, который в момент аварии примет решение о переключении.
Disaster Recovery — это управляемое аварийное восстановление ИТ-сервисов после серьёзного сбоя: отказа облачного региона, потери основной среды, ошибки конфигурации, инцидента безопасности или недоступности важного провайдера. Важно не просто вернуть данные, а восстановить бизнес-функцию: сервис принимает заказы, сотрудники входят в систему, интеграции работают, ответственные понимают каждый следующий шаг.
Чтобы не строить план на неверном слове, полезно развести соседние практики.
| Практика | На какой вопрос отвечает | Что даёт | Чего не гарантирует |
| Резервное копирование | Куда вернуться по данным? | Точку возврата, защиту от удаления, порчи или шифрования данных | Что приложение поднимется и бизнес-процесс заработает |
| Высокая доступность | Как снизить вероятность локального простоя? | Отказоустойчивость компонентов, балансировку, резервирование | Восстановление после крупной аварии всей среды |
| Disaster Recovery | Как вернуть сервис после серьёзного сбоя? | План, роли, среду восстановления, порядок переключения и проверки | Полную работу компании вне ИТ-процессов |
| Непрерывность бизнеса | Как компания продолжает работать во время кризиса? | Регламенты для сотрудников бэкофиса, клиентов, операций, финансов и ИТ | Техническую реализацию восстановления сама по себе |
DR не заменяет backup, высокую доступность или план непрерывности бизнеса. Он связывает их с конкретной целью — вернуть в работу сервис, который нужен для продаж, поддержки, производства или исполнения договоров.
Для SMB эта граница особенно важна: бюджет ограничен, команда небольшая, а инфраструктура часто состоит из облачных сервисов, SaaS-платформ и внешних провайдеров. Когда backup, HA и DR не смешиваются в одно слово «надёжность», исчезает ложное чувство безопасности и появляется основа для расчёта.
RTO и RPO: как перевести простой и потерю данных на язык бизнеса

После определения границ появляется главный вопрос: насколько быстро нужно восстановиться и какую потерю данных бизнес способен пережить. Ответ не может дать только IT. Сервер можно поднять за час, но за этот час компания уже потеряет платежи, сорвёт SLA или заставит отдел продаж вручную собирать заявки из почты и мессенджеров.
Здесь нужны две метрики.
RTO (Recovery Time Objective) — целевое время восстановления. Это максимально допустимое время, в течение которого конкретный сервис может быть недоступен без неприемлемого ущерба. Для интернет-магазина даунтайм корзины и оплаты на два часа может быть критичен. Для внутреннего архива договоров те же два часа, а иногда и сутки, не блокируют текущие продажи.
RPO (Recovery Point Objective) — целевая точка восстановления. Она отвечает не за длительность простоя, а за глубину возможной потери данных: насколько далеко назад бизнес готов откатиться после сбоя. Если RPO равен одному часу, компания принимает риск потерять изменения максимум за последний час: заказы, обновления в CRM, статусы оплат, правки в документах. Если эти данные нельзя восстановить из внешних систем или переписки, цена такого часа становится материальной.
RTO и RPO нельзя задавать одной цифрой для всей компании. В одной SMB-компании интернет-магазин может требовать восстановления за десятки минут и минимальной потери заказов. CRM способна пережить несколько часов простоя, если менеджеры временно фиксируют сделки вручную. Файловое хранилище с архивами может восстанавливаться дольше, если не участвует в текущих контрактах.
Перед назначением целей бизнесу и IT стоит вместе ответить:
- Сколько денег теряется за час простоя;
- Какие обязательства перед клиентами и партнёрами нарушаются;
- Можно ли временно работать вручную;
- Какие данные невозможно восстановить из внешних источников;
- Какие сервисы блокируют продажи, поддержку или исполнение договоров;
- Где простой превращается в репутационный ущерб.
Эти вопросы меняют смысл фразы «сколько стоит DR в облаке». Точнее спрашивать так: какой риск компания готова принять и за какую защиту действительно имеет смысл платить.
У нулевого простоя и нулевой потери данных есть цена: более дорогая архитектура, постоянная репликация, сложное тестирование, повышенные требования к команде и дисциплине изменений. Поэтому RTO и RPO нужны не для красивой таблицы, а как фильтр: где хватит восстановления из копий, где нужна резервная среда, а где почти непрерывная работа оправдана выручкой, контрактами или регуляторными требованиями, и обязательно формируется совместно как с бизнес-, так и с ИТ-подразделениями.
Почему сервисы SMB нельзя защищать одинаково
Если CRM, платежи и архив документов получают одинаковую защиту, бизнес почти наверняка ошибается. Либо он переплачивает за быструю готовность систем, которые можно восстановить позже, либо экономит там, где простой сразу превращается в потерянные заказы, ручную работу и претензии по контрактам.
