
Cloud Landing Zone — это заранее подготовленный фундамент для безопасного запуска проектов в облаке. Не просто набор серверов, сетей и аккаунтов, а базовая среда, где уже продуманы доступы, изоляция окружений, логирование, бюджетные ограничения, политики безопасности и правила для команды.
В 2026 году landing zone особенно важна для SMB и среднего бизнеса, потому что облако стало проще запустить, но сложнее контролировать. Один общий аккаунт, ручная настройка сетей, доступы «всем ко всему» и отсутствие централизованных логов быстро превращают удобную облачную инфраструктуру в хаос.
Минимальная Cloud Landing Zone должна отвечать на несколько вопросов:
- Где живут prod, stage и dev;
- Какие аккаунты или проекты нужны команде;
- Кто и к каким ресурсам имеет доступ;
- Какие действия запрещены политиками;
- Где собираются логи и события аудита;
- Как контролируются бюджеты, лимиты и теги;
- Какие сетевые зоны доступны извне, а какие закрыты;
- Что нельзя создать вручную без проверки и согласования.
Для небольшой компании landing zone не обязана быть сложной. На старте достаточно разделить рабочие среды, настроить базовые роли доступа, включить централизованные логи, поставить бюджетные лимиты и запретить самые рискованные действия. Например, создание публичных хранилищ, выдачу лишних прав администратора или запуск ресурсов без тегов.
Дальше разберём, из каких частей состоит Cloud Landing Zone, как она может выглядеть для SMB и среднего бизнеса, какие guardrails стоит включить на старте и какие ошибки чаще всего превращают облако в неуправляемую инфраструктуру.
Почему облако лучше готовить до запуска первых проектов

Облако часто начинают использовать слишком просто: зарегистрировали аккаунт, создали виртуальную машину, подключили базу данных, открыли доступ команде — и вроде бы всё работает. Для тестового проекта такой подход может выглядеть нормальным. Проблемы начинаются позже, когда в облаке запускается продакшен, появляется несколько команд и проектов, внешние пользователи, персональные данные, интеграции, подрядчики и ежемесячные счета.
Cloud Landing Zone нужна до запуска проектов, потому что она задаёт правила игры заранее. Не после первой аварии, не после случайно открытого наружу хранилища и не после счёта, который оказался в два раза выше ожидаемого. Она помогает сразу понять, где будут жить разные окружения, кто сможет управлять ресурсами, какие действия запрещены, где искать логи и как не потерять контроль над расходами.
Проще всего представить landing zone как подготовленную площадку под строительство. Можно сразу начать ставить дом на пустом участке, а потом думать про дорогу, электричество, забор, канализацию и охрану. Но чем дальше зашло строительство, тем дороже исправлять ошибки. В облаке похожая история: если сначала хаотично создать аккаунты, сети, роли и сервисы, то потом их придётся разбирать уже "на живую", с работающими системами.
Для SMB и среднего бизнеса это особенно важно. У небольшой команды часто нет отдельного большого отдела безопасности, FinOps-команды и нескольких cloud-архитекторов. Поэтому landing zone должна не усложнять жизнь, а наоборот — снижать количество ручных решений.
Разница между запуском облака без landing zone и с подготовленным базовым контуром выглядит так:
| Что происходит без landing zone | Что даёт landing zone |
| Все ресурсы создаются в одном аккаунте | Окружения и проекты разделены заранее |
| Доступы выдаются вручную и «на всякий случай» | Роли и права описаны понятной моделью |
| Сети настраиваются по мере необходимости | Сетевая схема продумана до запуска сервисов |
| Логи лежат в разных местах или не собираются | Аудит и события уходят в единый контур |
| Расходы сложно связать с проектами | Бюджеты, теги и лимиты включены с начала |
| Ошибки замечают после инцидента | Опасные действия блокируются guardrails |
Главная задача landing zone — сделать так, чтобы облако росло управляемо. Сначала появляется не набор случайных ресурсов, а понятный каркас: аккаунты, сети, доступы, политики, логи и финансовые ограничения. Уже на этот каркас можно переносить приложения, запускать новые сервисы и подключать команды.
Что такое Cloud Landing Zone простыми словами
Теперь можно поговорить об определениях. Если коротко, Cloud Landing Zone — это подготовленная облачная среда, в которую можно безопасно «приземлять» первые проекты. Отсюда и название: landing zone, то есть зона посадки.
Это не один конкретный сервис и не кнопка в панели провайдера. Скорее, это набор заранее принятых решений: как разделять окружения, кто управляет доступами, где проходят сетевые границы, какие действия запрещены, куда уходят логи и как контролируются расходы.
Без landing zone команда каждый раз решает эти вопросы заново. Один разработчик создаёт тестовую сеть как удобно ему. Второй выдаёт доступ подрядчику напрямую. Третий запускает базу данных без тегов, потому что «потом подпишем». Через несколько месяцев уже сложно понять, какие ресурсы кому принадлежат, почему счёт вырос и где искать следы конкретного действия.
Landing zone нужна, чтобы базовые правила не зависели от случайных решений отдельных людей. Она задаёт общий порядок ещё до того, как в облаке появятся десятки серверов, баз данных, хранилищ и интеграций.
