
Сегодня мы начинаем цикл статей про проектирование высоконагруженных информационных систем - да и вообще информационных систем в целом, ведь почти у любой системы есть шанс стать высоконагруженной. Начинать путь проектирования невозможно без фундаментальных основ и понятий. Поэтому, дисклеймер, – это не HowTo, который легко и просто можно применить к вашему приложению-инфраструктуре. Эта статья очень даже пригодится в формате ознакомления, для понимания базы.
Материал будет полезен для разработчиков и архитекторов, особенно для начинающих архитекторов ВНС, так как в нашей статье мы привязали тривиальную базовую информацию к высоконагруженными системами (ВНС) и системами реального времени (СРВ).
Все описанные ниже параметры непосредственно влияют на решения по проектированию программной архитектуры.
Роль данных и метаданных, питающих озера
В основе всех современных технологий лежат данные, метаданные и события. Их можно кратко описать следующими определениями:
Данные ― это фактическая получаемая от внутренних и внешних источников информация, которая используется для обработки, анализа и хранения.
В чем данные могут выражены: любая информация, от текстовых сообщений до изображений и видео.
Метаданные ― это данные о содержании других данных, которые используются для идентификации, сортировки, упрощения работы с большими объемами информации.
В чем данные могут выражены: время создания текстового файла, как и кем он был создан, его размер, тип, как он используется, какие были изменения и пр.
События ― это уведомления о действиях, которые происходят в системе. Они могут быть вызваны пользователем, приложением или другими компонентами системы.
Для чего используются: для мониторинга производительности, обнаружения ошибок, а также для обеспечения безопасности и контроля доступа.
Данные, метаданные и события отличаются друг от друга по своей природе и ролям, хотя и тесно связаны друг с другом. Так, данные могут создавать события, а события могут влиять на данные. Метаданные могут использоваться для отслеживания изменений в данных и событиях. Поэтому эти три элемента должны быть управляемыми и доступными в системе.
Без них уже невозможно представить современные технологии. Никакие. Высоконагруженные системы и системы реального времени также неисполнимы без них. Кроме того, обработка большого объема данных или событий от различных внутренних компонентов системы и внешних источников — основная причина нагрузки в высоконагруженных системах (ВНС) и системах реального времени (СРВ).
Для упрощения работы в СРВ события обычно разделяют на три типа:
- синхронные, здесь это предсказуемые события, происходящие с известной частотой. Например: сообщения, относящиеся к обмену и синхронизации данных. В общем контексте под синхронным типом понимается передача данных с подтверждением получения.
- асинхронные, здесь это абсолютно непредсказуемые события. Например: команды управления, тревоги, оповещения. В общем контексте под синхронным типом понимается передача данных без подтверждения получения.
- изохронные (разновидность асинхронных), здесь это регулярные события, происходящие в конкретный промежуток времени. Например: диагностические сообщения о состоянии компонентов системы.
По характеристикам и функционалу данные соотносят:
- либо с ВНС, где:
часть данных является вспомогательными. Они важны для функционирования системы, но остаются незаметны пользователям. Это могут быть данные транзакций, журналов событий, сенсоров и IoT, пользователей и т.д.
Зачастую достаточно обрабатывать данные подобного рода в режиме ВНС. Так, если текстовые переменные можно задать заранее и обмениваться их идентификаторами, то режим РВ можно не использовать.
- либо с СРВ, где:
отталкиваются в большей степени от того, нужно ли конкретно взятые данные обрабатывать в режиме РВ или нет, т.е. получается временная привязка. Также зачастую к реальному времени относят данные с высокой регулярностью использования. Это могут быть также данные транзакций, журналов событий или сенсоров и устройств IoT, но и ещё и данные мониторинга, управления, геолокации, видеонаблюдения и т.д.
Одна немаловажная деталь при обработке данных ― соблюдение баланса между объемом обрабатываемых данных РВ и метаданными. Если не оптимизировать их количество, могут появиться чрезмерные нагрузки. И уже они способны спровоцировать снижение эффективности всей системы, иногда даже при сохранении общей производительности - формируется так называемое "бутылочное горлышко", "узкое место" - когда один компонент системы не справляется с нагрузкой.