После расчёта RTO/RPO следующий шаг — не список серверов, а карта бизнес-функций. Критичность определяется не тем, насколько «важным» выглядит сервер, а тем, что сломается в бизнес-процессе.
Сайт или интернет-магазин
Сайт держит витрину, приём заявок, корзину и оформление заказов. Если продажи идут онлайн, его критичность обычно высокая: простой быстро отражается на выручке и заявках.
Типичные зависимости — DNS, сертификаты, база товаров, платёжный шлюз, внешние API, CDN и доступ к административной панели.
CRM
CRM отвечает за сделки, коммуникации и историю клиентов. Для продаж и поддержки это часто один из ключевых сервисов: без него менеджеры теряют контекст, не видят статусы и вынуждены вести заявки вручную.
Зависимости обычно включают IAM/SSO, почту, телефонию, интеграции с сайтом, складом и внутренними системами.
Почта
Почта нужна для переписки, уведомлений, подтверждений и связи с клиентами. Её критичность зависит от того, насколько компания завязана на email в продажах, поддержке и операционных процессах.
При восстановлении важны DNS-записи, аккаунты, антиспам, доступ администратора и резервные каналы связи.
База заказов и клиентов
База заказов и клиентов хранит факты продаж, статусы, обязательства и историю операций. Обычно это высококритичный слой: приложение можно поднять заново, но без актуальных данных бизнес не сможет нормально принимать заказы и обслуживать клиентов.
Ключевые зависимости — хранилище данных, резервные копии, репликация, ключи доступа, сеть и права команды на восстановление.
Файловое хранилище
Файловое хранилище держит договоры, документы и рабочие файлы. Его критичность может быть средней или высокой: архивы иногда можно восстановить позже, а документы по текущим контрактам могут понадобиться сразу.
Зависимости — IAM/SSO, права доступа, VPN, ключи шифрования и понятный порядок восстановления нужных папок, а не всего хранилища сразу.
Платежи
Платёжный контур отвечает за оплату, возвраты и финансовый поток. Для онлайн-продаж это критичный сервис: сайт может открываться, но без оплаты бизнес всё равно не принимает заказы полноценно.
Здесь важны платёжный шлюз, секреты, API банка, сертификаты, разрешённые IP-адреса и контакты поддержки провайдера.
Из такой карты видно: SMB редко нужен одинаковый уровень DR для всех систем. Сначала защищают сервисы, которые прямо влияют на деньги, клиентов и обязательства, затем распределяют ресурсы на менее критичные функции.
Отдельный слой — зависимости. Их часто считают техническими деталями, пока восстановленный сервис не оказывается недоступен из-за DNS, недействительного сертификата, закрытой сети или SSO, который остался в упавшей среде.
В облачном DR это особенно заметно: виртуальные машины можно поднять быстро, но без доступа к облачному аккаунту, секретов, ключей, VPN и прав у команды восстановление останавливается на ровном месте.
Почему backup-only не закрывает весь путь восстановления
Карта критичности показывает, что у сервисов разные зависимости. В аварии это превращается в цепочку блокировок: база интернет-магазина восстановлена из копии, данные заказов на месте, а новые покупки не проходят. Приложение не стартует из-за устаревших секретов, DNS ведёт на старую среду, SSO недоступен, платёжный шлюз отклоняет запросы с нового адреса.
Backup-only — подход, где основная защита строится на резервных копиях. Компания хранит данные и при сбое разворачивает сервис заново: в прежней среде, если она жива, или в новой облачной площадке. Это самый дешёвый и понятный нижний уровень DR: меньше постоянных ресурсов, проще эксплуатация, ниже счёт за облако.
Проблема в границе ответственности. Бэкап помогает приблизиться к нужному RPO: есть точка, к которой можно вернуть данные. Но сам по себе он не гарантирует RTO, потому что время восстановления съедает не только загрузка дампа или снимка диска. После данных нужно собрать вокруг них рабочую систему:
- Вычислительные ресурсы, образы, версии приложений и конфигурации;
- Сеть, маршруты, VPN и межсетевые правила;
- IAM/SSO или аварийные админ-доступы;
- DNS-записи и порядок переключения трафика;
- Сертификаты, секреты и ключи API;
- Очереди, интеграции, внешние API и платёжные шлюзы;
- Мониторинг, логи и техническую проверку;
- Бизнес-проверку: заказ создан, CRM открылась, платёж подтверждён.
Если эти элементы не описаны заранее, backup-only превращается в ручной проект в момент стресса. Формально данные сохранены, но бизнес продолжает стоять.