Проще всего разложить Cloud Landing Zone на несколько уровней:
| Уровень landing zone | За что отвечает |
| Организационный | Аккаунты, проекты, окружения, владельцы ресурсов |
| Сетевой | VPC/VNet, подсети, маршруты, доступ в интернет и между сервисами |
| Доступы | IAM-роли, группы, права администраторов, доступ подрядчиков |
| Безопасность | Guardrails, запреты, политики регионов, шифрование, контроль публичности |
| Наблюдаемость | Логи, аудит, события безопасности, мониторинг |
| Финансы | Бюджеты, лимиты, теги, распределение затрат по проектам |
То есть landing zone — это не «ещё одна сложная облачная штука». Это способ заранее ответить на вопросы, которые всё равно появятся позже: где будут жить проекты, кто получит доступ, как разделить окружения, куда складывать логи и как не потерять контроль над расходами.
Поэтому дальше стоит начать не с выбора виртуальных машин или баз данных, а с базовых архитектурных решений. До создания первых серверов нужно понять, как компания будет делить аккаунты, окружения и общие сервисы.
Что нужно решить до создания первых серверов

Перед запуском первых ресурсов в облаке хочется сразу перейти к практике: создать виртуальную машину, базу данных, хранилище, балансировщик и начать перенос приложения. Но для landing zone важнее другой порядок. Сначала компания решает, как будет устроена сама облачная среда, а уже потом размещает внутри неё сервисы.
Иначе получается ремонт двигателя на ходу. Приложение уже работает, пользователи уже есть, команда уже зависит от инфраструктуры, а базовые вопросы всё ещё открыты: где продакшен, где тестовая среда, кому принадлежит сеть, кто может менять IAM-роли и почему ресурсы разных проектов лежат в одном месте.
До создания первых серверов нужно понять три вещи: как делить аккаунты и проекты, где провести границы между prod, stage и dev, а также какие общие сервисы вынести в отдельный слой. Эти решения задают основу landing zone и помогают не смешивать рабочие системы, тесты, эксперименты и административные инструменты в одном месте.
Как разделить аккаунты, проекты и окружения
В landing zone аккаунт или проект (в зависимости от терминологии провайдера, не путать с пользовательскими аккаунтами) лучше воспринимать не как формальность в панели провайдера, а как границу ответственности. В одном аккаунте может жить продакшен, в другом — тестовая среда, в третьем — общие сервисы, в четвёртом — песочница для экспериментов.
Для небольшой компании не всегда нужна сложная многоуровневая структура. Но один общий аккаунт для всего — плохая точка старта. В нём быстро смешиваются реальные данные, тестовые ресурсы, временные эксперименты, доступы подрядчиков и счета за разные направления.
Базовая логика может быть такой:
- Prod — рабочие сервисы, реальные данные, критичные базы и хранилища;
- Stage — предрелизная среда для проверки изменений перед продакшеном;
- Dev — среда разработки, тестовые ресурсы и временные сервисы;
- Shared services — или иногда инфраструктурные\прикладные сервисы - общие инструменты: логи, CI/CD, VPN, DNS, мониторинг;
- Sandbox — эксперименты, обучение и проверка новых облачных сервисов.
Такое разделение помогает не только безопасности. Оно упрощает расходы, аудит и сопровождение. Если счёт вырос, проще понять, где именно это произошло. Если нужно ограничить доступ подрядчику, его не приходится пускать в общий аккаунт со всем бизнесом сразу.
Но одних аккаунтов и проектов мало. Важно ещё понять, какие задачи внутри них относятся к рабочей системе, какие — к проверке релизов, а какие — к разработке. Поэтому следующий шаг — разделить prod, stage и dev не только по названиям, но и по реальным правилам.
Где провести границы между prod, stage и dev
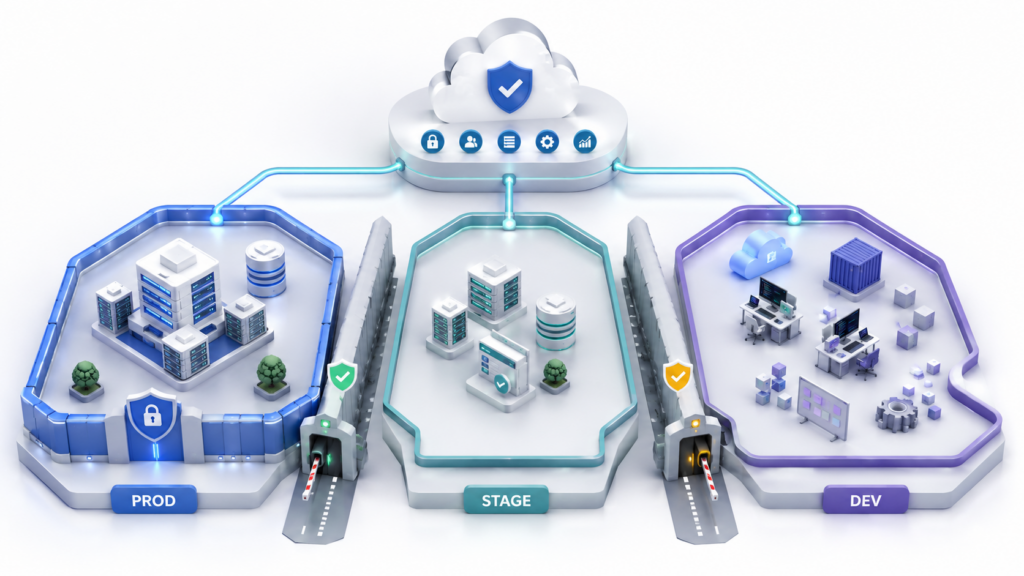
Prod, stage и dev не должны отличаться только названием ресурсов или тегами. Между ними нужны реальные границы: отдельные аккаунты или проекты, разные права доступа, разные сетевые правила и разные требования к данным.