И еще один существенный момент: система по умолчанию не различает важность данных. Для того, чтобы она их определяла и разделяла, нужно заранее, при ее проектировании, закладывать соответствующие требования с разделением информации на важную, бесполезную и вспомогательную.
Способы обмена данными
Большое число узлов позволяет решить разнотипные задачи как в ВНС, так и в СРВ. На физическом уровне они могут быть представлены различными устройствами: рабочими станциями, серверами, умными устройствами интернета вещей, коммутаторами. Все они отличаются по неравномерности загрузки, доступности, непрерывности работы, что стоит учитывать при проектировании аппаратной инфраструктуры. Поэтому эту вариативность узлов в их физическом исполнении принято разделять на три типа:
Распределенные системы управления (РСУ), которые обеспечивают в том числе:
- эффективное управление распределенными ресурсами (вычислительная мощность, память, пропускная способность сети и т.д.),
- согласованную работу различных компонентов системы (управление потоком данных и сообщений, доступом к общим ресурсам, разрешение конфликтов и т.д.),
- распределенное хранение данных и управление ими в системе (репликация данных на различных узлах для отказоустойчивости, масштабируемости и быстрого доступа к данным),
- обработку данных и аналитику (может включать в себя инструменты для выполнения распределенных вычислений, обработки потоков данных, машинного обучения, аналитики и т.д.),
- балансировку нагрузки, что позволяет равномерно распределять нагрузку между узлами системы,
- отказоустойчивость и надежность.
Распределенные системы обслуживания (РСО), которые обеспечивают в том числе:
- управление запросами (включая прием запросов, их маршрутизация к соответствующим компонентам системы и контроль за процессом обработки запросов),
- возможность горизонтального и вертикального масштабирования системы для обработки большого количества запросов,
- балансировку нагрузки между различными узлами и компонентами системы, чтобы обеспечить равномерную загрузку и эффективное использование ресурсов,
- надежность и целостность выполнения транзакций (включая контроль над конкурентными доступами, обработку ошибок и восстановление после сбоев),
- отказоустойчивость (включает в себя резервное копирование данных, репликацию компонентов системы, механизмы восстановления после сбоев и обеспечение доступности сервисов при отказе отдельных узлов или компонентов),
- управление сеансами и состояниями для сохранения и восстановления состояния пользователей при переключении между различными компонентами системы,
- мониторинг и управление производительностью для выявления узких мест, оптимизации работы системы, управления ресурсами и обеспечения высокой производительности для пользователей.
Распределенные вычислительные системы (РВС), которые обеспечивают в том числе:
- распределенное хранение и обработку данных между различными узлами системы,
- горизонтальное и вертикальное масштабирование системы (позволяет адаптировать систему к меняющейся нагрузке и обеспечивает высокую производительность),
- распределение задач и нагрузки между узлами системы (включает механизмы маршрутизации запросов, динамического перераспределения задач и автоматической адаптации к изменяющейся нагрузке),
- управление задачами и расписанием в системе (включает планирование и распределение задач между узлами, контроль за выполнением задач и оптимизацию использования вычислительных ресурсов),
- обеспечение отказоустойчивости системы (может включать репликацию данных, дублирование узлов, механизмы резервного копирования и восстановления после сбоев),
- синхронизацию между узлами системы.
Конечно, перечисленный выше функционал систем может варьироваться в зависимости от конкретных требований и характеристик системы. Так, РВС и РСО в минимальной степени чем-то управляют (собственными вычислениями или обслуживанием потребителей), из-за чего их также можно причислять к РСУ. Поэтому допустим некоторое упрощение и, сведя все условно к одному, продолжим разговор про распределенные системы управления и эффективность взаимодействия между ее частями.
Итак, исходя из событийной модели, узлы РСУ могут быть связаны между собой и обмениваться сообщениями, для чего используются протоколы на уровнях TCP и UDP.
Но, так как технологии их работы различаются, то расходятся и фактические примеры их использования.