Это не делает backup-only плохой стратегией. Для архивов, внутренних отчётов, файловых хранилищ без срочных операций, тестовых сред и некритичных сайтов он часто разумен. Но для базы заказов, платежей, операционной CRM, клиентского SaaS и e-commerce-процессов такой подход легко создаёт ложную экономию.
Четыре облачные DR-стратегии как шкала стоимости и скорости

Следующий выбор — степень готовности резервной среды. Это не набор независимых архитектур, а шкала: чем ближе резерв к рабочему состоянию до аварии, тем меньше ручной сборки в момент сбоя и тем выше постоянный счёт за инфраструктуру, репликацию, мониторинг, автоматизацию и тесты.
Упрощённо эту шкалу можно представить так: backup-only → pilot light → warm standby → active-active. Слева — меньше постоянных расходов, но больше ручной работы при аварии. Справа — быстрее восстановление, но выше цена, сложность и требования к команде.
Backup-only
Данные сохранены, но среду собирают после аварии. До инцидента есть резервные копии и, в лучшем случае, инструкции по развёртыванию. Во время аварии команда поднимает инфраструктуру, восстанавливает данные, настраивает сеть, доступы и проверяет приложение.
RTO здесь обычно самый длинный, а RPO зависит от частоты копирования. Такой подход подходит для архивов, отчётности и сервисов, которые бизнес готов ждать.
Следующий уровень — не полная резервная площадка, а заранее подготовленное «ядро», которое можно быстро развернуть до рабочей среды.
Pilot light
Резервное ядро уже готово. В облаке заранее подготовлены базовые компоненты: сеть, шаблоны инфраструктуры, минимальные базы или реплики, ключевые конфигурации. Во время аварии это ядро разворачивают до рабочего масштаба: добавляют вычислительные ресурсы, включают приложения и переключают трафик.
RTO ниже, чем у backup-only, но появляются постоянные расходы на минимальную среду и регулярные проверки. Для SMB это часто разумный уровень для CRM, портала заявок и внутренних систем продаж.
Если бизнесу нужно ещё меньше ручной сборки во время сбоя, резервная среда должна не просто ждать развёртывания, а уже работать в резервной среде, хоть и в облегчённом режиме.
Warm standby
Уменьшенная копия уже работает. Резервная среда запущена постоянно, но в меньшем размере: принимает тестовую или небольшую нагрузку, получает актуальные данные и проходит мониторинг. При аварии её масштабируют и переводят в основной режим.
RTO становится заметно короче, RPO — ближе к текущему состоянию данных. Но эксплуатация усложняется: нужно следить за синхронизацией, версиями приложений, схемами баз и лимитами облака. Такой подход подходит для интернет-магазина, клиентского кабинета, базы заказов и B2B-портала.
Самый дорогой вариант — когда резервная площадка перестаёт быть резервной и участвует в работе постоянно.
Active-active
Несколько площадок обслуживают нагрузку одновременно. Здесь резервная среда перестаёт быть «резервной»: площадки работают параллельно, трафик распределяется между ними, данные синхронизируются почти непрерывно. В аварии переключение выглядит как перераспределение нагрузки.
Но сложность живёт каждый день: согласованность данных, конфликтующие записи, сетевые задержки, мониторинг, тестирование отказов, дорогая архитектура и команда, которая умеет этим управлять. Для SMB active-active оправдан только там, где простой стоит дороже постоянной сложности.
Быстрый DR дороже, потому что бизнес заранее покупает время. Он платит не только за серверы, а за готовность среды, актуальные конфигурации, проверенную репликацию и людей, которые регулярно тестируют сценарий.