Prod — это зона, где ошибка стоит дороже всего. Здесь нужны строгие права, централизованные логи, резервное копирование, контроль изменений и минимальное количество людей с административным доступом.
Stage нужен для проверки изменений перед релизом. Он может быть похож на prod по архитектуре, но не должен хранить реальные данные без необходимости. Dev остаётся более свободной средой, где команда может быстрее тестировать гипотезы, но даже там нужны лимиты, теги и базовые ограничения.
Когда окружения разделены, остаётся ещё один вопрос: куда вынести инструменты, которые нужны всем проектам сразу. Логи, VPN, DNS, мониторинг и CI/CD не стоит дублировать в каждом аккаунте, поэтому для них обычно делают отдельный слой shared services.
Какие общие сервисы вынести в shared services
Shared services — это общий слой landing zone. В него выносят инструменты, которые нужны не одному конкретному приложению, а всей облачной среде. Такой слой помогает не собирать одни и те же вещи заново для каждого проекта.
Обычно туда попадают инфраструктурные сервисы, которые отвечают за управление, безопасность, доступ и наблюдаемость. Но shared services не должен превращаться во второй общий аккаунт «для всего подряд». Там должны жить именно общие функции, а не случайные базы данных, тестовые серверы и забытые временные ресурсы.
Минимальный набор shared services для SMB может выглядеть так:
| Сервис | Зачем нужен |
| Централизованные логи | Единый сбор событий из prod, stage, dev и общих сервисов |
| VPN или bastion-доступ | Безопасный административный доступ без открытия интерфейсов в интернет |
| DNS и базовая сеть | Управление общими маршрутами, доменами и именами сервисов |
| CI/CD или registry | Единая сборка, хранение артефактов и доставка приложений |
После разделения аккаунтов, окружений и общих сервисов появляется каркас landing zone. Но сам по себе он ещё не защищает облако. Дальше нужно настроить то, что будет удерживать этот каркас: сеть, доступы и политики.
Базовый каркас landing zone: сеть, доступы и политики

Сеть и сегментация: чтобы сервисы не жили в одной комнате
Сеть в landing zone нужна не только для связи между сервисами. Она задаёт границы: что доступно из интернета, что видно только внутри облака, какие сервисы могут обращаться к базам данных, а какие вообще не должны знать об их существовании.
Если сеть строится вручную по мере роста проекта, она быстро превращается в набор временных решений. Сегодня открыли доступ для теста, завтра забыли закрыть, через месяц никто уже не помнит, зачем это правило появилось. Поэтому в landing zone сетевую модель лучше продумать заранее.
Для SMB и среднего бизнеса обычно достаточно простой логики:
- Публичная зона — балансировщики, API-шлюзы и сервисы, которым действительно нужен входящий доступ из интернета;
- Приватная зона — приложения, внутренние сервисы, очереди, backend-компоненты;
- Закрытая зона данных — базы данных, хранилища, кэши и другие чувствительные сервисы;
- Административный доступ — через VPN, bastion или другой контролируемый вход, а не напрямую по открытому SSH или RDP.
Главная идея сегментации простая: чем критичнее ресурс, тем меньше сервисов и людей должны иметь к нему прямой доступ. База данных не должна жить в той же «комнате», что и публичный веб-сервер. Административные интерфейсы не должны смотреть в интернет. Тестовая среда не должна иметь свободный путь к продакшен-данным.
Хорошей идеей будет и настройка Security Groups\ACL, с использованием функционально-ролевой модели - к каждому ресурсу с определенной ролью (балансировщик, сервер приложений, база данных и так далее) применяется определённый набор правил. Такой подход не заменяет, но дополняет разделение на зоны\сегменты.
Аналогично, заранее стоит продумать адресный план, чтобы сегментирование было прозрачным и понятным с точки зрения адресации - например сеть на облако это 10.0.0.0/8, сеть на проект\аккаунт - 10.х.0.0/16, Dev это всегда 10.х.1.0/24, а prod - 10.x.250.0/24.
После сетевых границ появляется следующий вопрос: даже если ресурс находится в правильной зоне, кто имеет право его создавать, менять и удалять.