TCP
TCP — это, прежде всего, гарантированная доставка сообщений. Он считается в большей мере асинхронным unicast-протоколом (т.е. передача от одного источника к одному получателю), что говорит об отдельной обработке каждого TCP-соединения. Но за счёт дополнительной обвязки TCP даёт больше оверхеда, и обрабатывается медленнее в большинстве случаев.
TCP с большей вероятностью не подойдет для СРВ, причин несколько:
- В СРВ критична потеря времени на установление соединений. В противном случае при множестве соединений суммарное время на подключение возрастает, снижая эффективность работы системы.
- Кроме того, новые сообщения могут устаревать в пути, не дойдя еще до адресата. Но при управлении даже часть неактуальных данных может быть критична.
- На базе TCP сложнее сделать пул асинхронных сообщений и соответствовать асинхронному реальному миру.
- Если использовать TCP в режиме broadcast, могут возникать задержки из-за циркулирующих подтверждающих пакетов, провоцирующих излишнюю нагрузку.
UDP
UDP — это синхронный протокол, что позволяет ему работать с большей эффективностью благодаря режиму multicast (т.е. передача от одного источника к нескольким получателям) или broadcast (т.е. передача от одного источника ко всем возможным получателям). Примеры использования UDP: это медиа-потоки (где потеря не так важна, как скорость — вроде классического SIP), и где важен именно поток данных (syslog - протокол для доставки сообщений).
Что касается вопроса асинхронного режима, UDP-соединение также лучше показывает себя. Здесь возможно отслеживать диагностические сообщения, часть из которых содержит диагностические метрики. Из них можно получить показатели качества обмена сообщениями, такие как: показатели состояния отдельных компонентов и процессов, метрики подтверждения доставки сообщения с учетом указанных требований и т. д.
Однако все преимущества UDP не делают его единственно правильным решением. Выбор должен быть осознанным. Так, если важна доставка и целостность сообщений, то стоит вспомнить, что в TCP это реализовано в протоколе, а при использовании UDP придётся что-то изобретать.
Транзакции
Высоконагруженные системы и системы реального времени имеют свои границы допустимости. Так, в ВНС транзакции использоваться могут, а в СРВ — нет. Причину подсказывает само понятие транзакции.
Формальное определение такое: “упорядоченное множество операций, переносящих базу данных из одного согласованного состояния в другое”. Но если простыми словами — это группа операций, объединенная в одну логическую единицу, которая считается выполненной только если были выполнены все операции в ней. Получается лозунг “Все или ничего”:) А хороший аналогия на практике — банковская транзакция, которая считается совершенной только если деньги списались и дошли.
Основа такого подхода стоит на наборе требований ACID, которые обеспечивают сохранность данных:
- Atomicity (атомарность), не допускающая промежуточные состояния — транзакция либо полностью выполнена, либо нет.
- Consistency (консистентность), поддерживающая согласованность данных фиксированием только полностью завершенных транзакций (EOT — end of transaction).
- Isolation (изолированность), не допускающая какого-либо воздействия на итоговый результат текущей транзакции от параллельно ей выполняющихся.
- Durability (надежность), отвечающая за сохранение изменений успешно завершенной транзакции, чтобы не произошло далее — сбои или другие проблемы на нижних уровнях.
Как сказано выше, такие условия больше соотносятся с ВНС, так как синхронность транзакций здесь выполнима в превалирующем числе случаев. Сами транзакции обрабатываются очередями. Для этого эффективно использовать все доступные ресурсы вычислительного оборудования.