Матрица выбора DR-стратегии по RTO/RPO, бюджету и сложности
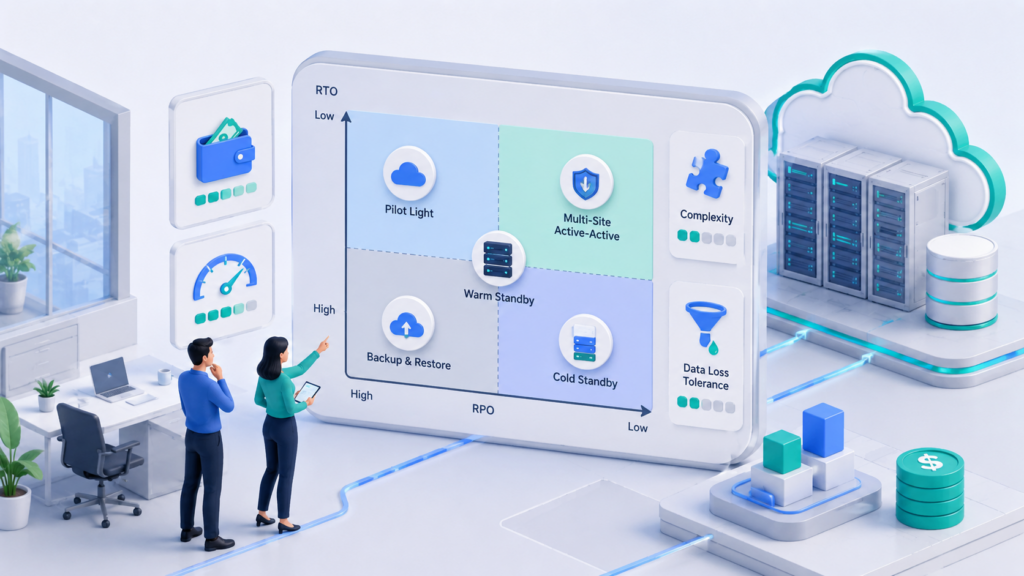
На бумаге хочется выбрать самый быстрый вариант для всех систем. В реальности SMB редко тянет одну DR-стратегию на всю компанию: интернет-магазину нужна быстрая защита заказов и платежей, CRM может жить на более лёгком сценарии, внутренняя отчётность спокойно подождёт восстановления из копии.
Матрица выбора нужна не для поиска «лучшей» стратегии, а для первичного сопоставления требований сервиса с ценой и сложностью. Сначала определяют RTO и RPO для конкретного сервиса, затем оценивают постоянный бюджет: облачные ресурсы, репликацию, автоматизацию, мониторинг, тесты, время и состав команды.
Backup-only
Когда подходит: архивы, отчётность, некритичные файлы, тестовые среды и сервисы, которые бизнес готов восстанавливать часами или днями.
Типичный RTO/RPO: RTO — часы или дни. RPO — часы или сутки, в зависимости от частоты копий.
Цена и сложность: постоянный бюджет низкий, эксплуатация до аварии простая. Основная сложность переносится в момент восстановления.
Ограничение: легко не уложиться в RTO из-за ручной сборки среды, сети, доступов, DNS и зависимостей.
Pilot light
Когда подходит: CRM, порталы заявок, внутренние системы продаж и важные сервисы, которым не нужна мгновенная готовность, но которые нельзя восстанавливать с нуля.
Типичный RTO/RPO: RTO — десятки минут или часы. RPO — минуты или часы, в зависимости от репликации.
Цена и сложность: бюджет низкий или средний. Сложность умеренная: резервное ядро нужно поддерживать актуальным и регулярно проверять.
Ограничение: масштабирование и переключение требуют заранее отработанного сценария. Если ядро устарело, восстановление снова превращается в ручной проект.
Warm standby
Когда подходит: база заказов, клиентский кабинет, B2B-портал, платёжный контур и системы, которые прямо влияют на выручку или обязательства перед клиентами.
Типичный RTO/RPO: RTO — минуты или десятки минут. RPO — минуты, иногда ближе к текущему состоянию данных.
Цена и сложность: бюджет средний или высокий. Сложность высокая: резервная среда работает постоянно, но в уменьшенном размере.
Ограничение: нужен постоянный контроль синхронизации, версий приложений, схем баз, лимитов облака и готовности команды к переключению.
Active-active
Когда подходит: критичные SaaS-сервисы, онлайн-продажи с высокой ценой простоя, жёсткие SLA и системы, где даже короткий отказ стоит дороже постоянной сложности.
Типичный RTO/RPO: RTO — секунды или минуты. RPO — секунды или минуты.
Цена и сложность: бюджет очень высокий, сложность тоже очень высокая. Команда должна постоянно поддерживать распределённую архитектуру, мониторинг и отказные тесты.
Ограничение: дорогая архитектура, сложная согласованность данных, конфликтующие записи, сетевые задержки и высокая цена ошибок в изменениях.
Для SMB чаще всего получается смешанная картина: некритичные сервисы остаются на backup-only, важные, но не мгновенные процессы уходят в pilot light, системы с прямым влиянием на выручку и обязательства — в warm standby. Active-active имеет смысл только там, где простой дороже постоянной сложности, а не потому что это «самый надёжный» пункт в таблице.
Главная ошибка — выбирать DR по названию стратегии, а не по цене простоя и способности команды поддерживать выбранный режим. Дешёвый вариант переносит работу в аварию. Быстрый вариант требует оплаченной инфраструктуры, дисциплины изменений и регулярных проверок заранее.
Пример минимального DR-плана для SMB
Матрица отвечает на вопрос «какую стратегию выбрать». Но в момент аварии команде нужна рабочая инструкция: что считать инцидентом, кто принимает решение, какие сервисы поднимать первыми, какие зависимости проверить и по каким признакам бизнес подтвердит восстановление.