IAM-роли и принцип минимальных прав
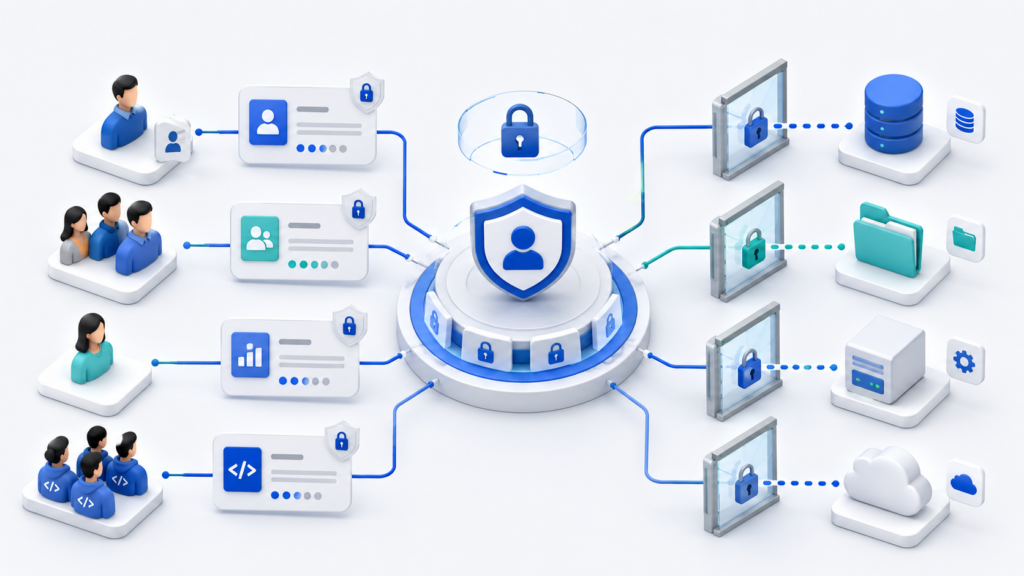
IAM — это система доступа в облаке. Через неё компания определяет, кто может создавать серверы, менять сетевые правила, читать логи, управлять базами данных, выпускать ключи и выдавать права другим пользователям.
Самая частая ошибка на старте — дать всем широкие права, потому что так быстрее. Команда маленькая, все друг друга знают, проект нужно запускать срочно. Но временный admin-доступ часто становится постоянным. Потом в облаке появляются подрядчики, новые сотрудники, несколько окружений и реальные данные, а права остаются такими, будто это всё ещё тестовый аккаунт на троих.
В landing zone доступы лучше строить не от конкретных людей, а от ролей:
| Роль | Что может делать |
| Cloud admin | Управляет базовой платформой, аккаунтами, сетями и политиками |
| Developer | Работает с ресурсами dev/stage в рамках проекта |
| Operator / SRE | Следит за эксплуатацией, логами, инцидентами и доступностью |
| Security | Проверяет политики, аудит, события безопасности и исключения |
| Finance / FinOps | Видит расходы, бюджеты, теги и отчёты по затратам |
Такой подход помогает не выдавать права «на всякий случай». Разработчику не всегда нужен доступ к продакшен-сетям. Финансовой команде не нужны права удалять серверы. Подрядчику не нужен полный доступ к аккаунту, если он работает только с одним сервисом в stage.
Хорошая IAM-модель не должна мешать работе. Её задача — сделать доступы предсказуемыми: человек получает ровно те права, которые нужны для его задачи, в нужном окружении и на понятный срок.
Для того, чтобы во время предоставлять и отзывать доступ новым и увольняющимся сотрудникам - хорошей идеей будет интеграция IAM c единым каталогом пользователей, например вроде Microsoft Active Directory или Entra.
Но даже аккуратные роли не закрывают все риски. Кто-то может ошибиться, создать ресурс без тегов, открыть хранилище наружу или запустить сервис в неподходящем регионе. Для таких случаев нужны guardrails.
Guardrails: ограничения, которые не дают сломать облако
Guardrails — это защитные ограничения внутри cloud landing zone. Они не заменяют IAM, сеть или мониторинг, а дополняют их. Если IAM отвечает на вопрос «кто что может делать», то guardrails отвечают на вопрос «что нельзя делать вообще или можно только при соблюдении условий».
Хороший guardrail работает как отбойник на дороге. Он не управляет машиной вместо водителя, но не даёт вылететь с трассы в опасном месте. В облаке такими «отбойниками» могут быть запреты на публичные хранилища, обязательное шифрование, ограничения по регионам, запрет ресурсов без тегов или блокировка слишком дорогих типов инстансов.
На старте не нужно пытаться закрыть все возможные сценарии. Для небольшой компании важнее включить несколько базовых ограничений:
- Запрет публичного доступа к хранилищам без отдельного согласования;
- Обязательные теги для проекта, владельца, окружения и центра затрат;
- Ограничение регионов, если данные не должны уходить за выбранную юрисдикцию;
- Запрет отключения логирования и аудита;
- Требование шифрования для баз данных, дисков и хранилищ;
- Бюджетные лимиты или алерты для dev, sandbox и экспериментальных проектов.