Что же касается системы реального времени, непринятость использования синхронных транзакций объясняется логикой работы самой системы — начиная с трех узлов разбивается синхронность, и возникают каскадные или созависимые/цепные транзакции:
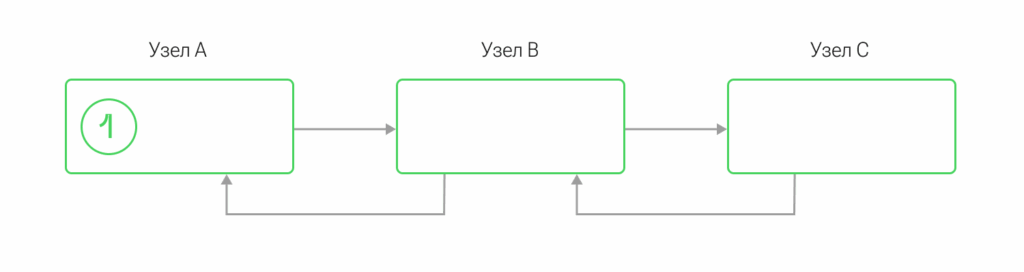
В этом случае узел А находится в ожидании, пока транзакция пройдет все узлы в один конец и вернется с результатом по той же траектории обратно, и только после этого транзакция будет считаться выполненной. Как результат, сразу появляются задержки и блокировки. И это только часть проблемы.
Если программная архитектура была спроектирована эффективно, можно компенсировать задержку ожидания выполнения сложных каскадных транзакций. Одним из решений может быть увеличение их количества. При этом стоит учитывать, что еще до завершения активной транзакции может стартовать обработка новых из очередей. Из-за этого каскадные транзакции могут частично на себя перенять свойства асинхронной обработки, в результате чего на инициаторов транзакции повлияют блокировки ожидания выполнения этих транзакций.
Подобная система может разрастаться сколь угодно далеко по своей длине.
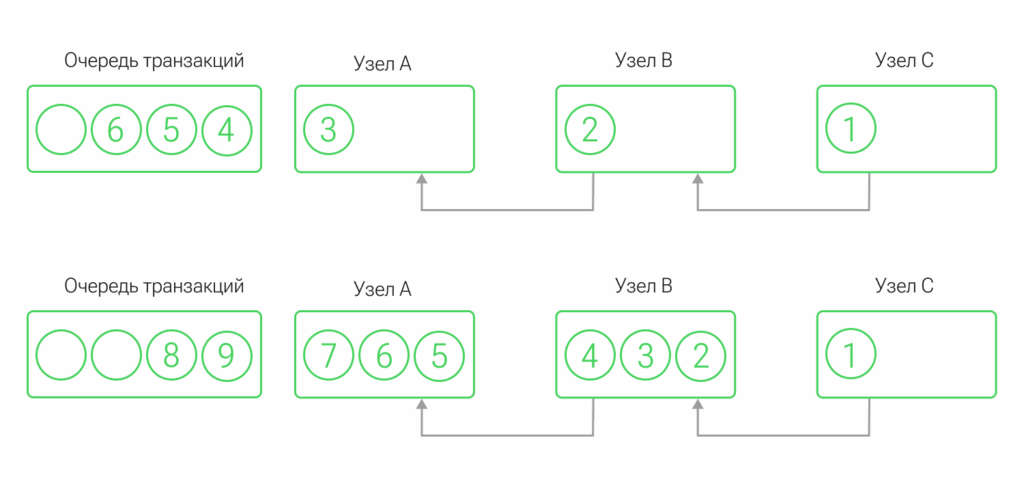
В итоге получается асинхронная обработка каскадных транзакций, в которой увеличивается среднее время обработки транзакции из-за того, что новая транзакция из очереди запускается до завершения предыдущей.
Такой процесс наравне с эффективностью может привести к дисбалансу из-за неопределенных заранее времени длительности блокировки и задержки. Все еще больше усугубляется, если целевая система работает не на жестко заданной логике, но идет за подвижным пользовательским поведением.
Что касается СРВ, здесь вместо традиционных транзакций часто используется модель идемпотентности. Она основана на принципе, что повторное выполнение операции с теми же входными данными не приводит к изменению состояния системы. Это означает, что даже если операция повторяется или выполняется несколько раз, результат будет один и тот же.
В СРВ события могут быть обработаны несколько раз из-за возможности дублирования, потери или повторной доставки сообщений. В таких случаях модель идемпотентности позволяет гарантировать корректность обработки событий.
На этом статья не заканчивается, а плавно переходит во вторую часть, где ещё обсудим распределенность, ограничения распределенных систем, единый формат данных, базовые операции с данными и особенности операций CRUD с данными в распределенных системах.