Ниже — пример минимального DR-плана для SMB-компании, которая продаёт через сайт, ведёт сделки в CRM и принимает онлайн-платежи.
Исходные допущения для примера
Компания использует сайт или интернет-магазин в облаке, базу заказов и клиентов, CRM, корпоративную почту, файловое хранилище с договорами, внешний платёжный шлюз, SSO/IAM и DNS у отдельного провайдера.
Одна стратегия на всё не выбирается. Интернет-магазин и база заказов получают warm standby, потому что простой напрямую влияет на выручку. CRM работает по модели pilot light: менеджеры могут временно фиксировать заявки вручную, но долгий простой вредит продажам. Почта и файловое хранилище остаются на backup-only или штатной защите SaaS-провайдера, если бизнес допускает более длинное восстановление.
Платежи требуют отдельного внимания: часть контура находится у внешнего провайдера, поэтому в плане нужны контакты поддержки, ключи, разрешённые адреса и проверка тестовой оплаты.
Критерии запуска DR-сценария
DR-план не должен запускаться из-за каждого короткого сбоя. Для примера критерии могут быть такими:
- Основной сайт или база заказов недоступны более 15 минут, а прогноз восстановления неизвестен;
- Облачный регион, зона доступности или ключевая сеть недоступны, и провайдер подтверждает массовый инцидент;
- Данные повреждены или зашифрованы, требуется восстановление из чистой точки;
- Недоступность сервиса нарушает клиентские обязательства или блокирует приём заказов;
- Технический руководитель инцидента и бизнес-владелец сервиса согласовали запуск DR.
Решение лучше не оставлять одному инженеру. В минимальном варианте его принимает пара: технический руководитель инцидента и бизнес-владелец затронутого сервиса.
Приоритет 1. Доступ команды к облаку и DR-инструментам
Сначала команда должна получить доступ к тем инструментам, через которые будет восстанавливаться среда: облачному аккаунту, DNS-панели, менеджеру секретов, мониторингу, документации и контактам провайдеров.
Целевой RTO для этого слоя — 15–30 минут. RPO здесь не применяется, потому что речь не о данных, а о возможности управлять восстановлением.
Критерий успеха простой: команда вошла в облако не через упавший SSO, может менять DNS, сеть, секреты и открыть актуальную инструкцию.
Приоритет 2. База заказов и клиентов

База заказов и клиентов получает warm standby, потому что от неё зависят продажи, статусы заказов и обязательства перед клиентами. Целевой RTO — 30–60 минут, RPO — 5–15 минут.
При аварии команда проверяет реплику, целостность данных, ключи шифрования, сеть и секреты. Если реплика повреждена, нужно восстановиться из чистой точки. После этого приложение переводят на резервную базу.
Критерий успеха: последние заказы видны, приложение подключается к резервной базе, данные не выглядят повреждёнными или неполными.
Приоритет 3. Интернет-магазин
Интернет-магазин тоже работает по модели warm standby. Целевой RTO — до 60 минут, RPO по заказам — 5–15 минут.
При аварии резервную среду масштабируют, проверяют конфигурации, DNS, сертификаты, CDN, базу товаров и подключение к платёжному контуру. Затем переключают DNS или балансировщик и выполняют тестовый заказ.
Критерий успеха: сайт открывается, заказ создаётся, уведомление уходит клиенту, а команда видит событие в системе.
Приоритет 4. Платежи
Платёжный контур защищается через warm standby для своей части инфраструктуры и отдельную процедуру с провайдером. Целевой RTO — до 60 минут. RPO зависит от того, как платёжный провайдер хранит и синхронизирует статусы операций.
При аварии нужно проверить API-ключи, сертификаты, разрешённые IP-адреса, доступность шлюза и контакты поддержки. Отдельно проверяется, разрешена ли резервная среда на стороне платёжного провайдера.
Критерий успеха: тестовая оплата проходит или статусы оплат корректно синхронизируются.
Приоритет 5. CRM
CRM можно вынести в pilot light, если менеджеры способны временно фиксировать заявки вручную. Целевой RTO — 2–4 часа, RPO — около 1 часа.
При аварии CRM разворачивают из подготовленного шаблона, подключают данные, проверяют SSO/IAM, почту, телефонию и интеграции с сайтом. Если восстановление задерживается, включается ручная фиксация заявок.
Критерий успеха: менеджеры входят в CRM, видят клиентов и сделки, а новые заявки не теряются.