Guardrails особенно полезны там, где ошибка может быть незаметной. Открытый порт, ресурс без владельца, база без шифрования или забытый тестовый сервер не всегда ломают систему сразу. Но именно из таких мелочей потом появляются утечки, лишние расходы и сложные расследования.
Наблюдаемость и контроль затрат как часть фундамента

Сеть, IAM и guardrails задают правила внутри landing zone. Но правила мало помогают, если компания не видит, что происходит в облаке. Можно запретить часть опасных действий, разделить окружения и настроить роли, но всё равно пропустить подозрительную активность, внезапный рост расходов или ресурс, который давно никто не использует.
Поэтому наблюдаемость и контроль затрат нужно считать не дополнительными опциями, а частью базового фундамента. Логи, аудит, бюджеты и теги лучше включать сразу, пока облако ещё небольшое. Потом, когда проектов станет больше, собрать это задним числом будет сложнее.
Централизованные логи и аудит
Логи в landing zone нужны не только для разработчиков. Это источник ответов на простые, но критичные вопросы: кто создал ресурс, кто изменил сетевое правило, кто выдал права, откуда пришёл запрос, почему сервис стал недоступен и что происходило перед инцидентом.
Если логи лежат отдельно в каждом аккаунте или проекте, расследование быстро превращается в археологию. Команда открывает разные панели, сравнивает время событий, ищет доступы, вспоминает, кто что менял, и пытается собрать картину вручную.
В landing zone лучше сразу сделать единый контур логирования. События из prod, stage, dev и shared services должны уходить в централизованное хранилище или систему мониторинга. Доступ к этим логам нужно ограничить, а срок хранения — определить заранее.
Минимально стоит собирать:
- События управления ресурсами;
- Изменения IAM-ролей и политик;
- Сетевые события и попытки доступа;
- События безопасности;
- Логи критичных приложений;
- Действия администраторов и сервисных аккаунтов.
Особенно важно защитить сами логи от удаления и изменения. Если злоумышленник или ошибившийся администратор может легко стереть следы, аудит теряет смысл. Поэтому для логов часто настраивают отдельное хранилище, ограниченные права и политику хранения.
Когда события начинают собираться централизованно, появляется следующая задача: не только видеть технические изменения, но и понимать, во сколько обходится каждая часть облака.
Бюджеты, лимиты и финансовые guardrails

Одна из ловушек облака — ощущение, что ресурсы почти бесконечны. Сервер можно создать за минуту, базу данных — за несколько кликов, тестовый кластер — «только на вечер». Но счёт приходит не за намерения, а за реальные часы работы, диски, трафик, резервные копии, балансировщики и дополнительные сервисы.
Для SMB и среднего бизнеса это особенно чувствительно. Один забытый тестовый ресурс может быть не катастрофой для крупной корпорации, но неприятным ударом для небольшой команды. Поэтому контроль затрат должен быть частью landing zone, а не задачей бухгалтерии в конце месяца.
Базовые финансовые guardrails можно описать так:
| Механизм | Что помогает контролировать |
| Бюджетные алерты | Предупреждают о росте расходов до получения итогового счёта |
| Лимиты для dev и sandbox | Не дают экспериментам превращаться в дорогую инфраструктуру |
| Ограничение типов ресурсов | Снижает риск случайного запуска слишком дорогих инстансов |
| Отчёты по тегам | Показывают, какой проект, команда или среда создаёт расходы |
| Регулярная очистка ресурсов | Убирает забытые тестовые серверы, диски и временные сервисы |
Финансовые ограничения не должны блокировать нормальную работу команды. Их цель — вовремя показывать отклонения. Если dev-среда внезапно стала стоить почти как prod, это не всегда ошибка, но это точно повод проверить ситуацию.
Политика тегирования для ресурсов и расходов
Теги кажутся мелочью, пока ресурсов мало. Но как только в облаке появляются десятки серверов, дисков, баз, хранилищ и сетевых компонентов, без тегов становится сложно понять, кому что принадлежит.
Политика тегирования отвечает на несколько практических вопросов: какой это проект, кто владелец, к какому окружению относится ресурс, за какой центр затрат он отвечает и можно ли его удалить. Без такой информации инфраструктура постепенно превращается в склад коробок без подписей.
Для старта не нужно придумывать десятки тегов. Лучше выбрать небольшой обязательный набор и сделать его понятным для команды.
Например:
- Project — название проекта или продукта;
- Environment — prod, stage, dev или sandbox;
- Owner — команда или ответственный владелец;
- Cost_center — направление расходов;
- Managed_by — вручную, Terraform, CI/CD или другой способ управления.
Важно не просто описать теги в документе, а встроить их в правила landing zone. Ресурсы без обязательных тегов можно запрещать, помечать как нарушающие политику или регулярно выводить в отчёт на проверку.
Пример архитектуры Cloud Landing Zone для SMB и среднего бизнеса
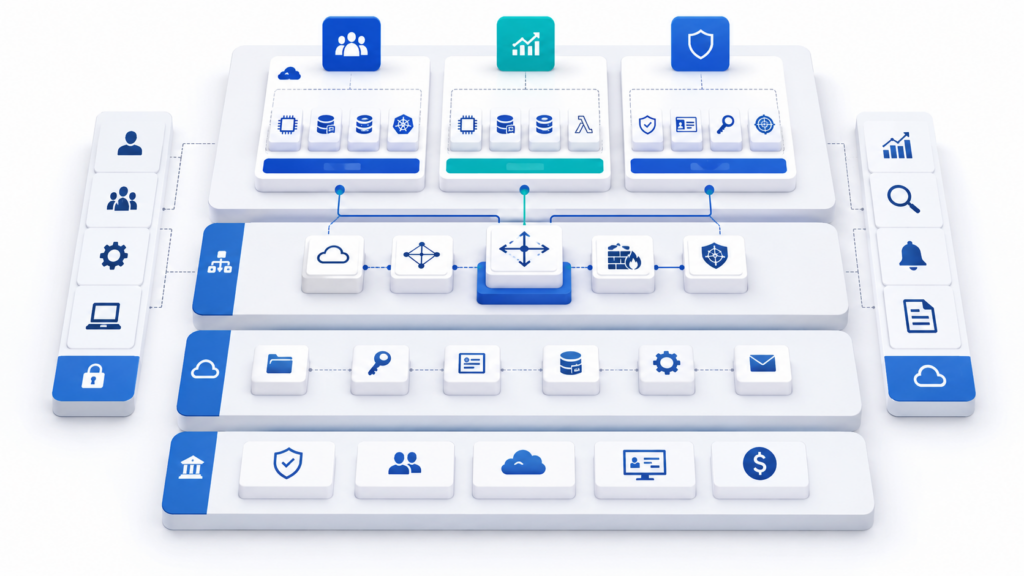
После базовых принципов полезно собрать всё в одну практическую схему. Не как идеальную архитектуру для корпорации с десятками команд, а как реалистичный вариант для SMB или среднего бизнеса: несколько проектов, небольшая команда, ограниченный бюджет, но уже есть продакшен, тестовые среды, внешние пользователи и требования к безопасности.
В такой модели landing zone должна быть достаточно простой, чтобы команда могла её сопровождать. Но при этом она должна сразу задавать границы: где рабочие сервисы, где эксперименты, кто управляет доступами, куда уходят логи и какие действия нельзя выполнить без контроля.
Как разложить аккаунты, окружения и shared services
Базовую архитектуру можно начать с нескольких отдельных аккаунтов или проектов. Их не обязательно должно быть много, но у каждого должна быть понятная роль. Главная ошибка — пытаться уместить всё в один общий аккаунт, потому что «пока маленькие». Именно из такого «пока» потом вырастают смешанные доступы, непонятные расходы и страх что-либо менять.
Для SMB можно использовать простую структуру:
| Аккаунт или проект | Что размещать |
| Prod | Рабочие приложения, реальные данные, критичные сервисы |
| Stage / Dev | Проверка релизов, разработка, тестовые ресурсы |
| Shared services | Логи, мониторинг, VPN, DNS, CI/CD |
| Sandbox | Эксперименты без доступа к критичным данным |
Такое разделение не требует сложной бюрократии, но сразу создаёт понятные границы. Prod не смешивается с тестами. Shared services не превращаются в склад случайных серверов. Sandbox можно ограничить по бюджету и правам, чтобы эксперименты не влияли на рабочие системы.
Внутри этой структуры важно назначить владельцев. У каждого проекта должен быть ответственный: команда, продуктовый владелец или технический лидер. Иначе даже правильная структура быстро превращается в набор ничьих ресурсов.
Как связать сеть, IAM, логи, бюджеты и guardrails
После разделения аккаунтов и окружений нужно связать их общими правилами. Иначе схема останется красивой только на бумаге, а каждый проект всё равно будет настраивать сеть, доступы, логи и бюджеты по-своему.
Сеть задаёт технические границы. Публичный доступ остаётся только у внешних точек входа: балансировщика, API-шлюза или веб-сервиса. Базы данных, внутренние сервисы и административные интерфейсы должны оставаться в закрытых зонах.
IAM отвечает за доступы. Права лучше выдавать по ролям, а не вручную каждому человеку. Разработчик работает с dev и stage, оператор — с эксплуатацией, security — с аудитом и политиками, а финансовая роль — с бюджетами и отчётами.
Логи и бюджеты делают landing zone видимой. Без логов сложно понять, кто изменил правило, выдал доступ или создал ресурс. Без бюджетов команда узнаёт о проблеме только после счёта. Поэтому события из всех окружений лучше сразу отправлять в общий контур, а для dev и sandbox включать лимиты или алерты.
Guardrails закрывают самые опасные сценарии: публичные хранилища, ресурсы без обязательных тегов, отключение аудита или запуск в неподходящем регионе. Это не замена инженерам, а страховка от ошибок, которые в облаке могут стоить слишком дорого.
В итоге landing zone работает как единая система: сеть ограничивает путь к ресурсам, IAM управляет доступами, логи показывают происходящее, бюджеты контролируют расходы, а guardrails не дают нарушить базовые правила.
Далее стоит поговорить о не менее важной части – типовых ошибках.