Приоритет 6. Почта
Почта может оставаться на backup-only или штатной защите SaaS-провайдера, если бизнес допускает более длинное восстановление. Целевой RTO — около 4 часов, RPO зависит от провайдера.
При аварии проверяют статус провайдера, доступ администратора, DNS-записи, антиспам и работу уведомлений. Если нужно, переключают DNS или временно используют резервный канал связи.
Критерий успеха: входящая и исходящая почта работают, критичные уведомления доходят.
Приоритет 7. Файловое хранилище договоров
Файловое хранилище обычно можно восстанавливать позже, если оно не блокирует текущие продажи и исполнение договоров. Целевой RTO — один рабочий день, RPO — до 24 часов.
При аварии восстанавливают не всё хранилище сразу, а критичные папки: договоры, документы по текущим клиентам, файлы для операций и поддержки. Затем проверяют права доступа, SSO/IAM, ключи шифрования и VPN.
Критерий успеха: ответственные отделы открывают нужные документы и понимают, какие данные будут восстановлены позже.
Минимальный DR-план не обязан быть большим документом, но он должен связывать техническое восстановление с бизнес-проверкой. Если после переключения никто не проверил создание заказа, вход менеджера в CRM и прохождение платежа, сервис нельзя считать восстановленным только потому, что серверы «зелёные».
Порядок восстановления по шагам
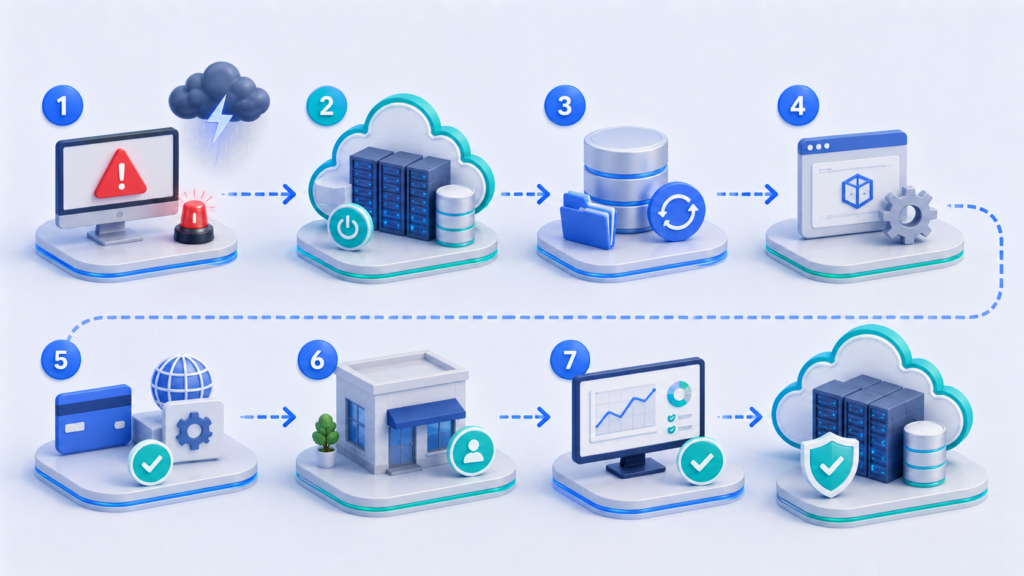
Приоритеты показывают, что восстанавливать первым. Но в аварии нужен ещё и линейный сценарий: кто открывает инцидент, кто принимает решения, кто переключает трафик и кто подтверждает, что бизнес-функция снова работает.
- Зафиксировать инцидент и открыть общий канал связи. Отдельный чат или конференция (war room) нужны для IT, бизнеса и руководителя инцидента. Сразу фиксируется, где хранится текущий статус и кто даёт внешние комментарии.
- Назначить руководителя инцидента. Иногда встречается термин "владелец инцидента". Он координирует восстановление: кто занимается облаком, кто связывается с провайдерами, кто сообщает бизнесу статус и кто принимает решение о переключении.
- Проверить аварийные доступы. Команда должна войти в облако, DNS-панель, менеджер секретов, мониторинг и аккаунты провайдеров. Эти доступы не должны зависеть только от SSO, который может быть частью инцидента.
- Остановить ухудшение ситуации. При подозрении на повреждение или шифрование данных нельзя восстанавливать поверх основной среды. Нужно изолировать ресурсы, сохранить логи и определить чистую точку.
- Восстановить данные самого критичного сервиса. В примере это база заказов и клиентов. Проверяются актуальность реплики, целостность данных и подключение приложения.
- Поднять или масштабировать резервное приложение. Для warm standby резервную среду увеличивают до рабочего размера. Для pilot light приложение разворачивают из подготовленных шаблонов. Для backup-only среду собирают по инструкции.