Типовые ошибки старта без landing zone

В структуре: один аккаунт, смешанные окружения и ручные сети
Самая частая ошибка — запускать всё в одном аккаунте или проекте. Там одновременно появляются prod, stage, dev, тестовые базы, временные серверы, доступы подрядчиков и забытые эксперименты. Пока ресурсов мало, это кажется удобным. Но чем больше облако, тем сложнее понять, где рабочая система, где тест, а где старый ресурс, который уже никто не трогает.
Вторая проблема — смешивание окружений. Если dev может обращаться к prod-данным, а stage использует те же сетевые правила, что и рабочая среда, ошибка в тесте может затронуть реальных пользователей. Окружения должны отличаться не только названием, но и правами, сетями, требованиями к данным и уровнем контроля.
Ручная настройка сетей усиливает этот хаос. Сегодня команда открыла порт для проверки, завтра добавила временное правило, потом разрешила доступ с нового адреса. Через несколько месяцев сетевые правила уже похожи на старый шкаф: вроде всё нужно, но никто не помнит, зачем именно.
Такие ошибки выглядят примерно так:
| Ошибка | Чем опасна |
| Один общий аккаунт | Смешиваются данные, доступы, расходы и ответственность |
| Prod, stage и dev без границ | Тестовые действия могут затронуть рабочую систему |
| Ручные сетевые правила | Появляются забытые доступы и неочевидные исключения |
Исправлять это после запуска сложнее, чем настроить заранее. Особенно если приложение уже работает, команда привыкла к старым доступам, а часть ресурсов нельзя просто перенести без простоя.
В управлении: плоские права, отсутствие логов, тегов и бюджетов
Вторая группа ошибок связана не с тем, где лежат ресурсы, а с тем, как ими управляют. На старте часто кажется, что проще дать всем admin-доступ и не тратить время на роли. Команда маленькая, доверие есть, задачи срочные. Но облако быстро растёт, люди меняются, появляются подрядчики и новые сервисы, а права остаются слишком широкими.
Плоская модель доступа опасна тем, что в ней почти нет защиты от случайности. Один человек может изменить сеть, удалить ресурс, открыть хранилище или выдать права дальше. Даже если никто не хотел навредить, цена ошибки становится слишком высокой.
Без централизованных логов команда теряет память. Нельзя быстро понять, кто поменял политику, когда появился публичный доступ, почему выросли расходы или откуда началась проблема. В момент инцидента приходится не расследовать по логам, а собирать историю по чатам и воспоминаниям.
Отсутствие тегов и бюджетов бьёт уже по управляемости. Ресурсы есть, счета есть, но непонятно, какой проект сколько потребляет и кто за это отвечает. Особенно неприятно это в dev и sandbox, где забытый тестовый сервер или диск может спокойно жить месяцами.
Минимальный набор управленческих правил лучше ввести сразу:
- Доступы выдаются по ролям, а не «всем всё»;
- Логи управления и безопасности собираются централизованно;
- У ресурсов есть обязательные теги проекта, окружения и владельца;
- Для dev, sandbox и экспериментов включены бюджетные алерты;
- Исключения по правам и политикам фиксируются, а не держатся в переписке.
Эти правила не делают облако идеальным. Но они убирают самые опасные слепые зоны: непонятные доступы, невидимые изменения, ничейные ресурсы и расходы, которые обнаруживаются слишком поздно.
После разбора ошибок становится понятнее, почему landing zone не нужно внедрять как огромный корпоративный проект. Для небольшой команды важнее начать с минимального управляемого контура и постепенно усиливать его по мере роста облака.
Как внедрять landing zone без перегруза для небольшой команды
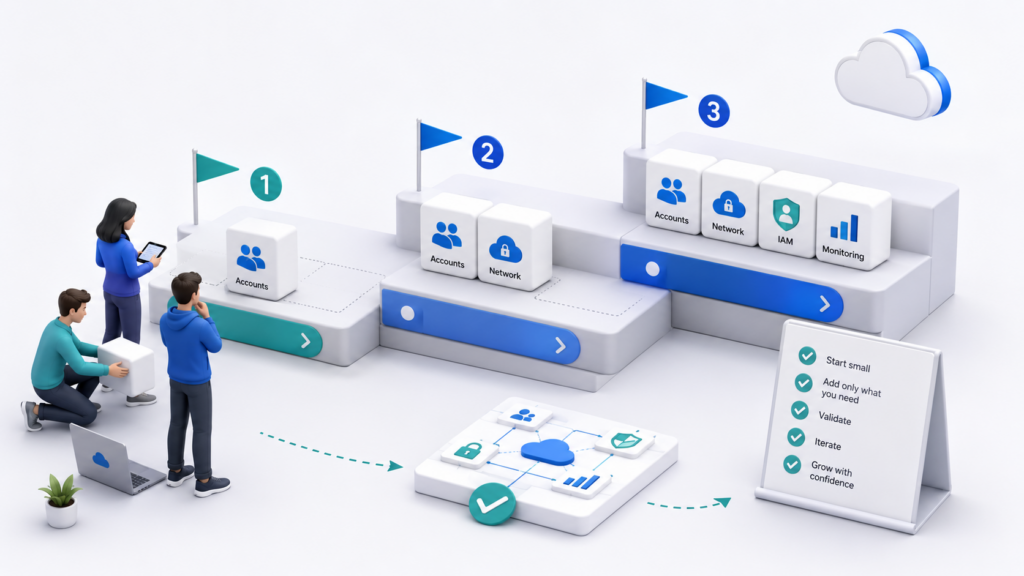
Cloud Landing Zone не обязательно внедрять как большой проект на полгода. Для небольшой команды такой подход даже вреден: архитектура может стать слишком тяжёлой ещё до того, как в облаке появятся реальные нагрузки. Лучше двигаться поэтапно и сначала закрыть самые заметные риски.
Хороший старт — минимальный базовый контур. Сначала команда разделяет prod, stage, dev и shared services. Затем настраивает базовые роли доступа, включает централизованные логи, добавляет обязательные теги и бюджетные алерты. После этого можно вводить guardrails: запрет публичных хранилищ, ограничение регионов, обязательное шифрование и контроль ресурсов без владельца.
Условно внедрение можно разделить на три этапа:
- Собрать основу. Разделить prod, stage, dev и shared services, назначить владельцев проектов и убрать критичные ресурсы из общего аккаунта.
- Добавить управляемость. Настроить IAM-роли, централизованные логи, обязательные теги и бюджетные алерты.
- Усилить защиту. Включить guardrails, ограничить публичный доступ, закрепить регионы, добавить шифрование и постепенно переносить настройки в IaC.
Автоматизацию тоже можно вводить постепенно. Например, сначала описать через Terraform базовую сеть и аккаунты, потом IAM-роли, затем политики и guardrails. Главное — не оставлять критичные настройки только в ручном виде. Если landing zone нельзя воспроизвести, проверить и повторить, она со временем начнёт расходиться с документацией.
Для SMB и среднего бизнеса нормальная цель — не построить «как у hyperscaler в референсной архитектуре», а создать понятный фундамент.
Заключение

Cloud Landing Zone — это не отдельный модный слой поверх облака, а способ заранее договориться о базовых правилах. Где живут prod, stage и dev, кто получает доступ, как устроена сеть, куда уходят логи, какие расходы допустимы и какие действия запрещены политиками.
Для SMB и среднего бизнеса landing zone особенно важна потому, что небольшая команда не всегда может компенсировать хаос ручным контролем. Если всё держится на памяти одного инженера, временных доступах и настройках «как получилось», облако быстро становится трудным для сопровождения.
Хорошая landing zone не обязана быть сложной. Её задача — дать компании безопасный старт: разделить окружения, ограничить лишние права, включить логи, настроить бюджеты, закрепить теги и добавить guardrails против самых рискованных ошибок.
FAQ
Можно ли запускать облако без landing zone?
Можно, особенно если речь о коротком тесте или прототипе без реальных данных. Но для рабочего проекта такой подход быстро создаёт риски: смешанные окружения, лишние права, непонятные расходы и отсутствие нормального аудита.
Если проект планируется развивать, лучше подготовить хотя бы минимальную landing zone до запуска продакшена.
Нужна ли landing zone малому бизнесу?
Да, но она не должна быть такой же сложной, как у крупной корпорации. Малому бизнесу обычно достаточно базовой структуры: отдельные окружения, понятные IAM-роли, централизованные логи, теги, бюджетные алерты и несколько обязательных guardrails.
Чем landing zone отличается от обычной облачной архитектуры?
Обычная облачная архитектура описывает конкретное приложение: серверы, базы данных, балансировщики, очереди, хранилища и связи между ними.
Landing zone описывает среду, в которой эти приложения будут запускаться. Она отвечает за аккаунты, сети, доступы, политики, логи, бюджеты, теги и общие правила безопасности.
Можно ли сделать landing zone постепенно?
Да, и для небольшой команды это часто лучший вариант. Сначала можно разделить prod, stage и dev, затем настроить IAM и логи, потом добавить теги, бюджеты, guardrails и автоматизацию через IaC.
Главное — не откладывать базовые решения до момента, когда в облаке уже десятки ресурсов и несколько критичных сервисов.
Что важнее на старте: IAM, сеть или логи?
Их лучше не рассматривать отдельно. Сеть ограничивает технический доступ к ресурсам, IAM определяет права людей и сервисов, а логи показывают, что реально происходит в облаке.
Если нужно расставить приоритеты, на старте стоит закрыть минимум: не открывать критичные ресурсы в интернет, не выдавать постоянный admin-доступ всем подряд и сразу включить аудит действий.
Нужно ли использовать Terraform или можно настроить всё вручную?
На самом старте часть настроек можно сделать вручную, если облако маленькое и команда только проверяет подход. Но критичные элементы landing zone лучше постепенно переносить в IaC: аккаунты, сети, IAM-роли, политики, guardrails и базовые сервисы.
Ручная настройка удобна один раз. Но если среду нужно повторить, проверить, восстановить или изменить без хаоса, инфраструктура как код становится намного надёжнее.
Список источников
3. Microsoft Azure Cloud Adoption Framework
4. Google Cloud Architecture Center
5. CIS Controls v8.1 и Cloud Companion Guide