- Проверить зависимости. DNS, сертификаты, секреты, ключи API, маршруты, VPN, права доступа, интеграции с банком, почтой и CRM. Именно здесь часто теряется реальное RTO.
- Переключить трафик. Команда меняет DNS, балансировщик или маршрутизацию. В плане должен быть указан человек, который имеет право сделать это действие, и способ отката.
- Выполнить техническую и бизнес-проверку. Техническая проверка показывает, что приложение отвечает, база доступна, логи не содержат критичных ошибок, мониторинг видит резервную среду. Бизнес-проверка подтверждает, что заказ создаётся, платёж проходит, клиент получает уведомление, а менеджер видит заявку.
- Сообщить статус бизнесу и клиентским командам. Продажи, поддержка и руководство должны понимать, какие функции уже работают, какие данные могут быть неполными и когда будет следующий апдейт.
- После стабилизации провести разбор. Команда фиксирует, что сработало, что задержало восстановление, какие доступы или зависимости забыли и какие RTO/RPO оказались нереалистичными.
Такой порядок не заменяет технические инструкции, но удерживает команду от хаоса. В аварии важно не только «починить», но и не потерять управление: кто решает, кто делает, кто проверяет и кто сообщает статус.
Ответственные и контакты

В небольшом бизнесе роли часто совмещаются, но в DR-плане они всё равно должны быть названы. Если указать просто «IT», в момент аварии начнётся выяснение, кто меняет DNS, кто звонит провайдеру, а кто подтверждает, что CRM можно отдавать менеджерам.
Минимальный набор ролей:
- Руководитель инцидента — координирует восстановление, ведёт статус, принимает технические решения в рамках плана;
- Бизнес-владелец сервиса — подтверждает критичность, согласует запуск DR и проверяет бизнес-функцию;
- Облачный инженер или инженер эксплуатации — поднимает резервную среду, сеть, балансировщики и маршруты;
- Администратор данных или DBA — отвечает за базу, репликацию, копии и проверку целостности;
- Системный администратор — отвечает за доступы, SSO/IAM, почту, файловое хранилище и права пользователей;
- Финансовый ответственный — проверяет платежи, сверку статусов, связь с банком или платёжным провайдером;
- Ответственный за коммуникации — сообщает статус руководству, продажам, поддержке и, при необходимости, клиентам и PR-службе.
Рядом с ролями должны быть контакты: телефон, резервный мессенджер, почта, аккаунт у облачного провайдера, номер договора, статус-страницы провайдеров, поддержка DNS, банка, платёжного шлюза и ключевых SaaS-сервисов.
Эти данные лучше хранить не только в основной корпоративной системе. Если сама система окажется недоступной, команда не должна терять инструкцию, контакты и аварийные доступы вместе с ней.
Как тестировать DR-план, чтобы он не остался гипотезой

DR-план без проверки — это гипотеза. Для SMB разумный минимум — тест восстановления раз в квартал для критичных сервисов и раз в полгода для менее критичных. Если инфраструктура часто меняется или клиентские SLA становятся жёстче, частоту лучше увеличить.
Тест не обязательно каждый раз должен быть полным переключением рабочей среды. Форматы можно чередовать: от спокойной проверки сценария до ограниченного переключения на резервную среду.
Настольная проверка сценария
Команда проходит DR-план по шагам и ищет пробелы до реальной аварии: кто принимает решение, где лежат контакты, какие доступы нужны, какие критерии запуска считаются достаточными.
Такой формат подходит для всех сервисов, особенно для почты, файлового хранилища, отчётности и менее критичных систем. Он помогает быстро понять, актуальны ли роли, контакты, инструкции и порядок восстановления.
Техническое восстановление в изолированной среде
Сервис поднимается из копии или реплики без переключения реальных пользователей. Это безопасный способ проверить, что бэкап действительно читается, приложение стартует, база подключается, а права и конфигурации не устарели.
Для критичных сервисов — интернет-магазина, базы заказов, платежей и CRM — такую проверку лучше проводить не реже раза в квартал. Важно фиксировать фактические RTO/RPO, ошибки инструкций, недостающие доступы и проблемы с зависимостями.
Частичный тест зависимостей
Иногда проблема не в данных и не в приложении, а в окружении. Поэтому отдельно стоит проверять аварийные доступы, DNS-процедуру, сертификаты, секреты, маршруты, VPN, доступ к платёжному провайдеру и статус-страницы внешних сервисов.
Такой тест полезен даже без восстановления приложения. Он показывает, сможет ли команда в принципе управлять аварийной средой, если основной SSO, сеть или корпоративная документация окажутся недоступны.
Полноценное учение
Самый близкий к реальности вариант — тестовый или ограниченный контур переключается на резервную среду с технической и бизнес-проверкой. Команда не просто поднимает серверы, а проверяет сценарий целиком: заказ создаётся, платёж проходит, уведомление уходит клиенту, менеджер видит заявку в CRM.
Полное учение не обязательно проводить часто, но для сервисов с высоким RTO/RPO и клиентскими обязательствами оно особенно ценно. Именно оно показывает, насколько план совпадает с реальной скоростью восстановления.
После любого теста нужно фиксировать не только факт проверки, но и результат: фактическое время восстановления, потерю данных, ошибки инструкций, недостающие доступы, проблемы с DNS, сертификатами, секретами, интеграциями и ручными согласованиями.
Тесты нужны не «для галочки», а чтобы сравнить обещанный DR и RTO/RPO с реальностью. Если план обещает восстановление интернет-магазина за час, а тест занял три часа из-за DNS, секретов и ручных согласований, это не провал. Это полезное обнаружение реальности до настоящей аварии.
Заключение

Для SMB Disaster Recovery в облаке — это не поиск «самой надёжной» схемы, а выбор разумного компромисса между ценой простоя, допустимой потерей данных, бюджетом и возможностями команды. Backup-only, pilot light, warm standby и active-active отличаются не только скоростью восстановления, но и постоянной стоимостью, сложностью эксплуатации и требованиями к тестированию.
Практичный DR начинается с RTO/RPO для конкретных сервисов и заканчивается проверяемым планом: приоритеты восстановления, зависимости, ответственные, контакты провайдеров, критерии запуска и регулярные тесты. Если план не проверялся, он остаётся предположением. Если проверялся — бизнес получает не просто бэкапы, а понятный сценарий возврата к работе.
FAQ
Чем Disaster Recovery отличается от обычных бэкапов?
Бэкап отвечает за сохранение данных и точку возврата. Disaster Recovery шире: он описывает, как восстановить приложение, сеть, доступы, DNS, сертификаты, интеграции и сам бизнес-процесс.
Если есть только резервная копия, данные можно вернуть, но сервис всё равно может не заработать быстро. Для рабочего DR нужны порядок восстановления, ответственные, зависимости и проверка, что сервис снова выполняет бизнес-функцию.
Можно ли задать один RTO и RPO для всей компании?
Технически можно, но практически это почти всегда ошибка. У CRM, интернет-магазина, почты, платежей и файлового архива разная цена простоя и разная допустимая потеря данных.
Лучше задавать RTO и RPO по сервисам. Так компания не переплачивает за защиту некритичных систем и не экономит там, где простой сразу влияет на продажи, поддержку клиентов или договорные обязательства.
Когда SMB достаточно backup-only?
Backup-only подходит для систем, простой которых не блокирует текущие операции: архивов, отчётности, некритичных файловых хранилищ, тестовых сред и сервисов, которые бизнес готов восстанавливать дольше.
Для базы заказов, платежей, операционной CRM, клиентского кабинета или интернет-магазина одного backup-only часто недостаточно. Данные можно восстановить, но реальное RTO может сорваться из-за ручной настройки сети, доступов, DNS, сертификатов, секретов и интеграций.
В чём разница между pilot light и warm standby?
При pilot light в облаке заранее подготовлено резервное ядро: сеть, шаблоны инфраструктуры, минимальные базы или реплики, ключевые конфигурации. Во время аварии это ядро разворачивают до рабочего масштаба и переключают трафик.
При warm standby резервная среда уже постоянно запущена, но обычно в меньшем размере. Она получает актуальные данные, проходит мониторинг и при аварии масштабируется до основного режима. Такой вариант быстрее, но дороже и сложнее в эксплуатации.
Как понять, что DR-план действительно работает?
DR-план нужно регулярно тестировать. Для критичных сервисов разумный минимум — проверка раз в квартал, для менее критичных — раз в полгода. Формат может быть разным: настольная проверка сценария, восстановление в изолированной среде, частичный тест зависимостей или полноценное учение.
Рабочим план можно считать только после проверки фактических RTO/RPO, аварийных доступов, DNS-процедур, сертификатов, секретов, интеграций и бизнес-сценариев. Если после переключения заказ создаётся, платёж проходит, CRM открывается, а ответственные понимают следующий шаг, DR-план ближе к реальности, а не к предположению.
Список источников
1. AWS — Disaster Recovery of Workloads on AWS: Recovery in the Cloud
2. Microsoft Azure — What are business continuity, high availability, and disaster recovery?
3. Google Cloud — Disaster recovery planning guide
4. NIST SP 800-34 Rev. 1 — Contingency Planning Guide for Federal Information Systems


